Clear Sky Science · zh
DMSCA:用于卷积神经网络中增强特征表示的动态多尺度通道-空间注意力
教会计算机更好地“注意”
现代图像识别系统可以识别猫、交通标志和影像中的肿瘤——但它们并不总是知道在一张图像内该把注意力放在哪儿。本文提出了一种新方法,帮助这些系统聚焦图像中最重要的部分,从而提高准确性并在现实世界的复杂条件下更可靠。该方法称为动态多尺度通道-空间注意力(DMSCA),可插入现有的卷积神经网络,帮助它们更智能地同时理解图像中的“是什么”和“在哪里”。
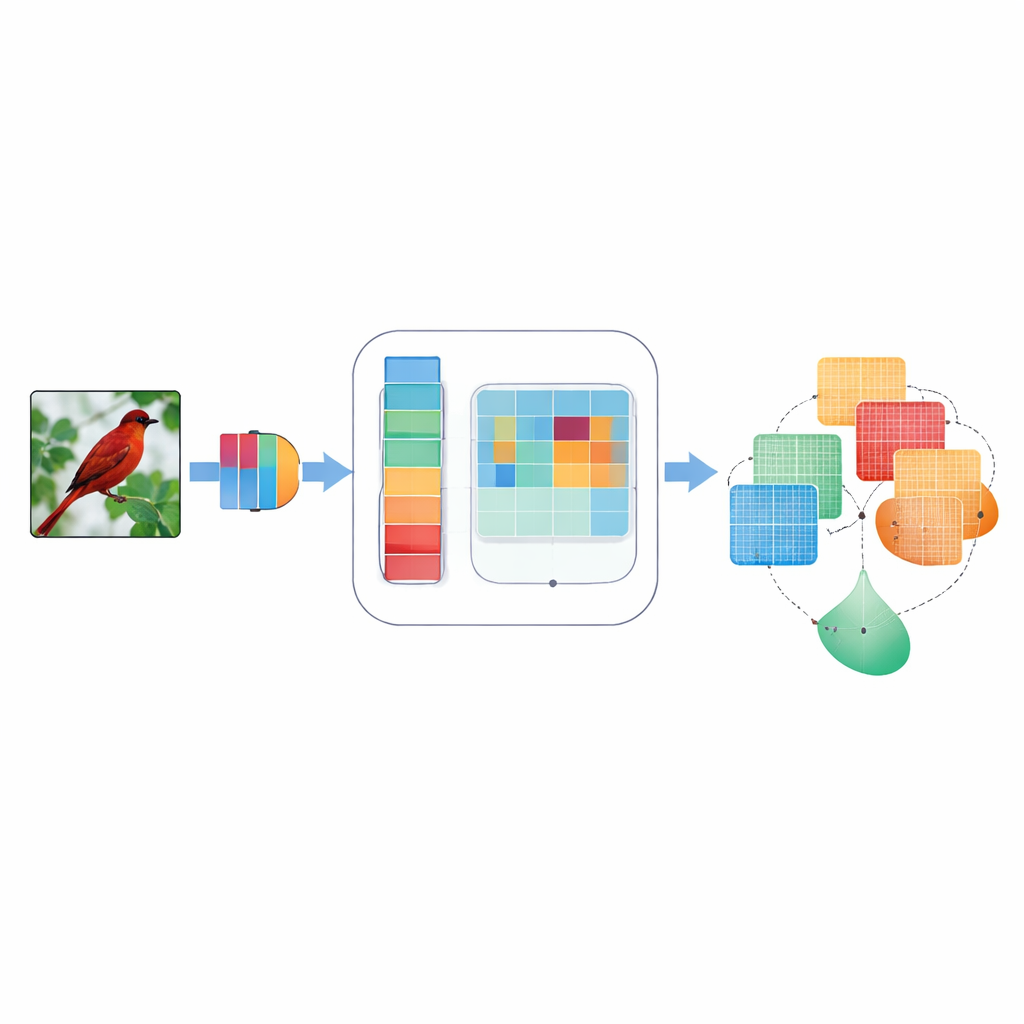
为何关注点对机器视觉至关重要
卷积神经网络是许多视觉应用的主力,通常会把所有内部信号视为同等重要。这意味着一只鸟翅膀的微弱边缘和一片天空可能获得类似的关注,尽管只有前者有助于识别物种。早期的“注意力”方法试图通过对某些内部信号赋予更高权重来解决这一问题——或者在类似颜色的通道间,或者在图像的二维布局上。但这些方法往往使用固定的、手工设计的规则,只在单一尺度上观察细节,或以不能适应不同图像的僵化方式组合信息。因此,它们有时会错过细微特征,忽略诸如“水平与垂直”之类的方向性,或者在图像有噪声或模糊时表现不佳。
更聪明的注意力插件
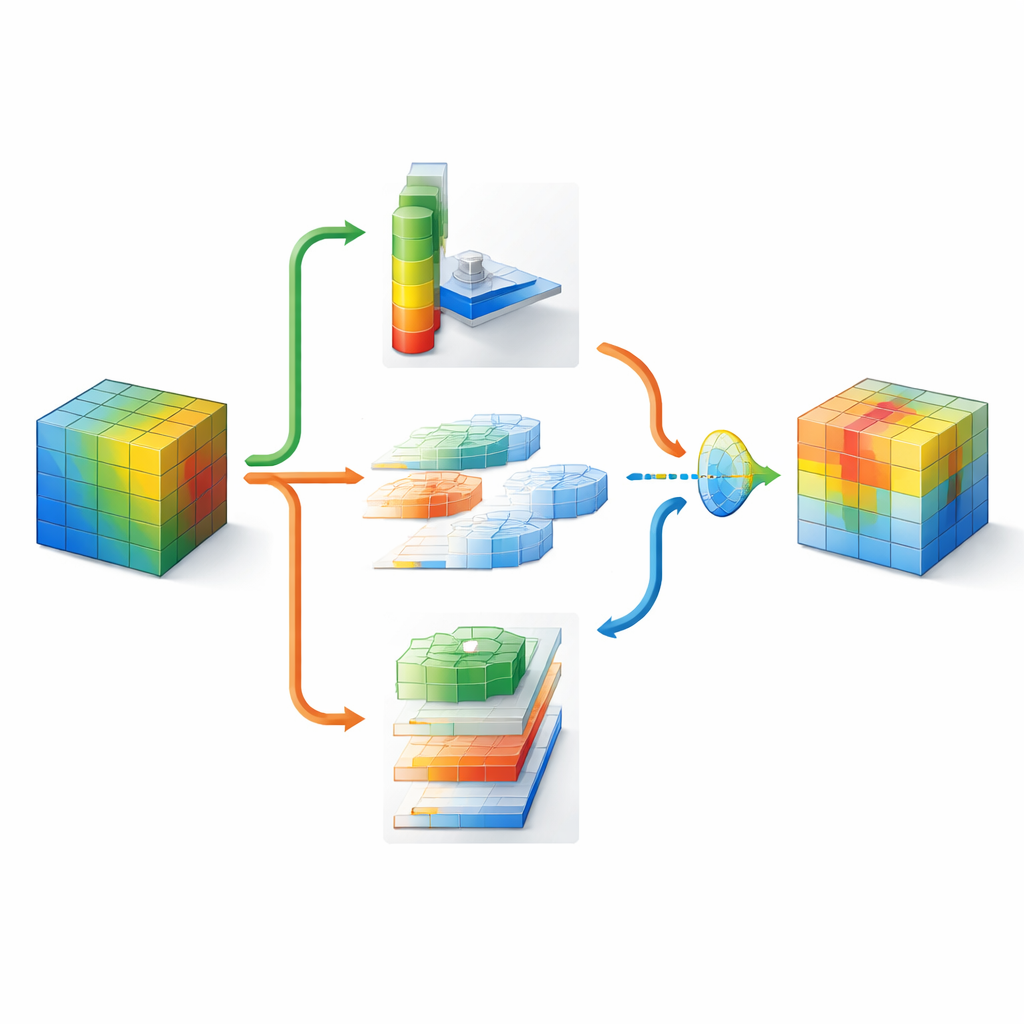
DMSCA 被设计为一个小型的可附加模块,可插入诸如 ResNet 等知名网络而不改变其整体结构。模块内部协调六个紧密相连的部分协同工作,而不是孤立运行。其中一部分汇总整个图像以捕捉全局信息,另一部分则学习每个内部通道应有的权重,使用可控的“温度”参数以在需要时使决策更尖锐或更平滑。在空间维度上,DMSCA 同时使用多种窗口尺寸以捕获从微小纹理到较大形状的内容,并明确关注水平与垂直方向,避免长边或条纹被弱化。最后,模块并不是简单地把这些信号相加,而是逐像素地学习在多大程度上信任来自通道的“是什么”信息与来自空间的“在哪里”信息。
在多尺度与多方向上观察图像
