Clear Sky Science · zh
K 折交叉验证中 K 值对监督学习模型偏差与方差的影响
为何对模型进行两次检验非常重要
从医疗诊断到信用评分,许多决策如今依赖于用历史数据训练的机器学习模型。但我们如何确认在屏幕上表现良好的模型在新的、未见过的样本上也能表现良好?一种常用的“测试”方法是 k 折交叉验证,即反复将数据划分为训练和测试部分。本研究提出了一个看似简单却极为关键的问题:要划分多少份——k 应该有多大——这一选择会如何悄然影响模型报告性能的可靠性?
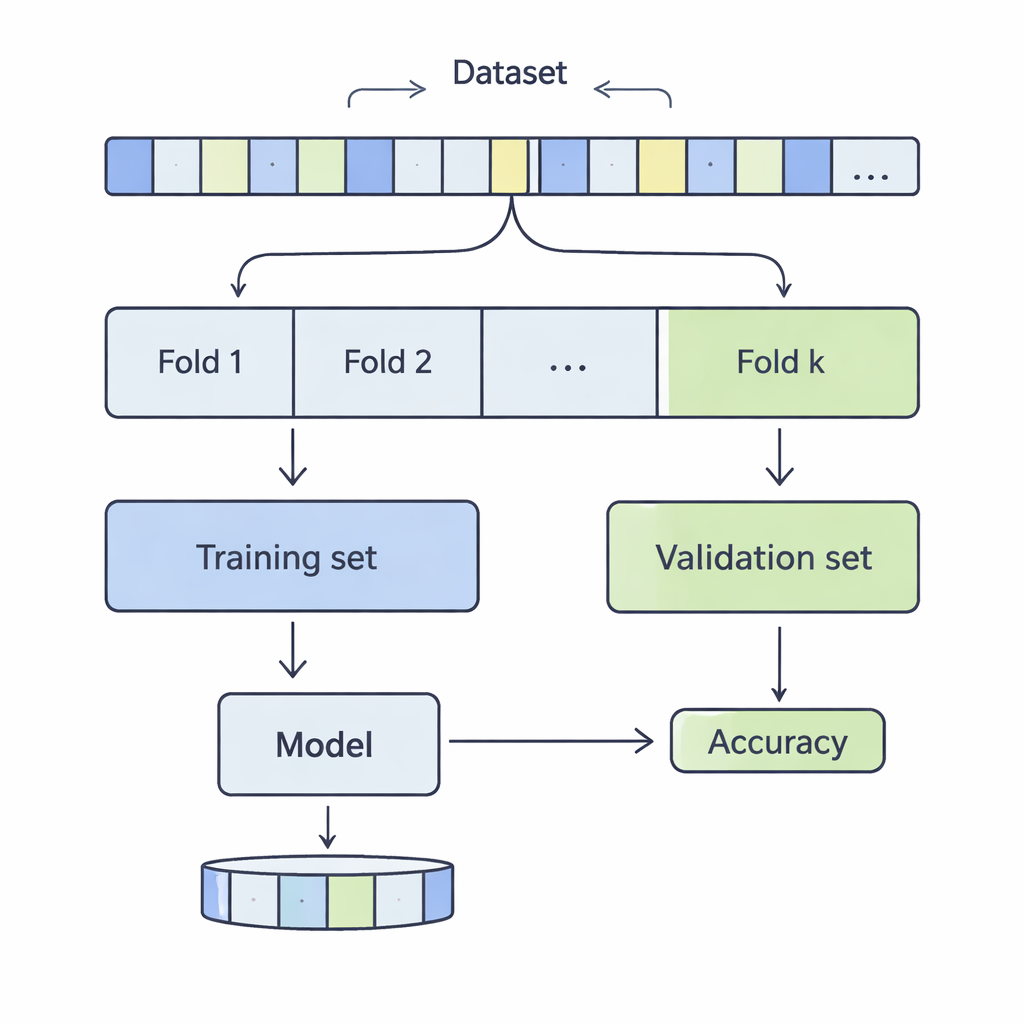
数据如何被切分以作现实检验
在 k 折交叉验证中,数据集被洗牌并分成 k 等份(fold)。模型在 k-1 份上训练,在剩下的一份上评估;这一过程重复进行,直到每一份都轮流作为测试集。作者考察了从 3 到 20 的 k 值,使用了 12 个真实世界的数据集,规模从几千条到超过五十万条记录不等,涵盖收入预测、医疗结局、网络攻击、游戏和葡萄酒质量等领域。他们应用了四种常见的分类方法——支持向量机、决策树、逻辑回归和 k 近邻(k-NN)——并仔细测量了 k 的选择如何影响性能的两个关键方面:偏差与方差。
用日常术语理解偏差与方差
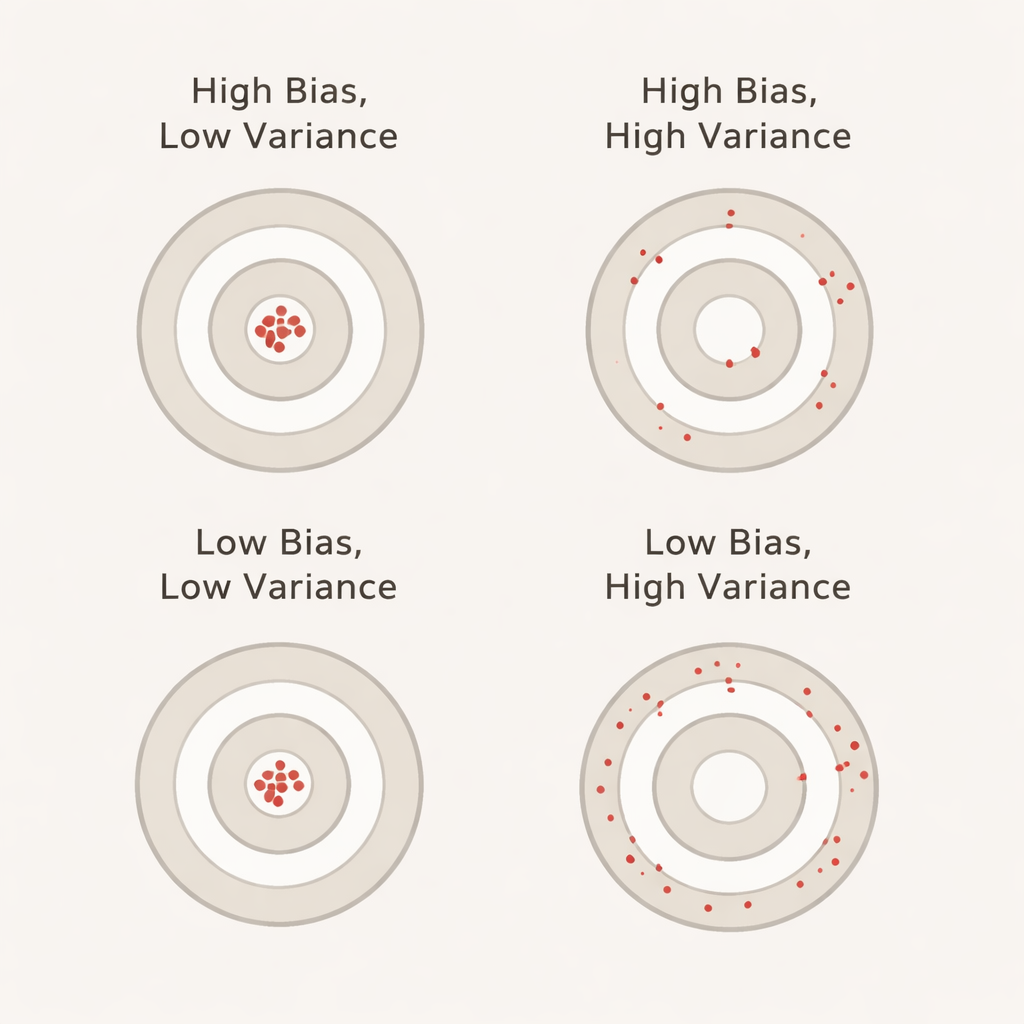
在此语境中,偏差衡量的是模型在交叉验证期间看起来比在独立未触碰的测试集上实际表现得更好的程度。较大的正偏差意味着在验证时对模型的评估过于乐观——类似于一个学生在练习测验中全都得满分,但在真正的考试中却失利。方差反映的是模型性能在不同折间波动的幅度:低方差意味着其分数在不同数据切片间较为稳定,而高方差意味着分数上下波动很大。理想情况下,我们希望偏差和方差都低,这样报告的准确率既现实又稳定。
随着折数增加会发生什么
