Clear Sky Science · zh
关于深度多标签学习中即插即用相关性增强模块的研究
教会机器处理过多的标签
在线商店、法律档案和医学数据库都依赖能够快速为每篇新文档打上合适标签的软件。但现代系统常常面临数万甚至数百万个可能的标签——从产品类别到医学主题——而每个文本通常只需少数几个标签。本文提出一种名为标签相关性增强网络(LCENet)的新型附加模块,帮助现有深度学习模型更好地利用标签在真实数据中自然共现的模式,从而实现更准确、更快速的文本标注。
为什么在网页规模下标注如此困难
许多现实应用属于研究者所谓的极端多标签文本分类:给定一段简短描述或长文档,系统必须从庞大的标签目录中挑选出少量相关标签。例子包括为电商网站的商品分配类别、用MeSH术语为生物医学文章编索引、将广告与网页匹配或把法律文本映射到详细的法律条目。这些场景有三大共同挑战:标签表极其庞大、大多数标签十分稀有、且任一文本仅使用少数标签。传统方法要么把问题拆成许多小分类器,要么将标签压缩到低维向量,但它们常常依赖简单的词频统计,无法充分捕捉语义或标签间的关系。
现有深度模型仍然忽略的东西
现代深度学习方法,如卷积网络、循环网络以及基于Transformer的模型(例如BERT),通过学习丰富的语义表示大大提升了文本理解能力。然而,几乎所有这些方法在最后一步都做了一个关键的简化:文本被编码成向量后,模型独立地预测每个标签。但实际上,标签之间存在强烈的相互作用。一篇被标注为“糖尿病”的医学论文更可能也涉及“胰岛素抵抗”,而标注为“智能手机”的设备通常与“电子产品”和“通信设备”有关。忽视这些模式意味着模型无法利用高置信度的标签来支持置信度较低的标签,甚至可能输出组合上互不相容的标签。
一个学习标签关系的即插即用模块
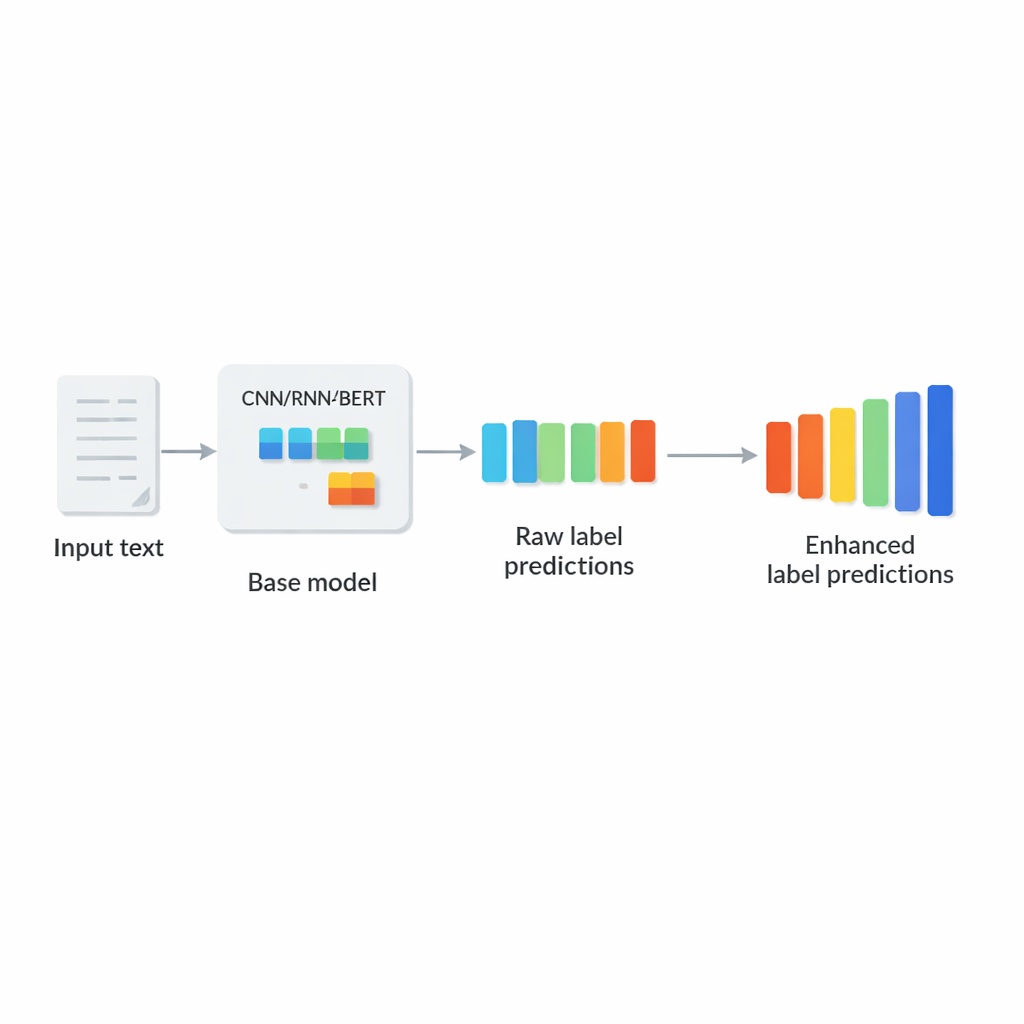
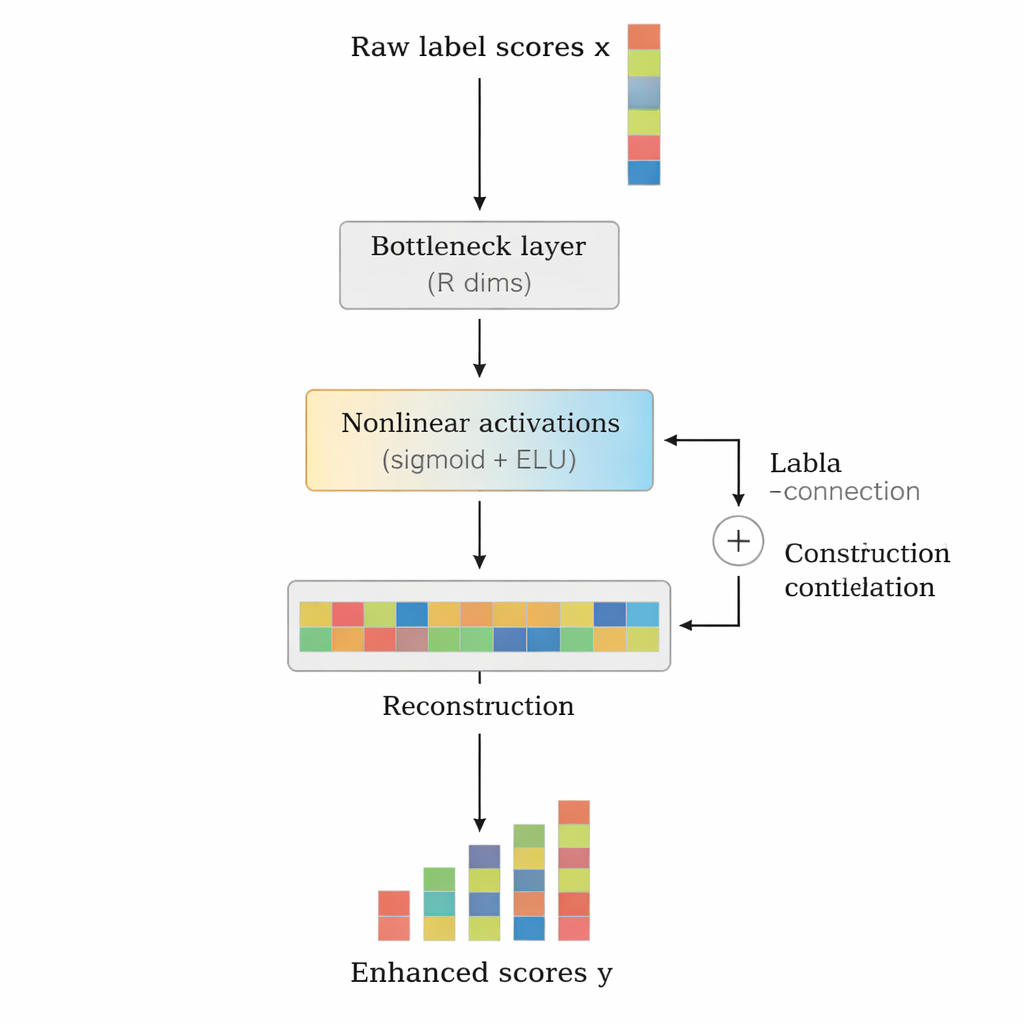
