Clear Sky Science · zh
用于 AI 驱动纳米颗粒巨型库表征的图像处理流程
为什么微小颗粒需要大数据帮忙
现代材料科学越来越依赖制造并测试大量微小颗粒,以发现更好的催化剂、电池和其他先进材料。新的方法现在可以在单个芯片上生长数以百万计不同的纳米颗粒,但通过显微镜检查每个颗粒的质量会产生远超任何人可合理审阅的图像数量。本文描述了研究人员如何构建一个自动化图像处理与 AI 流水线,快速将“合格”与“不合格”的纳米颗粒图像分类,降低计算成本并加速实验,同时保持决策高度可靠。
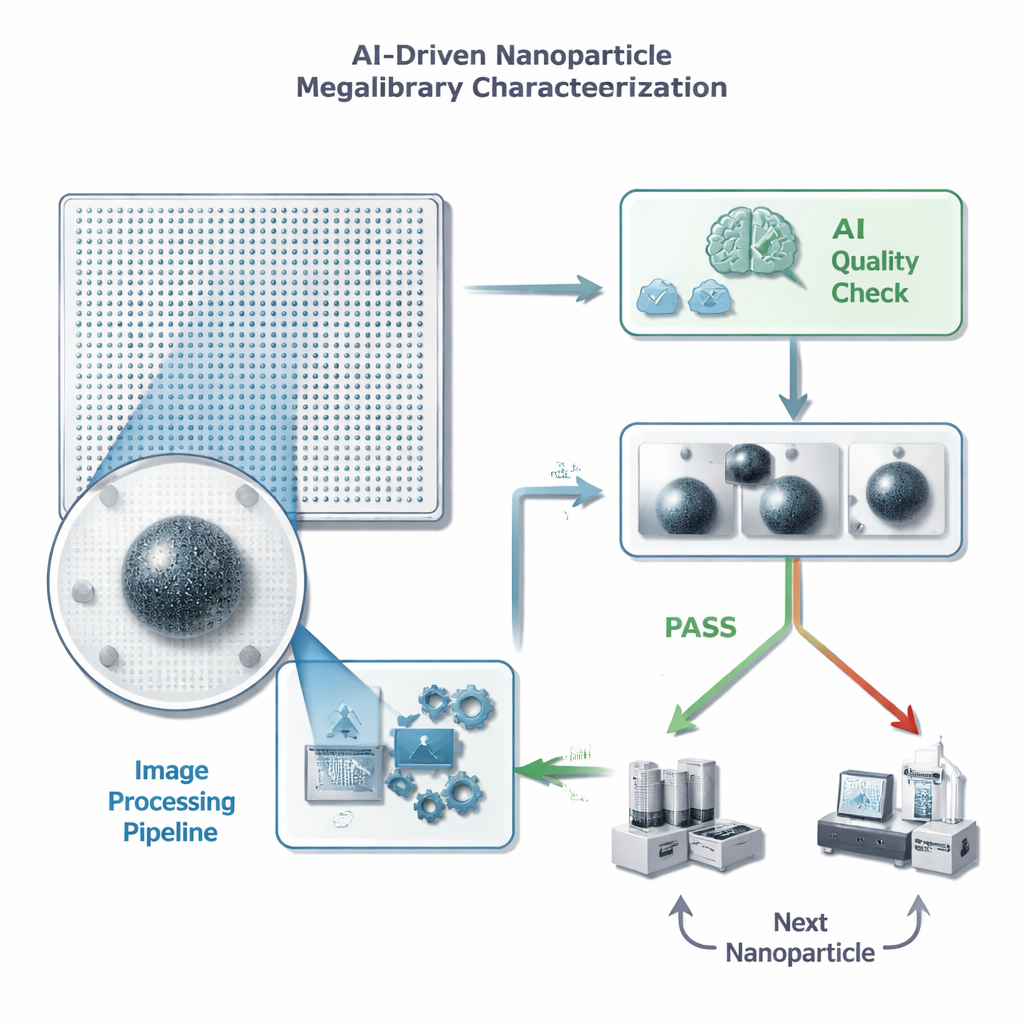
从海量图像到快速决策
在“巨型库”芯片中,每个纳米颗粒都位于已知位置,可由电子显微镜成像。在科学家在某个颗粒上投入时间和昂贵的后续测量之前,他们需要一个快速的质量检查:帧内是否恰好有一个清晰对焦的颗粒,且没有干扰性杂物或伪影?作者将此问题表述为机器学习模型的简单通过/不通过任务,但对每张图像的处理时间有严格限制——不到半秒,因为单个芯片可能包含百万级颗粒。他们还强调误报特别有害:若 AI 错误地通过了不良图像,会浪费时间和存储资源用于无用的详细测量,而偶尔漏掉的良好颗粒对整体进展的损害较小。
在 AI 查看之前先清理视图
研究团队没有把原始、带噪的显微图像直接丢进大型复杂的神经网络,而是设计了一个定制图像处理流程,先对图像进行“清理”。该流程去除背景噪声、锐化边缘、将图像紧密裁剪到颗粒周围,然后将图像缩小到更小的尺寸。关键是,这种预处理能使微弱特征更易辨识,并在不重新成像样品的情况下模拟更高放大倍数的外观。结果是一张紧凑、高对比度的图像,可供相对简单的神经网络使用,既减少了训练时间和存储需求,又保留了用于质量判断的重要细节。
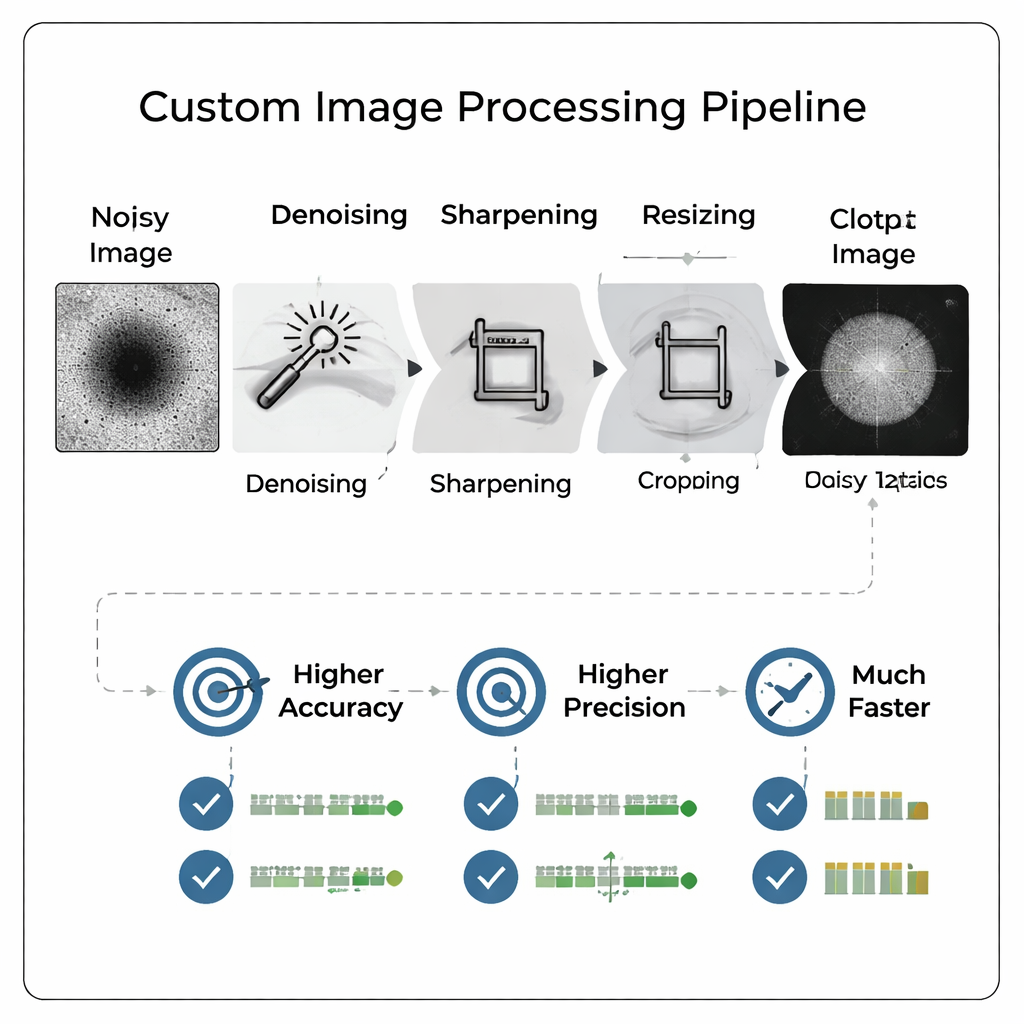
更聪明的图像胜过更大的模型