在所有 12 个数据集和 4 种算法中,有一个明显的规律:随着 k 增大,方差几乎总是上升。换言之,使用更多的折会使得报告的准确率在折与折之间更不稳定。这一点与“更多折会自动带来更好、更可靠估计”的常见观点相悖。原因在于,当 k 很大时,每个验证切片变得非常小且代表性降低,结果更容易受数据中的偶然特征影响。与此同时,偏差的表现则不那么一致。对于 k 近邻和支持向量机,偏差通常随 k 增大而上升,意味着这些模型在交叉验证中往往看起来比在保留测试集上更准确。决策树的表现大体上较为平衡,而逻辑回归则处于两者之间,偏差变化混合但更为温和。
为何“标准设置”可能具有误导性
大多数实用指南简单地建议使用五折或十折,而不考虑数据集或学习算法的具体情况。作者的分析表明,这种一刀切的建议可能会产生误导。在某些数据集和某些模型上,较高的 k 值会放大对性能的过于乐观的印象;在所有情形中,更多的折都会带来估计的不稳定性。这在医疗、金融或基础设施等高风险领域尤其令人担忧,因为对模型准确性的虚假自信可能会带来真实世界的后果。研究认为 k 的影响既取决于数据的性质(小数据集 vs. 大数据集、噪声多 vs. 更干净)也取决于特定算法在接近相同的重复训练集上如何学习。
给所有使用机器学习者的要点
核心教训是:交叉验证中的折数不是一个无关紧要的技术细节——它直接影响你准确率数字的可信度。在这些实验中,更多的折持续使结果更为不稳定,并且常常让某些模型看上去比实际更好。作者建议不要盲目选择 k=5 或 k=10,而应将 k 视为一个可调的参数:在一个小范围的 k 值上检查结果如何变化,并在可能的情况下查看不止一个性能指标。对从业者和有兴趣的读者而言,信息很明确:在评估机器学习模型时,你切分数据的方式可能与模型本身同样重要。
引用: Abedin, T., Xu, H. & Uddin, S. The impact of K selection in K‑fold cross-validation on bias and variance in supervised learning models. Sci Rep 16, 6084 (2026). https://doi.org/10.1038/s41598-026-37247-x
关键词: k 折交叉验证, 偏差-方差权衡, 模型评估, 机器学习验证, 监督分类