Clear Sky Science · zh
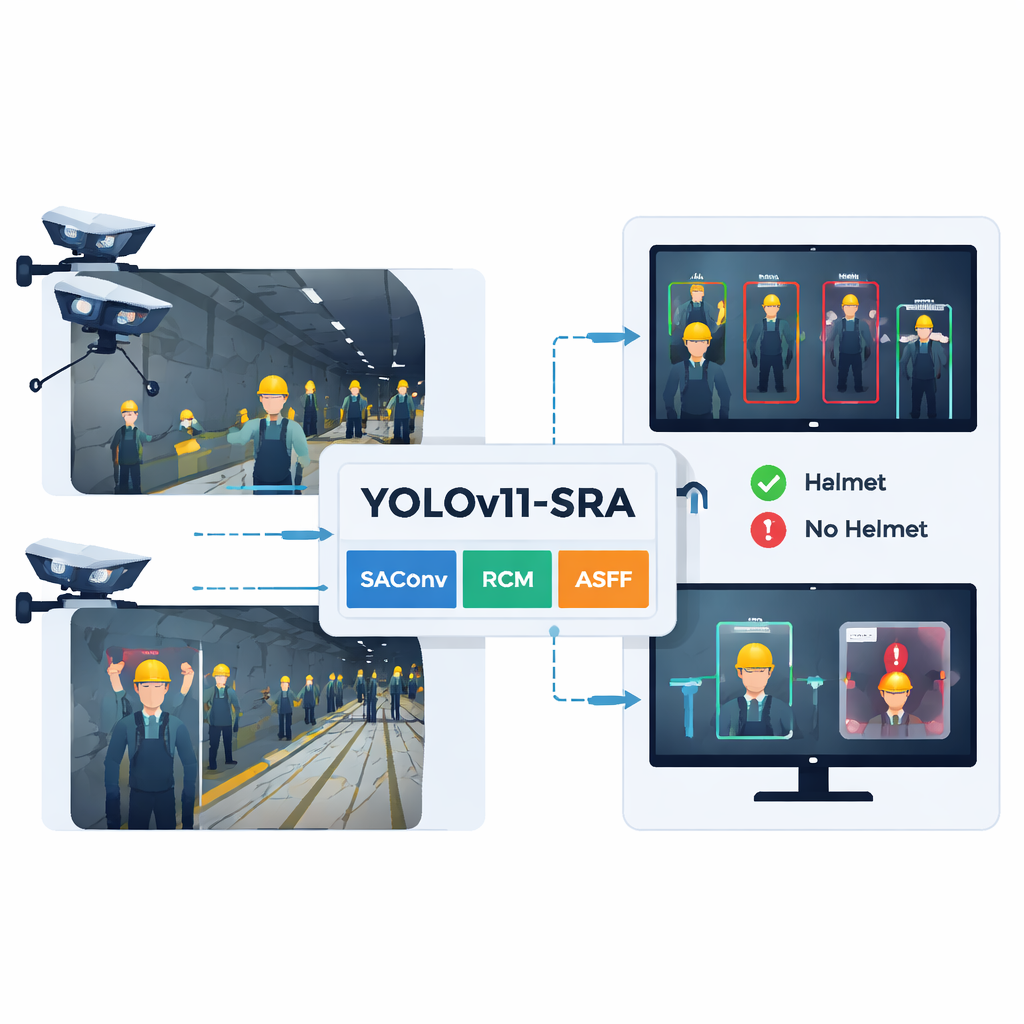
基于 YOLOv11-SRA 模型的地下安全帽检测方法
为什么在地下更智能的安全帽检查很重要
在矿井和隧道的深处,工人依赖安全帽作为防坠石、机械伤害和低顶棚的最后一道防线。然而在黑暗、多尘且通道拥挤的环境中,监督人员——甚至传统摄像机——都难以判断谁佩戴得当。本文提出了一种基于改进型 YOLOv11-SRA 模型的新型计算机视觉系统,能够在光线不足、视线被遮挡或人员远离摄像机的情况下,实时自动识别安全帽与裸露的头部。
依赖人工检查的风险
矿井中的传统安全帽检查仍主要依赖人员在隧道中巡查或依靠工人必须通过的闸机与检查点。这些方法速度慢、覆盖地点有限,并且一旦人员进入更深的地下区域,容易漏掉风险行为。带有标签或内置电子设备的传感型安全帽能提供一定程度的自动化,但成本高昂、在恶劣环境中难以维护,且需要对每顶安全帽进行改造。随着采矿规模扩大和班次延长,这些老方法难以提供预防事故所需的全天候、全矿区监控。
教会摄像机在艰难环境中识别安全帽
近年的深度学习进展改变了计算机解读图像的方式,尤其在识别汽车或行人等目标上。YOLO 系列算法被广泛采用,因为它可以在一次快速扫描中定位图像中的对象——非常适合实时视频。但地下场景对这些系统提出了更高要求。安全帽可能在远处仅显现为很小的彩色斑点,被管道或机械部分遮挡,或在昏暗、不均匀的照明下与背景融合。作者为应对这些问题设计了 YOLOv11-SRA,使矿区摄像机能够更可靠地区分有防护与无防护的工人。