作者提出LCENet作为一个轻量级的即插即用模块,位于任意现有深度文本分类器之后。LCENet并不改变基础模型如何读取文本,而是接收基础模型产生的原始标签分数,并将其通过一个紧凑的“瓶颈”映射到低维表示,在该表示中相关标签会聚类在一起。非线性激活函数使该模块能够捕捉复杂的高阶关联,而不仅仅是简单的成对关系。残差(或跳跃)连接将原始分数直接与修正后的分数一起送至输出,这既稳定了训练又确保该附加模块不易使结果变差。关键在于,LCENet将额外参数的增长从与标签数平方成比例降低为更可控的线性增长,因此即便面对数十万标签也仍然可行。
在多模型和多数据集上验证其效益
为检验LCENet是否真正通用,作者将其连接到四种非常不同的深度模型上,包括基于CNN和基于BERT的架构,以及专为生物医学和极端标签场景设计的系统。他们在三个公开基准数据集上评估了这些组合:欧洲法律语料(EUR-Lex)、亚马逊商品数据集(AmazonCat-13K)以及包含超过五十万标签的大规模维基百科集合(Wiki-500K)。在所有模型、数据集和六个以排序为中心的指标上,LCENet都持续带来性能提升,在最大的数据集上有时将Top-1精度提高超过五个百分点。训练曲线还显示,LCENet通常将达到某一精度所需的训练步数几乎减半,因为从一开始添加的标签相关结构为学习提供了更清晰的信号。
这对日常系统的重要性
对于已经依赖深度模型进行文本标注的从业者来说,LCENet提供了一种无需重构系统或收集新标注即可提升准确性和训练速度的实用途径。它把标签空间本身视为一种知识来源,学习哪些标签倾向于一起出现或互相排斥,然后相应地调整预测。虽然该方法为文本开发,但利用输出间学习到的关系来增强预测的思想同样可应用于图像、多模态数据和其他结构化预测任务。简单来说,LCENet帮助机器“记住”标签间的联系,使其不再像孤立的复选框那样猜测,而更像理解概念如何相互关联的博学人类。
引用: Zhang, J., Yuan, C. & Li, X. Research on plug-and-play correlation enhancement modules in deep multi-label learning. Sci Rep 16, 6788 (2026). https://doi.org/10.1038/s41598-026-37565-0
关键词: 极端多标签文本分类, 标签相关性, 深度学习, 文本分类, 神经网络