Clear Sky Science · zh
基于 DNABERT 的深度学习框架用于预测转录因子结合位点
为何预测 DNA 控制开关很重要
你体内的每个细胞几乎携带相同的 DNA,但脑细胞、肝细胞和免疫细胞表现截然不同。其中一个原因是名为转录因子的特殊蛋白,它们像分子开关,通过在被称为结合位点的短 DNA 序列上停靠来开启或关闭基因。实验上在全基因组范围内找出所有这些停靠点既缓慢又昂贵。本研究提出了 TFBS-Finder,一种新的人工智能模型,能够读取原始 DNA 字母并更准确地预测转录因子结合位点,有望加速基因调控与疾病研究。
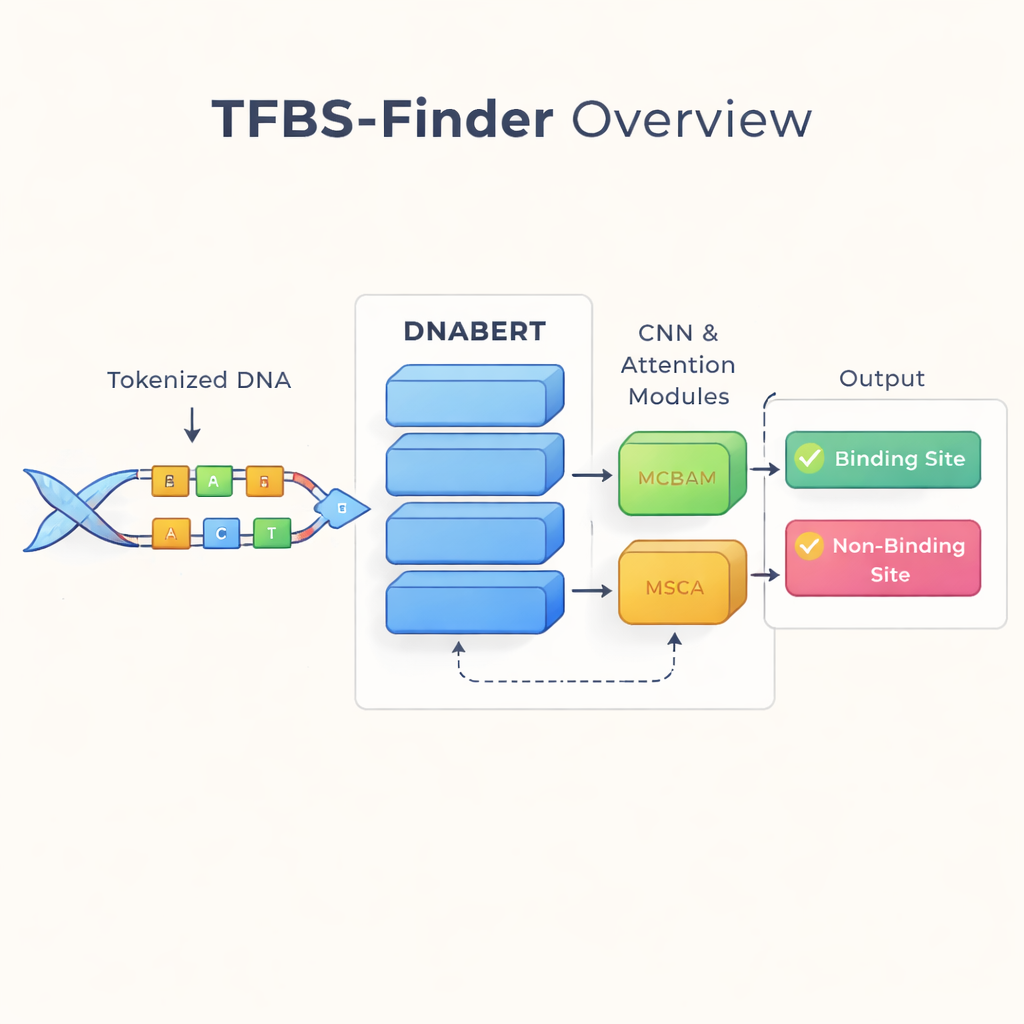
像阅读语言一样解读 DNA
作者基于一个已经改变语言技术的想法:把 DNA 当作文本来处理。他们使用 DNABERT——将 BERT 语言模型在人体 DNA 上重新训练而成的变体。DNABERT 不只查看单个字母;它将 DNA 切分为重叠的五字母短“词”,并学习这些片段如何共同出现。这使模型能够捕捉远距离的上下文,例如序列一端的模式如何与远处的模式相关联,就像理解一句话的含义而不是孤立单词一样。
用聚焦注意力寻找局部模式
尽管 DNABERT 在把握全局上下文方面表现良好,但转录因子结合常常依赖非常短且精确的基序——DNA 中的局部模式。因此 TFBS-Finder 在 DNABERT 之上增加了若干组件。卷积神经网络(CNN)在序列嵌入上滑动,突出重复出现的局部形状,有点类似图像处理软件检测边缘和角点的方式。两个注意力模块,称为 MCBAM 和 MSCA,则像可调的聚光灯,强化最有信息量的特征并抑制噪音。这些模块共同平衡宏观语境与细粒度细节,以判断某段 DNA 是否包含真实的结合位点。
证明每一部分确有其用
为了检验这些组件是否都必不可少,研究团队进行了广泛的“消融”实验,系统地移除或重排模块,并在覆盖29种转录因子和32种细胞类型的165个基准数据集上重新训练系统。使用标准的预测质量衡量指标,完整的 TFBS-Finder 模型始终名列前茅。仅依赖 DNABERT 的简化版本或缺少其中一个注意力模块的模型,准确性明显下降。统计检验确认这些性能下降并非偶然,表明将全局序列理解与精心设计的局部注意力结合起来至关重要。
