Clear Sky Science · zh
一种用于视频序列中暴力检测的轻量级卷积神经网络架构
让相机观察人群,减轻人类负担
从演唱会和体育场馆到地铁站和购物中心,摄像头如今监视着几乎所有拥挤场所。然而,大多数视频仍由疲惫的人眼监看,常常会错过冲突或踩踏的早期征兆。本文探讨了一种精简、速度快的人工智能形式,如何在低成本硬件上实时扫描视频以检测暴力行为,帮助安保人员在事态失控前迅速响应。
为何在视频中识别暴力如此困难
乍看之下,让计算机判断“打斗”与“非打斗”似乎很简单:仅检测互相殴打的人。实际上问题很复杂。光线可能很差或突然变化,人群可能遮挡视线,摄像机安装角度各异。即便没有危险,拥挤的摇滚演唱会也显得混乱,而拳击比赛在擂台内的激烈场面却是正常的。传统视觉系统逐帧查看人工设计的运动模式和边缘信息,虽然在实验室有效,但在繁忙的真实监控网络中常常过慢或不够准确。
为摄像头流量设计的更轻量“大脑”
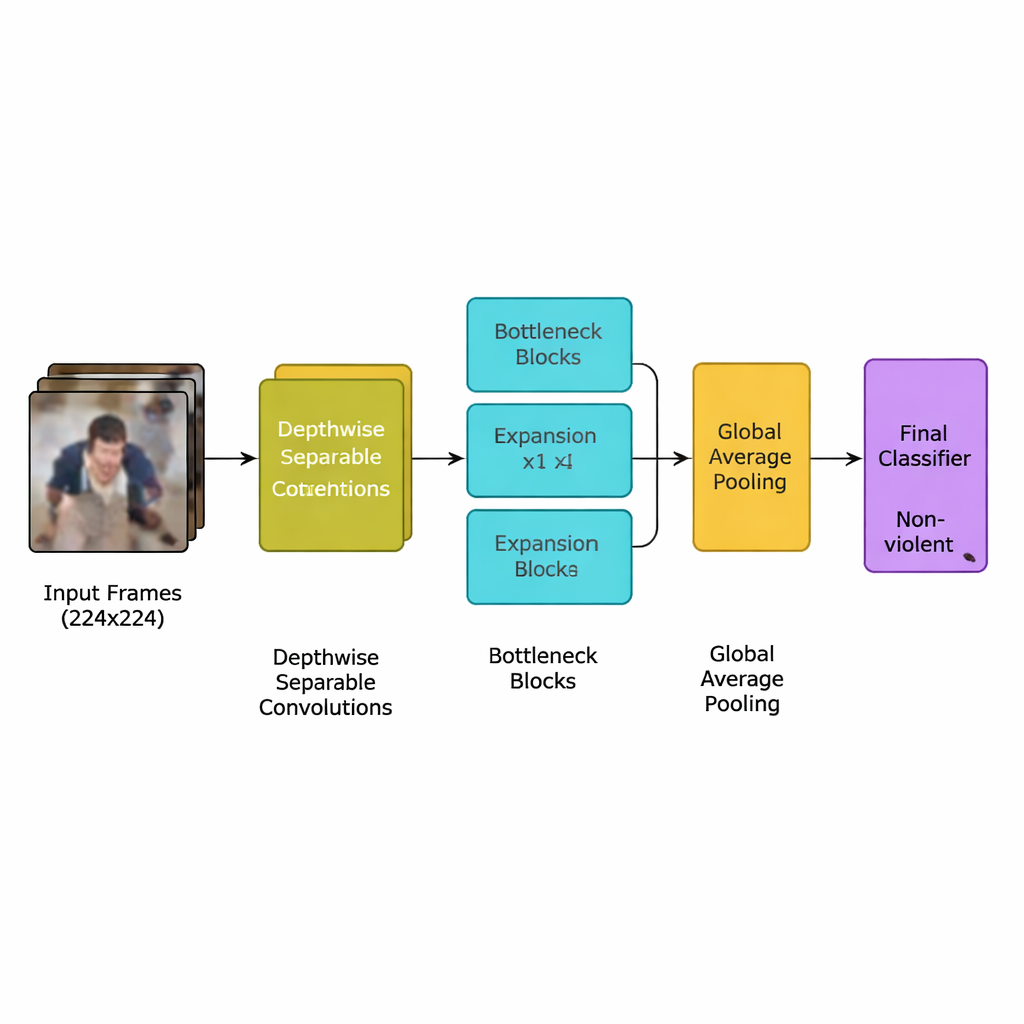
作者提出了一种专为该任务设计的新型深度学习模型:一种基于高效模型族 MobileNetV2 的轻量级卷积神经网络(CNN)。该网络不依赖需要强大图形处理器的大量沉重层,而是采用逐通道可分离卷积——小而有针对性的计算,极大减少了运算量。同时使用“反向瓶颈”模块,先短暂扩展再压缩信息,以在丢弃冗余的同时保留重要的运动线索。在此基础上,团队加入了一种称为 squeeze-and-excitation 的注意力机制,帮助网络聚焦于在空间和时间上最典型的暴力运动模式,忽略干扰性的背景细节。
从原始视频到暴力警报
完整系统遵循清晰的流水线。首先,将视频流拆分为帧,仅保留每第五帧以去除近似重复同时保留常提示打斗的突发运动。帧被调整为标准的 224×224 像素,轻度模糊以降低背景噪声,然后在训练期间随机翻转或旋转,使模型学会应对不同的摄像机视角。处理后的图像进入轻量级 CNN,网络逐步将原始像素转换为更高层次的人群行为模式。经过最终的池化步骤总结每帧信息后,一个小型分类器输出简单决策:暴力或非暴力。由于该模型仅使用约 1.94 百万参数——比其 MobileNet 与 MobileNetV2 先辈更少——它可以在靠近摄像头的中等设备上实时运行,而无需远程数据中心。
