Clear Sky Science · zh
使用基于 GAN 的增强方法进行不平衡数据集跨语言短信垃圾邮件检测
为什么你的短信仍需要保护
我们大多数人相信不需要的短信会悄悄进入垃圾箱,但幕后的实际问题非常棘手。真实的垃圾短信相比日常消息很少,而且越来越常同时出现在多种语言中。本文提出了一种新方法,通过将强大的语言模型与巧妙的“伪造数据”生成器结合,让过滤器能够在不危及隐私的前提下,从更多的恶意消息示例中学习,从而更好地识别危险的短信垃圾邮件。
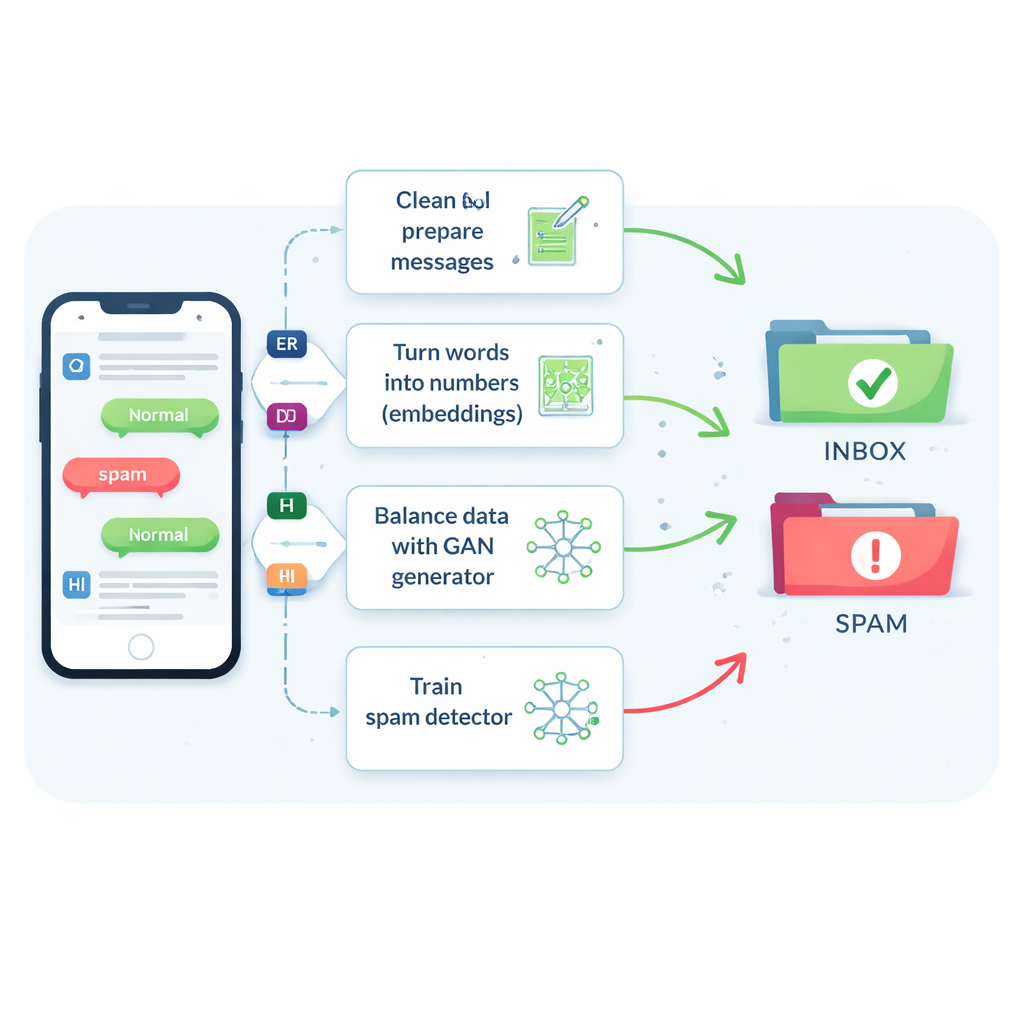
罕见且善变的垃圾短信问题
垃圾短信大约只占每七条消息中的一条,但即便漏掉很小一部分,也可能使人们暴露于诈骗、恶意软件和身份盗用风险中。传统过滤器困难重重,因为短信很短、充满俚语和缩写,并且实时到达,缺乏额外上下文。因此,许多系统倾向于判断消息为安全,以保持用户体验,但这也让更多有害信息漏网。那些简单复制垃圾短信或通过修改词语生成新示例的老办法虽有一定帮助,但经常会混淆分类器或产生与犯罪分子真实发送内容不符的不现实示例。
教机器理解消息含义
作者首先比较了八种不同的学习算法,从熟悉的支持向量机和决策树到更先进的将文本视为序列的神经网络,如长短期记忆(LSTM)网络。他们还测试了五种将词转换为计算机可用数值的方法。简单的词频计数(称为词袋或 TF–IDF)速度快但无法理解含义。较新的“嵌入”方法如 Word2Vec 和 GloVe 会把含义相近的词在数值空间中靠近。最先进的是基于 Transformer 的模型如 BERT,它会根据周围句子调整一个词的表示,帮助系统区分例如友好提醒与具有迷惑性的诈骗。
使用智能“伪造”垃圾邮件修正数据集不平衡
该研究的核心创新是如何应对垃圾短信样本不足的问题。团队没有生成完整的伪造句子,而是在垃圾短信的数值嵌入上直接训练一种称为生成对抗网络(GAN)的神经网络。GAN 的一部分——生成器,学习在这个高维空间中创建类似垃圾邮件的合成点,而另一部分——判别器,学习区分这些合成点与真实样本。通过这种对抗过程,生成器产生出现实感很强的新垃圾邮件嵌入以扩充训练集。基于相似性的质量检查确保只保留与真实垃圾邮件高度相似的合成示例,从而降低了会误导分类器的无意义数据的风险。