为确定图像中应关注的位置,DMSCA 首先将众多内部通道压缩为一个紧凑的两层映射,突出背景趋势与显著特征。随后将该映射送入几条并行的不同尺寸滤波器。小尺度滤波器能看到毛发或羽毛等细微纹理,而大尺度滤波器则捕捉诸如整个头部或身体的形状。并行地,一个方向性单元沿行和列分别扫描,保留重要结构的精确位置。这些水平与垂直视图随后可以互相作用,例如强烈的垂直信号能够增强对应的水平位置。结果是一个丰富的注意力图,它不仅告诉网络某物很重要,还指出它在哪里以及处于什么尺度。
让网络自己决定最重要的东西
由于图像的不同区域可能需要不同策略,DMSCA 并不强加固定的通道与空间信息组合规则。相反,它构建了一个微小的“门”,同时查看两类信息并为每个像素独立决定各自的权重。在背景杂乱处,系统可能更多依赖突出的通道;在物体清晰边缘处,则可能更强调空间线索。最终的自适应激活阶段类似于一个可学习的调光开关,提升真正有信息量的区域并抑制残余噪声。这一多阶段过程有助于将网络的注意力引导到连贯的、与物体相关的区域,这一点已通过可视化热图和高亮区域与真实标注对象匹配度的定量指标得到验证。
以适度额外开销获得更清晰的视觉
作者在多个标准基准上测试了 DMSCA,从小型的微图像集合到大规模的 ImageNet 数据集。当将其加入流行的 ResNet 模型时,DMSCA 持续提高了分类精度——在小型集合上最高提升约 2 个百分点,在 ImageNet 上约提升 1.5 个百分点——并优于多种现有注意力方法。它还使模型对噪声、模糊和高压缩等常见图像退化更具鲁棒性,并提升了目标检测与场景标注等相关任务的表现。这些改进仅带来了适度的计算和内存开销。简言之,DMSCA 为卷积网络提供了一种更灵活、语境感知的方式来决定观察什么与忽略什么,使机器视觉更接近人类视野的选择性聚焦。
引用: Zong, L., Nan, S.J., Die, Z.F. et al. DMSCA: dynamic multi-scale channel-spatial attention for enhanced feature representation in convolutional neural networks. Sci Rep 16, 8044 (2026). https://doi.org/10.1038/s41598-026-37546-3
关键词: 注意力机制, 图像识别, 卷积神经网络, 特征表示, 鲁棒计算机视觉