Clear Sky Science · zh
基于生成对抗与人脸对齐网络的真实世界人脸超分辨率
从模糊照片中获得更清晰的人脸
任何试图对旧监控视频或社交媒体上的小头像放大的人都知道那种沮丧:放大越多,人脸就越变成方块状的模糊。本文提出了一种新的人工智能方法,能够将此类真实世界的低质量人脸图像还原为更清晰的图像,同时更好地保留一个人的身份和表情。这在监控摄像、照片鉴证乃至日常照片增强应用中都有明显的意义。
为什么模糊人脸如此难以修复
让一张小而模糊的人脸看起来清晰,不只是“增加像素”那么简单。传统方法依赖人工设计的规则或简单模式,近年的深度学习技术往往从人为降质的图像中学习:把干净的高分辨率人脸模糊并缩小,然后教网络逆转这个过程。问题在于,真实世界的图像——例如监控摄像头或压缩视频中的图像——所受的损坏是混乱且不可预测的。模糊、噪声和压缩伪影很少与训练中使用的整齐合成示例相匹配,因此在实验室中表现良好的模型在真实素材上常常失效。更糟的是,它们可能生成看起来合理但不再像原始人物的面孔。
面向真实世界图像的双向学习循环
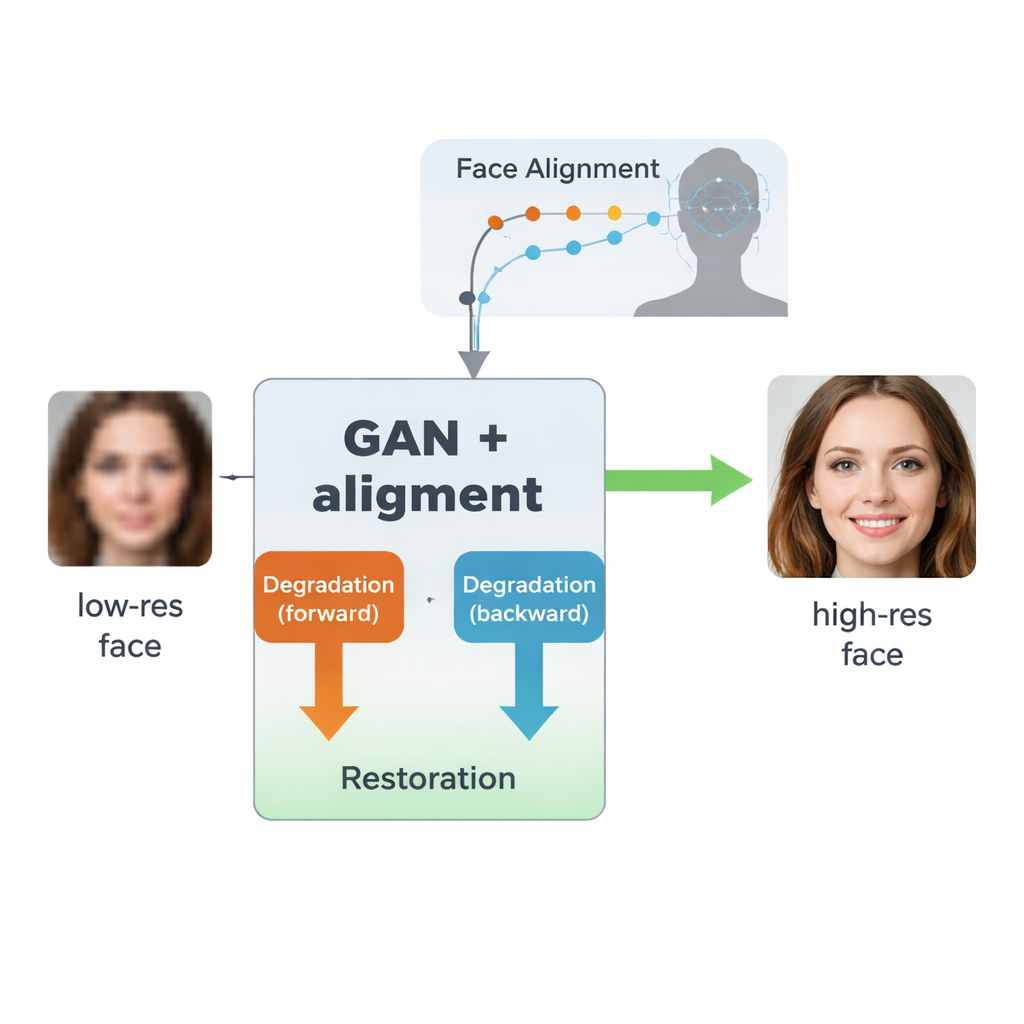
作者构建在一种称为生成对抗网络(GAN)的人工智能之上,这类网络通过让两个神经网络相互对抗来学习生成逼真图像:一个生成图像,另一个判断其真实程度。他们的设计受早期模型SCGAN启发,采用“半循环”结构,包含两个互补的循环。在前向循环中,真实的高分辨率人脸由一个分支有意降质以产生合成低分辨率版本,然后由共享的修复分支还原。在反向循环中,真正低质量的真实人脸由同一修复分支增强,随后由另一个分支再次降质以更接近真实低分辨率图像。通过在两个方向上强制一致性——先降质再还原,或先还原再降质——系统学习到人脸在实践中被破坏的真实模式,以及如何在不需要完全匹配的真实高低质量图像对的情况下逆转这一过程。
教会网络人脸的真实结构
