Clear Sky Science · zh
用于多医院环境中具有不确定性感知的住院时长预测的分层置信框架
为何住院时长预测很重要
当有人入院时,家属和医务人员首先会关心的一个问题是:“他们会在医院待多久?”这个答案影响远不止好奇心:它关系到病床可用性、排班计划、手术室安排,甚至决定患者能否安全出院或需要额外支持。本文提出了一种新的住院时长预测方法,不仅给出单一估计值,还给出反映预测不确定性的合理区间——对安全和高效的护理至关重要。
预测住院时长的挑战
预测住院时长比看上去更困难。医院接诊的病人种类繁多,从常规病例到复杂急症不等,且不同医院在规模、所有制、教学属性和地区实践上存在差异。这导致患者在医院和地区内呈“簇状”分布,结果并非独立。许多现有的机器学习模型只输出最佳估计,却很少提供关于估计可能出错程度的可信信息。对于必须避免病房拥挤或空床的医院管理者来说,缺失的不确定性信息可能导致不安全的出院、无谓的取消或浪费性的“以防万一”缓冲。
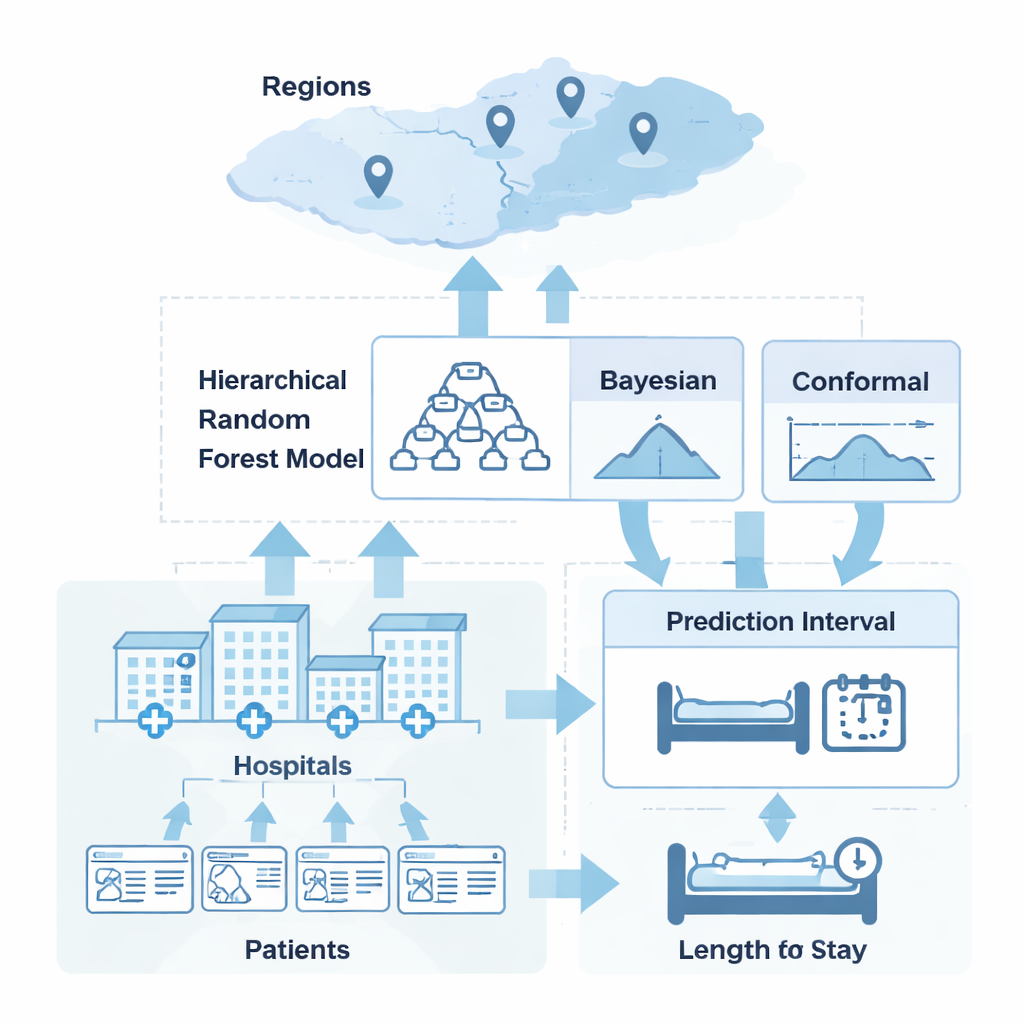
结合两种不确定性思路
作者研究了两种广泛使用的捕捉不确定性的方法,发现各自单独使用时都有严重缺陷。贝叶斯方法直接对不确定性建模,能反映医院嵌套于地区等复杂结构,但在模型假设有轻微偏离时,其不确定性区间往往过于自信。相比之下,置信预测方法对数据几乎不做假设,能够保证其区间在选定的比例时间内包含真实结果,但通常会对每位患者给出相同宽度的区间,忽视了某个病例难易程度的差异。本文的关键思想是创造一种混合方法,让各自发挥所长:用贝叶斯建模判断哪些患者更不确定、哪些更确定,用置信预测来控制区间的整体可靠性。
混合系统的实际运行方式
该系统以“分层随机森林”为起点,这是一种基于树的机器学习模型,它在三个层级学习模式:个体患者、所在医院以及医院所属的更大地区。在此基础上,贝叶斯层分析残差并估计每个新预测的不确定性,同时考虑医院和地区的特点。另一个独立步骤是置信校准,它基于数千例患者的历史预测误差来确定要达到目标可靠性(本研究中约为95%)时区间必须有多宽。混合方法随后将这些置信校准的调整对贝叶斯层判定为高风险的病例放大,对被判定为简单的病例缩小,从而产生既谨慎又高效的针对患者的区间。
数据对性能的表明
作者在一个全国住院数据库中对来自近3,800家美国医院的超过61,000次住院进行了测试。纯置信预测几乎准确地达到了95%的目标,但对所有人使用了基本相同的宽区间。纯贝叶斯附加方法产生了非常窄的区间,但仅在约14%的情况下包含真实住院时长——远低于安全使用的要求。混合方法则接近目标,覆盖约94.3%的病例,同时适度缩小了平均区间,更重要的是重新分配了区间宽度:对不太不确定的患者约缩窄21%,对最不确定的患者约放宽6%。这些自适应区间在不同类型的医院间保持稳定,即使在对完全未见过的机构进行测试时亦然。
对患者和医院的意义
对非专业读者而言,主要结论是这种方法把黑箱式的预测变成具有可理解且可信误差范围的工具。医院不再依赖单一不稳定的数字,而是获得有统计依据且随病例难易浮动的区间:常规患者区间更窄,可能让临床人员意外的患者区间更宽。这使得更现实地规划病床和人手成为可能,同时标记出需要额外关注和应急准备的患者。尽管目前的区间在日历天数上仍相对宽泛,该框架展示了严谨的统计学如何把医院的决策从猜测转向更可靠、具有不确定性感知的选择,从而兼顾安全与效率。
引用: Shahbazi, M.A., Baheri, A. & Azadeh-Fard, N. A hierarchical conformal framework for uncertainty-aware length of stay prediction in multi-hospital settings. Sci Rep 16, 6564 (2026). https://doi.org/10.1038/s41598-026-37450-w
关键词: 住院时长, 不确定性量化, 置信预测, 贝叶斯建模, 医疗分析