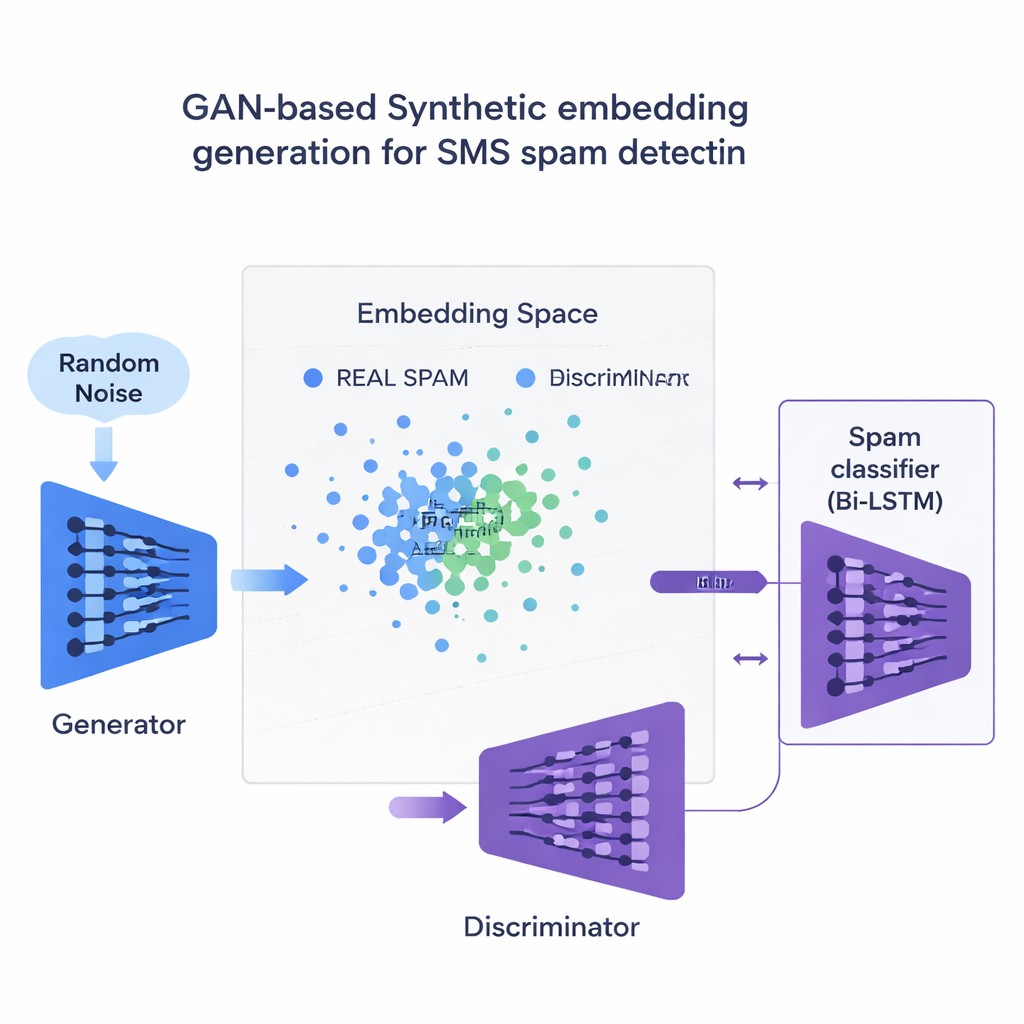
跨语言与设备的结果
研究者在英文短信数据集和翻译成法语、德语与印地语的多语言版本上测试了 120 种不同的模型、嵌入和数据平衡方法组合。总体来看,上下文型嵌入如 BERT 的表现优于传统的词频方法。最佳方案是使用双向 LSTM,输入为 BERT 嵌入并用 GAN 生成的垃圾邮件示例进行训练,在英文消息上达到约 97.6% 的 F1 分数,在多语言集合上达到 94.4%,略领先于现有的最先进系统。关键在于,该方法在将误报率保持极低的同时取得这些成绩——这是很重要的,因为一次性密码和银行提醒不能被误判为垃圾。研究还将这种 GAN 策略与常见的平衡工具如 SMOTE 和 ADASYN 进行了比较,发现 GAN 产生了更干净、更现实的训练数据,并在整体性能上略有优势。
对普通用户的意义
对非专业读者来说,结论是垃圾过滤器开始理解消息的含义和上下文,而不仅仅是单个词,并且可以通过精心制作的合成数据来“教学”,而不必看到更多你的真实短信。通过直接在编码消息含义的空间中工作,该方法为安全系统提供了关于垃圾短信在多种语言中外观的更丰富图景,而不会用笨拙的伪造示例淹没系统。这提高了捕捉危险消息并确保真实消息送达的可能性,为在骗子不断变换策略的情况下的移动用户提供了更强大、更具适应性的保护。
引用: Filali, A., Shorfuzzaman, M., Abdellaoui Alaoui, E. et al. Cross-lingual SMS spam detection using GAN-based augmentation for imbalanced datasets. Sci Rep 16, 7128 (2026). https://doi.org/10.1038/s41598-026-37769-4
关键词: 短信垃圾邮件检测, GAN 数据增强, BERT 文本嵌入, 多语言网络安全, 移动钓鱼攻击