将系统付诸检验
为了验证这种紧凑设计是否能与更庞大的网络竞争,研究人员在两个广泛使用的基准数据集上训练和评估了模型。Real-Life Violence Situations Dataset 包含从 YouTube 抓取的 2,000 个短片,展示了日常场景与真实打斗,场景多样。Hockey Fight Dataset 提供 1,000 个职业冰球比赛片段,分为普通比赛和场上争斗。在这些数据集上,所提出的模型在真实场景片段上约正确标注了 97%,在冰球片段上为 94%,在计算量远远更少的情况下与 InceptionV3、VGG-19 等更大 CNN 不相上下甚至更优。跨数据集测试——在一个数据集上训练、在另一个上测试——表明系统仍能表现良好,说明它捕捉到的是通用的运动模式而非对单一环境的记忆。
这对日常安全意味着什么
对非专家而言,核心结论是:现在可以构建能够快速且低成本自动标记可能暴力事件的摄像系统,而无需巨型服务器或持续的人力盯防。研究表明,精心裁剪与调优的神经网络能够同时监视多路视频流、在检测到危险行为时发送警报,并能在适用于公共交通枢纽、学校、医院和城市街道的低功耗硬件上运行。尽管仍有挑战——例如处理极暗场景、严重拥挤或加入声音线索——这项工作指向了一个未来:智能摄像头作为不知疲倦的早期预警传感器,帮助安保团队更有效保护公众,同时减轻人类监视者的负担。
引用: Tyagi, B., Jain, R., Jain, P. et al. A lightweight convolutional neural network architecture for violence detection in video sequences. Sci Rep 16, 7557 (2026). https://doi.org/10.1038/s41598-026-37743-0
关键词: 暴力检测, 视频监控, 轻量级 CNN, MobileNetV2, 公共安全