研究人员对许多流程变体和分辨率进行了严格比较,最终训练了 800 多个不同模型,以检验图像大小和处理如何影响性能。他们发现,经过精心处理的中等分辨率图像(例如 128×128 像素)使得小型卷积神经网络的表现超过了先前通过自动架构搜索发现并在完整 512×512 图像上训练的更大模型。准确率提高了超过 13 个百分点,而召回率——正确检测出良好颗粒的能力——提升了超过 18 个百分点。避免对不良颗粒浪费精力的关键指标精确率约达 96%,且作者偏好的综合性能指标也有所提升。
用更少数据做更多事
一个最引人注目的结果是,图像处理比原始图像尺寸更重要。当团队比较仅“下采样”图像与使用完整定制流程的图像所训练的模型时,处理过的图像始终更胜一筹——即便被缩小到极小尺寸如 16×16 像素也是如此。事实上,使用处理后 16×16 图像的最佳模型在几乎所有指标上都打败了使用未处理 128×128 图像的最佳模型。该流程在较低显微镜放大倍数时的帮助尤为明显,而低倍图像通常更难解读。因为低倍图像采集速度更快,这意味着实验室可以在不牺牲决策质量的情况下更快地扫描芯片。
为自驱动实验室带来更快的决策
通过将智能图像处理与精简的 AI 模型结合,作者将训练时间从在超级计算机上数小时降低到单个图形处理器下不到一分钟。训练完成后,系统处理并分类一张新图像约需 75 毫秒,远低于 500 毫秒的目标,也远快于人工审阅。就实际应用而言,这意味着对纳米颗粒巨型库可以进行快速且可靠的筛选,帮助研究人员将昂贵仪器聚焦于最有前景的候选者。随着实验室朝着更自动化的“自驱动”发现系统发展,这类先清理数据再应用精简 AI 的方法,为将难以为继的图像流转化为可操作的科学洞见提供了强有力的路径。
引用: Day, A.L., Wahl, C.B., dos Reis, R. et al. Image processing pipeline for AI-driven nanoparticle megalibrary characterization. Sci Rep 16, 7675 (2026). https://doi.org/10.1038/s41598-026-37566-z
关键词: 纳米颗粒, 图像处理, 机器学习, 材料发现, 电子显微镜