这项工作的一项关键创新是让系统不仅使图像看起来更清晰,而且尊重人脸的底层结构。为此,作者整合了一个单独的人脸对齐网络,最初用于定位诸如眼角、鼻尖和嘴轮廓等关键点。该对齐网络预测强调每个关键点应在何处的“热力图”。在训练过程中,模型比较修复图像的热力图与同一人真实高分辨率人脸的热力图,并对不匹配之处施加惩罚。重要的是,这里使用的是预训练的对齐模型,并不需要对每张训练图像手工标注关键点。其结果是一种几何引导:增强网络被引导将眼睛、鼻子和嘴巴放在正确的位置和形状,而不是仅用通用的类似人脸的纹理去遮盖模糊。
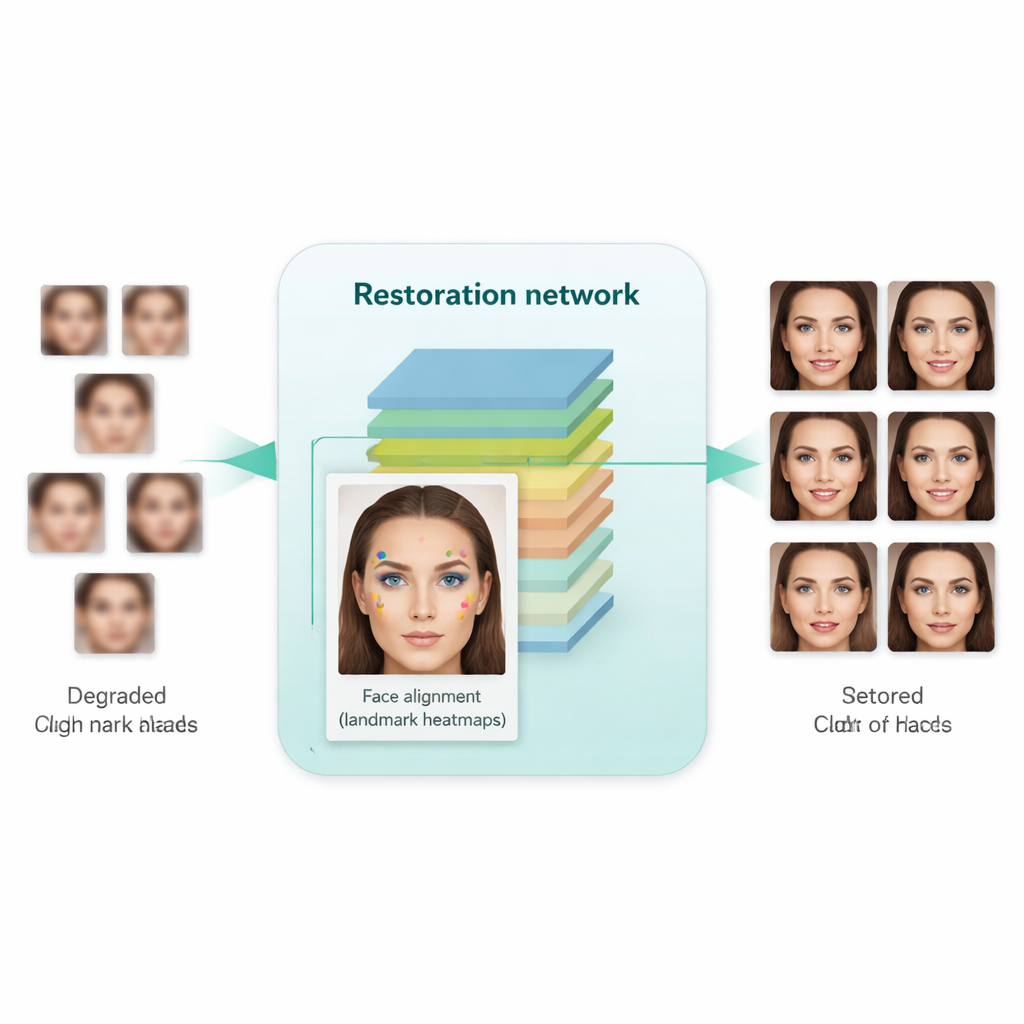
在实践中效果如何?
研究者在大量高质量人脸集合和另一组来自真实世界数据集的真实低质量人脸上训练他们的系统。然后他们在合成基准(有清晰的真实图像可作为参考)和真实世界图像(只能使用视觉真实感和统计指标评估)上进行了测试。与早期方法——包括著名工具如Real-ESRGAN、GFPGAN和原始SCGAN——相比,新方法生成的图像不仅看起来更自然、失真更少,而且在实际任务上的表现也更好。当将增强后的图像输入标准人脸检测器和流行的人脸识别模型(FaceNet)时,检测和验证的准确率明显提高,表明与身份相关的细节得到了更好的保留。与此同时,自动化质量度量也表明生成的人脸在分布上更接近真实的高分辨率照片。
这对日常使用意味着什么
简单来说,这项工作表明,通过结合两种思路:学习图像在真实世界中被破坏的真实模型,以及使用人脸关键点信息保持面部结构完整,你可以从低质量图像中得到更清晰、更可靠的人脸。系统不再只是“猜测”一个更好看的面孔,而是被引导去重建正确的人物,获得更清晰的眼睛、嘴巴和整体轮廓。这使得该方法在安全、鉴证和档案修复等领域尤为有前景,在这些场景中视觉清晰度和身份正确性都很重要,而图像的原始高质量版本往往不可获得。
引用: Fathy, H., Faheem, M.T. & Elbasiony, R. Real-world face super-resolution based on generative adversarial and face alignment networks. Sci Rep 16, 7492 (2026). https://doi.org/10.1038/s41598-026-37573-0
关键词: 人脸超分辨率, 生成对抗网络, 人脸对齐, 人脸识别, 图像修复