Clear Sky Science · zh
生成式预训练变换器在日本国家兽医执照考试上的表现评估
为什么更聪明的兽医考试关系到每个人
每一次到动物医院的就诊背后,都有多年的严格训练和一场高风险的国家考试。在日本,有志成为兽医者必须通过国家兽医执照考试(NVLE),该考试涵盖从基础生物学到复杂临床判断的全部内容。本研究提出了一个及时的问题:当今先进的人工智能语言模型——也就是驱动流行聊天机器人的那类系统——能否用日语通过这项苛刻的考试?这对兽医教育和动物护理可能意味着什么?
在真实兽医执照考试上测试 AI
研究者将注意力集中在 OpenAI 的三代大型语言模型:GPT‑4o、o1 和 o3。尽管这些系统能够阅读并生成近似人类的文本,但它们并未针对兽医学进行专门训练。为了检验它们的能力,团队以日本第74届 NVLE(2023)作为基准。考试分为五个部分,包括仅文本的问题和展示 X 光片、照片或示意图的图像题。所有题目均为五项选择题,与学生实际参加的考试相同。研究者通过标准化的计算机脚本将每道题输入模型,并要求模型只以所选选项编号作答,不允许“解释”或通过对话争取分数。
哪种 AI 模型胜出?
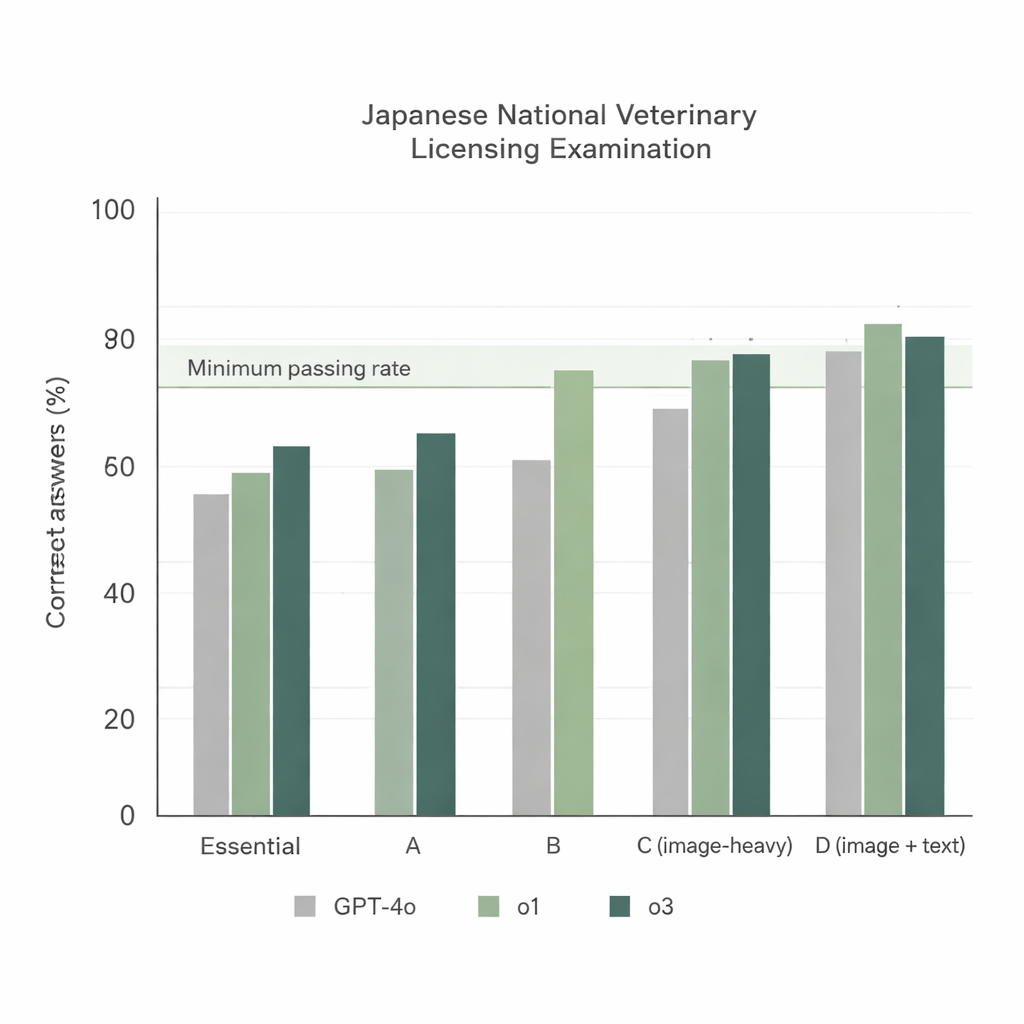
当三种模型以最简单的设置应对第74届 NVLE——日语题目和直接的指令提示——时,出现了两个明显趋势。其一,所有模型在基于文本的部分表现强劲,但 o1 和 o3 始终优于 GPT‑4o。其二,在以图像为主的部分表现有所下降,但 o1 和 o3 仍然高于官方最低合格率,而 GPT‑4o 在其中一部分未达标。总体而言,GPT‑4o 的正确率约为78%,而 o1 约为92%,o3 约为93%。由于 o3 在总分上略胜 o1,研究者选定 o3 作为后续实验的对象。
提示词或翻译真的有帮助吗?
关于“提示工程”——精心设计指令以引导 AI 给出更好答案——以及将本地试题先翻译成英语以匹配模型训练数据的做法,已有大量讨论。研究直接用 o3 模型测试了这些想法,比较了基础解题提示与更详尽、优化过的提示,以及日语题目与由同一模型先翻译成英语的题目版本。令人意外的是,这些变化并未带来显著差异:o3 在六种组合下均能轻松通过,而最简单的方法(原始日语题目配基础提示)与更复杂的设置一样有效。这表明,至少对于这些兽医试题,最新模型已经能可靠理解日语,且不需要复杂提示就能达到高水平表现。
在更新的考试上表现稳定吗?
为验证强劲结果是否偶然,研究团队随后用相同的日语题目和常规提示让 o3 作答第75届(2024)和第76届(2025)NVLE。该模型在两次考试中的总体得分均超过92%,并在包括图像密集部分在内的每个分项都超过合格线。三次独立运行中,大多数题目得到相同答案,表明即使允许一定随机性,o3 的回答总体也很稳定。对模型错误的细致分析显示,错误主要集中在两个领域:实践性兽医学知识(例如日本的兽医法规)和临床医学,这些领域需要依赖特定国家的规则与多步推理,而不仅是简单的事实记忆。
这意味着什么——以及不意味着什么
研究结论是,前沿的 GPT 型模型现在可以在不借助翻译技巧或复杂提示的情况下,用日语通过日本的兽医执照考试。对兽医学院和学生而言,这为将 AI 用作学习伙伴、题目生成器或考试主题解说工具打开了大门。对公众而言,这表明 AI 正成为组织和传播兽医知识的强大工具。然而,作者强调这些系统尚不能取代兽医或自行做出医疗决策。模型仍可能误解图像、在细微的临床判断上表现不佳,且有时会编造事实。谨慎使用下,它们可以成为兽医教育和信息支持中的有价值助力——但动物健康的责任仍将牢牢掌握在人类手中。
引用: Kako, T., Kato, D., Iguchi, T. et al. Performance evaluation of generative pre-trained transformer on the National Veterinary Licensing Examination in Japan. Sci Rep 16, 4306 (2026). https://doi.org/10.1038/s41598-026-37300-9
关键词: 兽医执照考试, 大型语言模型, 医学中的人工智能, GPT 表现, 日本兽医教育