Clear Sky Science · zh
通过标签图优化和混合损失函数提升跨模态检索
在图像与文字间更智能地搜索
我们每天都在浏览大量照片、视频和文本。要精确找到所需内容——比如与一条简短说明相匹配的所有图片——取决于计算机把图像与语言连接起来的能力。本文探讨了一种新的方法,以在更复杂的真实场景中提高这种连接的准确性,这些场景中往往同时出现多个概念和对象。其结果是更智能的搜索工具,能够更好地“理解”我们的意图,而不仅仅是字面输入。
一张图片包含多重含义为什么重要
一幅图像很少仅展示单一事物。一张鲸鱼跃出海面的照片可能同时包含海洋、天空、波浪、风和野生动物。为这样的图片打标签时,我们通常会附上多个相互微妙关联的标签。现有的检索系统通常将这些标签看作互不相关的复选项。这种简化丢弃了有用线索:如果“鲸鱼”经常与“海”一起出现,那么看到其中一个应当提高另一个出现的概率。本文致力于捕捉标签之间的这些隐含联系,使得对某一概念的搜索也能找到表达密切相关概念的图像与文本。

构建标签间的连接网络
作者提出了一种称为二层图卷积网络(Two-Layer Graph Convolutional Network,或 L2-GCN)的技术来建模标签之间的关系。简单来说,每个标签(如“天空”或“鲸鱼”)被视为网络中的一个节点,节点之间的连线反映这些标签同时出现的频率。该方法反复让每个标签“聆听”其邻居,从相关标签中融合信息,同时保留自身特性。经过这一过程,系统获得了更丰富的标签表征,更好地捕捉现实场景的结构,从并列概念(如“海”和“沙滩”)到更层次化的概念(如“动物”和“鲸鱼”)。
让图像与文本共享一个共同空间
当然,标签只是部分内容;系统还需要从图像和文本本身学习。该框架使用成熟工具将原始像素和词语转换为数值特征,然后将两类数据投射到一个共享空间,在那里它们的语义可以直接比较。一个对抗模块——灵感部分来自生成对抗网络的推拉机制——阻止模型只依赖图像或文本的格式特征。这有助于共享空间关注内容而非形式,因此一张繁忙街道的图片与描述它的简短说明会在这个共同语义图谱中靠得更近。
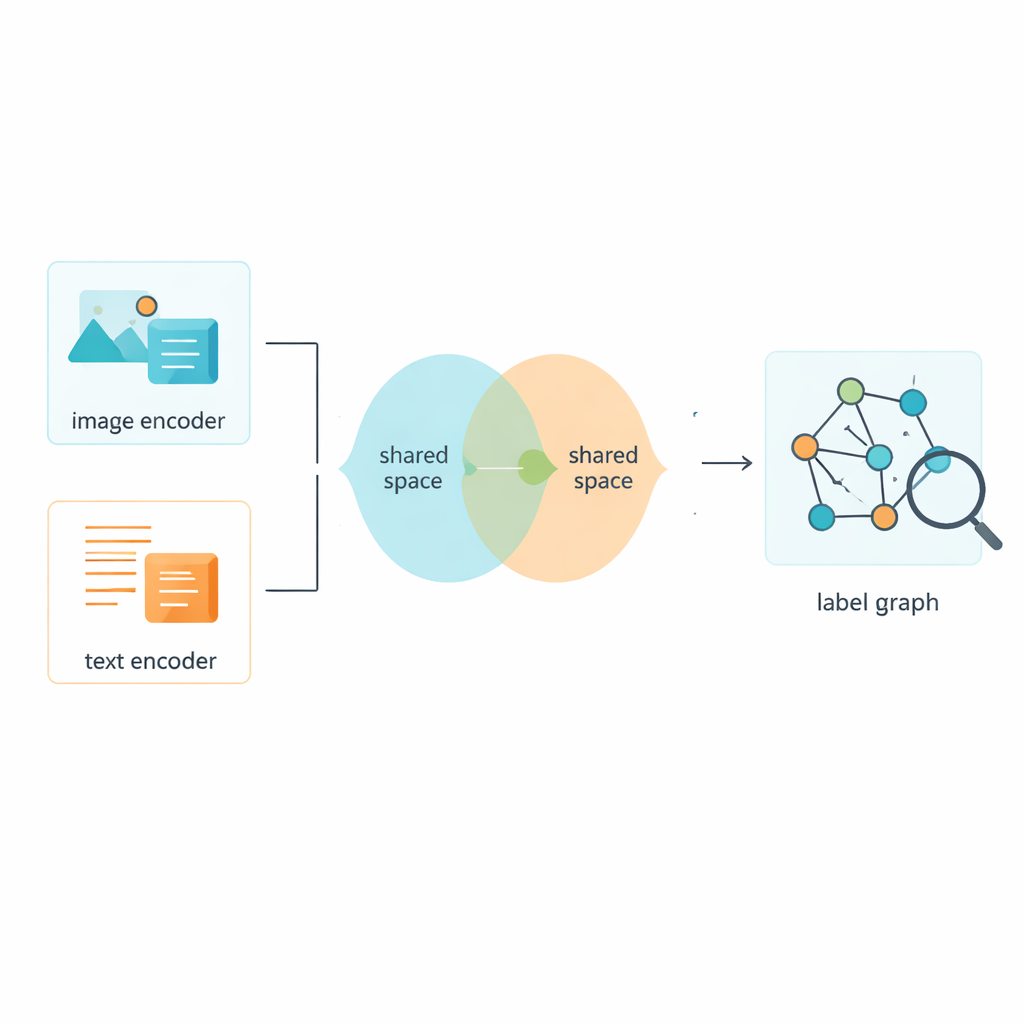
