Clear Sky Science · zh
大型语言模型在牙科专科考试中的表现比较分析
为什么智能聊天机器人对未来牙医很重要
人工智能正在迅速改变医生和牙医的学习与工作方式。最引人注目的工具之一是由大型语言模型驱动的对话式聊天机器人——与许多流行的人工智能助手使用的是同类技术。本研究提出了一个既简单又重要的问题:如果牙科学生使用这些工具来准备竞争激烈的口腔颌面放射学专科考试,这些机器究竟能发挥多大作用?
在真实考试上测试 AI
为了解答这个问题,研究者选择了土耳其的牙科专科入学考试(DUS),该考试决定谁可以进入高级培训项目。他们从历年全国性试题中挑选了208道多项选择题,覆盖放射学专科医生必须掌握的主题,从辐射物理与成像技术到颌面肿瘤与鼻窦疾病。大多数题目仅包含文字,但有一小部分需要解释放射影像,模拟实际诊断工作。
七款聊天机器人接受同一挑战
研究团队随后将每道题以土耳其语分别输入到七款基于不同大型语言模型的常用 AI 聊天机器人中:两个版本的 ChatGPT,以及 Gemini、Copilot、DeepSeek、Claude 和 Grok。每道题都小心且单独录入,以避免会话间信息迁移。第二位研究者将每个 AI 的答案与官方答题卡比对,并判定为正确或错误。最后,作者使用标准统计检验比较模型的总体表现及各个专题领域内的差异。
谁得分最高——以及他们的薄弱环节
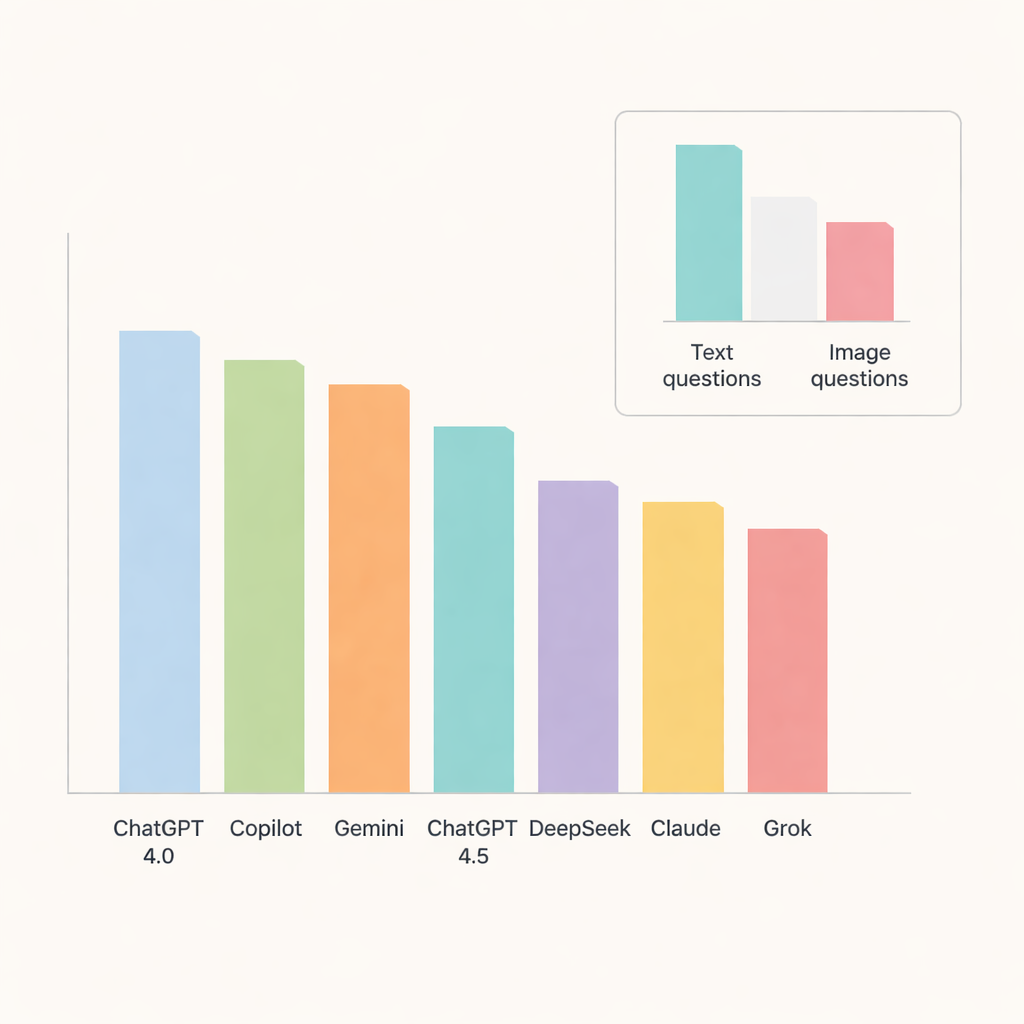
在所有聊天机器人中,ChatGPT 4.0 表现突出,约有 91% 的题目答对。Copilot 和 Gemini 紧随其后,准确率约为中高 80% 区间,而 ChatGPT 4.5、DeepSeek、Claude 和 Grok 则稍逊一筹。进一步分析各专题时,模型在口腔病理与唾液腺疾病方面表现尤为出色,准确率接近或超过 90%。相比之下,放射解剖学和软组织钙化物的题目明显更难,拖累了各系统的得分,这也提示 AI 在处理细粒度细节时仍存在不足。
图像仍比文字更难
一项关键测试是聊天机器人能否像处理文字那样处理影像。在这里,它们的局限性变得明显。即便是表现最好的模型,在基于图像的问题上准确率也大幅下降。ChatGPT 4.0、Gemini 和 Copilot 在此类别中领先,但仍仅约正确回答了三分之二的视觉题目。DeepSeek 在图像题上表现最差,仅略高于三分之一的正确率。对于大多数模型而言,文字与图像表现之间的差距足以达到统计学意义,这强调了解析医学影像仍然是当今通用型 AI 的一项艰难任务。
这对学生和患者意味着什么
研究的结论是,现代聊天机器人在牙科教育中可以成为强有力的辅助工具,特别适合复习事实性内容和练习放射学类型的考试题目。然而,即便是最强的系统也会犯足够多的错误——尤其是在对视觉要求高或高度专业化的题目上——因此无法安全地替代专家判断。对于学生和临床医生来说,这些工具应被视为智能的学习伙伴或决策辅助,而非独立权威。在适当的谨慎与监督下使用,它们可能加速学习并扩大获取高质量解释的渠道,但诊断与治疗的最终责任仍应由受过训练的专业人士承担。
引用: Geduk, G., Hasırcı, U.C., Kusay, D.D. et al. A comparative analysis of the performance of large Language models in the dentistry specialty examination. Sci Rep 16, 6739 (2026). https://doi.org/10.1038/s41598-026-37800-8
关键词: 牙科教育, 人工智能, 大型语言模型, 口腔颌面放射学, 医学考试