跨细胞类型适用并优于既有工具
一个重要问题是:在一种生物学背景下训练的模型能否推广到另一种背景。作者以研究充分的转录因子 CTCF 为例,在一个细胞系上训练 TFBS-Finder,然后在其他细胞系上测试。在所有组合中,该模型均取得了较高分数,表明它捕捉到了跨组织共享的 CTCF 结合核心特征。与九种领先方法(包括早期的深度学习和基于 BERT 的模型)比较时,TFBS-Finder 显示出更高的平均准确率并能给出更可靠的结合位点排序。它的运行速度略快、内存占用也低于最相似的既有模型,表明更好的性能并不依赖更重的计算负担。
看见模型学到了什么
复杂的人工智能系统常被批评为“黑箱”。在这项工作中,研究者通过可视化哪些 DNA 位置对 TFBS-Finder 的决策影响最大来试图打开这个黑箱。针对两个具有已知结合基序的转录因子 CEBPB 和 GATA3,他们沿序列生成重要性评分,并将最强信号聚类为一致性模式。这些恢复出的基序与权威数据库中的参考基序高度吻合,且预测的结合区域与独立检测到的基序实例存在重叠。这表明 TFBS-Finder 并非简单地记忆样本,而是学到了关于转录因子如何识别 DNA 的生物学上有意义的规则。
这对遗传学与医学意味着什么
TFBS-Finder 提供了一种更准确且可解释的方法来描绘嵌入在我们 DNA 中的控制开关。通过定位转录因子可能结合的位置,它可以帮助研究者绘制基因调控网络、优先考虑可能破坏关键控制位点的遗传变异,并设计更有针对性的实验。尽管当前工作使用洗牌序列作为人工阴性样本并仅关注 DNA 字母,作者计划加入关于 DNA 形状的结构信息并探索更真实的背景序列。随着这些模型的改进,它们可能成为理解非编码 DNA 变异如何影响发育、进化与疾病风险的有力工具。
引用: Dutta, P., Ghosh, N. & Santoni, D. A DNABERT based deep learning framework for predicting transcription factor binding sites. Sci Rep 16, 7018 (2026). https://doi.org/10.1038/s41598-026-37483-1
关键词: 转录因子结合位点, 深度学习, DNABERT, 基因调控, 基因组学