用于更清晰区分的混合训练策略
训练这样的系统需要不止一种学习规则。作者设计了一个名为 Circle-Soft 的组合损失函数,融合了两种互补的思想。一部分鼓励同一类别的样本紧密聚集,同时以灵活自适应的方式将不同类别分开。另一部分侧重于图像与文本在跨模态描述上的对齐程度。可调权重在这两个目标之间取得平衡,避免模型仅拟合整齐的类别边界或仅关注跨模态对齐。附加的分类和对抗损失进一步促进精炼后标签与共享的图像—文本特征之间的一致性。
这对检索性能的提升有多大?
为检验这些想法是否能转化为更好的检索效果,作者在三个常用的真实图文配对集合上测试了方法:MIRFlickr、NUS-WIDE 和 MS-COCO。这些数据集包含从数千到数十万张带有标签或说明的照片,涵盖从城市街景到野生动物的日常场景。在这三个基准上,新方法持续优于大量竞争方法,包括其他已使用图结构标签建模的先进系统。提升幅度在严格的检索评分中大约为半个百分点到一个百分点;这些改进看似小,但在成熟的基准上即意味着对内容理解更精确。对实际应用而言,这意味着当用户输入简短文本查询或提交一张图片时,系统更有可能在结果顶部呈现最相关的跨模态匹配。
这对普通用户意味着什么
对非专业读者而言,关键信息是:更聪明地处理标签及训练规则,可以明显改善机器连接图片与文字的能力。通过把标签视为相互联系的网络而非孤立标记,并通过精心设计视觉与文本信息在共享空间中的融合方式,该框架在复杂、多主题场景下使跨模态检索更可靠。随着时间推移,这类技术可为更直观的照片库、媒体平台和智能助手提供支持——即便我们的表达与脑中图像并不完全匹配,也能更准确地找到我们想要的内容。
引用: Wang, L., Wang, C. & Peng, S. Enhancing cross-modal retrieval via label graph optimization and hybrid loss functions. Sci Rep 16, 6400 (2026). https://doi.org/10.1038/s41598-026-37525-8
关键词: 图文检索, 多模态搜索, 图神经网络, 语义标签, 机器学习