Clear Sky Science · zh
通过临床词元优化提升大语言模型的医学知识表示
为什么更聪明的医学“阅读”很重要
在每一个医疗 AI 助手背后,都有一项看似简单却至关重要的技能:它如何把文本切分成能够理解的单元。当这种“切分”出错——尤其是在复杂的中文医学术语上——AI 可能会错过医生记录或患者问题中的关键信息。本文展示了对这一第一步做出小且有针对性的改动,如何在不重建整套系统的情况下,使大语言模型更擅长阅读、推理并回答基于中文医疗数据的问题。
以正确方式将文本切成块
现代语言模型并不直接“读”字符或词语;它们首先将文本转换为称为词元(token)的短单元。对于英语,这一做法较为有效,因为空格已经标示了词边界。中文更棘手:没有空格,很多医学表达是冗长且专业的短语。为英语设计的标准分词器往往把这些短语切成许多任意的片段。当模型看到一个疾病名或检验项被拆成若干不连续的部分时,就更难学会该术语的真实含义,其对医学问题的回答可能变得模糊或不准确。
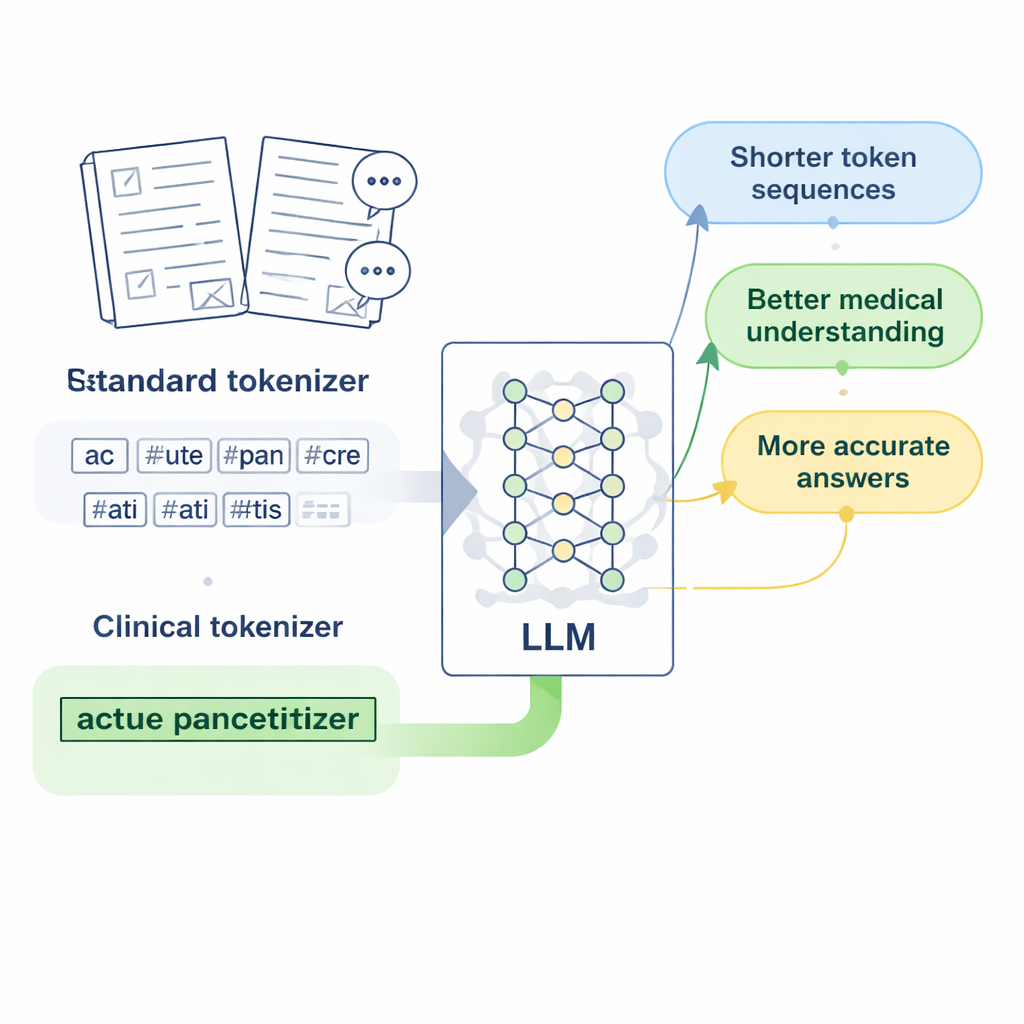
为中医药学设计“临床词元”
研究者以流行的开源大语言模型 LLaMA2 为对象,提出一个设想:如果我们仅仅教它的分词器一个更丰富的医学词汇表,会怎样?他们收集了大量中文医学文本,包括经人工整理的中医药数据库、数千条临床记录以及医患问答对。利用基于字节级的字节对编码(Byte Pair Encoding)变体,并借助 SentencePiece 工具,他们训练了一个新的分词器,使常见的医学表达能作为单个单元被保留。作者称这些新单元为“临床词元”,并将它们并入 LLaMA2 的原始词表,扩展模型对中文医学语言的覆盖,同时保留模型已有的知识。
从更好的词元到更强的医学模型
添加新词元只是第一步;模型必须为这些词元学到良好的表示。团队调整了 LLaMA2 的内部嵌入层,以便为扩展后的词表存储向量,并测试了两种初始化这些新向量的方法。一种方法是对每个词的旧子片段向量取平均,另一种则使用经仔细缩放的随机值。违反直觉的是,随机初始化方法表现更好,可能是因为它避免将模型锁定到对每个术语含义的糟糕初始猜测。随后,作者在医学文本上继续训练该模型,并使用一种资源高效的微调方法 LoRA,在指令式医学问答上进行微调,得到一个他们称为 Medical-LLaMA 的专用版本。
衡量速度、上下文和准确性的收益
通过扩展词表,每个中文字符现在大约只需之前一半的词元,这意味着模型可以在相同的固定词元窗口内处理更长的段落。实际上,有效的中文上下文长度大致翻倍,在大型医学问答集上的微调时间也几乎减少了一半。为评估回答质量,作者结合了两种评估策略:BERTScore(衡量生成答案与参考答案在语义上的接近度)和一个复杂的评分模型(DeepSeek-R1),其评估相关性、准确性、完整性和流利度。在这些指标上,Medical-LLaMA 持续优于原始的 LLaMA2 以及一个未包含医学专用词元的中文优化变体。它在识别医疗实体和临床文本分类等相关任务上也表现出小幅但稳定的提升,同时在非医学一般问题上的表现得以保留。
这对未来医疗 AI 意味着什么
对非专业读者来说,核心信息是:为 AI 配备更聪明的“阅读眼镜”——在此指更合适地切分医学语言的方法——可以显著提高其理解和回答健康相关问题的能力。通过将精心挑选的临床词元插入现有模型的词表,作者在不需要大规模重新训练或全新架构的前提下,提高了效率和准确性。尽管该工作仅限于一个 70 亿参数规模的模型和中文医学文本,但它提供了一个实用方案:针对领域定制语言处理的最早层,然后进行轻量化的再训练。这一策略可能有助于未来的医疗 AI 工具成为临床医生和患者更可靠的伙伴,尤其是在标准模型难以处理的语言和专业领域中。
引用: Li, Q., Tong, J., Liu, S. et al. Medical knowledge representation enhancement in large language models through clinical tokens optimization. Sci Rep 16, 6563 (2026). https://doi.org/10.1038/s41598-026-37438-6
关键词: 医学语言模型, 中文临床文本, 分词/tokenization, 临床词汇, 医学问答