对流行视觉引擎的三重升级
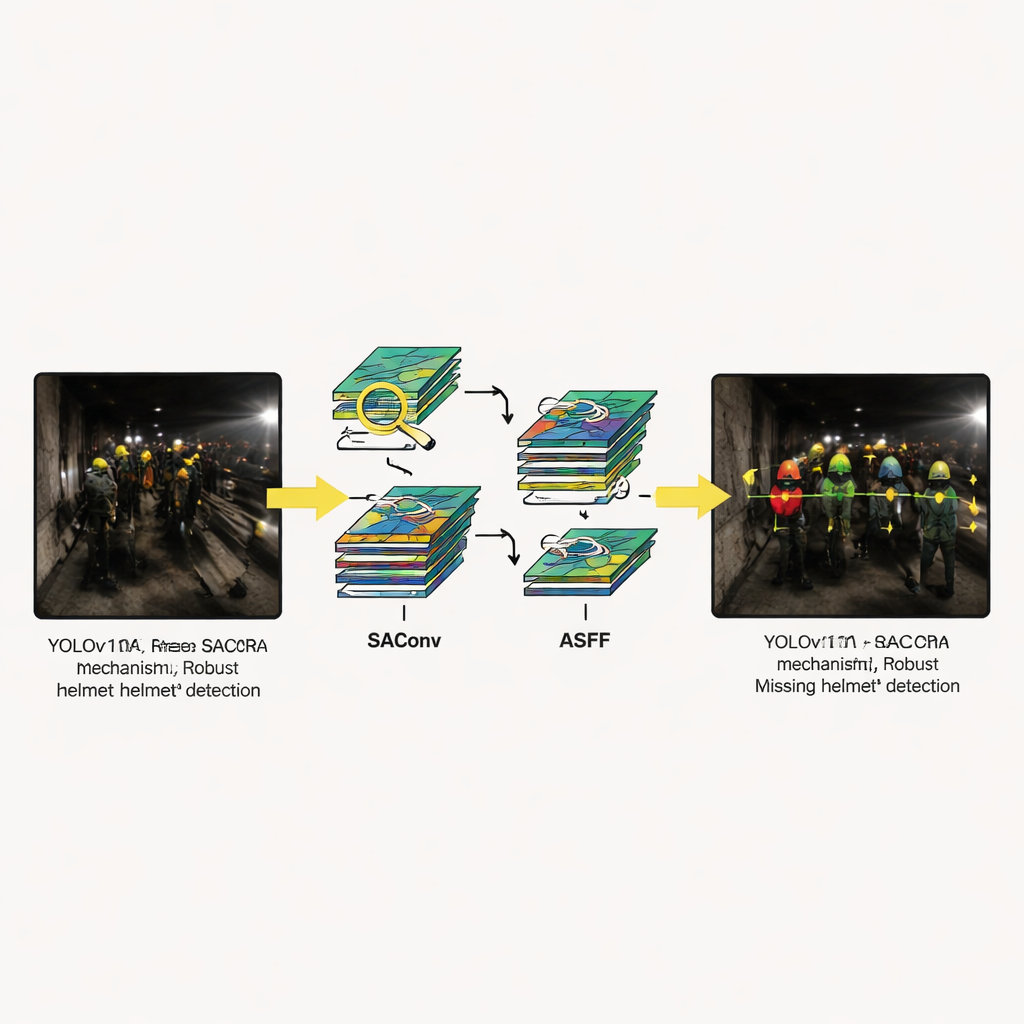
新模型保留了 YOLOv11 的总体结构——输入、骨干网络、neck 与检测头——但加入了三个专用模块。首先,SAConv 块使网络能同时以多个“缩放层级”观察图像,从而无需额外开销就能同时捕捉到小而远的安全帽和近处较大的安全帽。其次,RCM 块引导模型关注与隧道中人的头肩形状相匹配的长矩形区域,帮助在设备或其他人员遮挡时仍能追踪安全帽边缘。第三,ASFF 块融合来自多个尺度的信息,让系统按像素选择最能描述场景各部分的尺度。这些改进一起减少了安全帽与背景杂乱之间的混淆,并强化了对微小或部分可见安全帽的轮廓检测。
把系统付诸测试
为验证这些想法的实际效果,研究者在 CUMT-HelmeT 数据集上训练和测试了模型,该公开数据集包含标注为“有安全帽”和“无安全帽”的地下监控图像以及其他常见目标。由于原始数据集较小,他们通过裁剪、旋转和调亮图像扩增了五倍,以模拟不同的摄像角度和照明。在这个具有挑战性的基准上,YOLOv11-SRA 实现了约 84% 的平均精度(mAP)和接近 80% 的召回率,明显超过若干知名检测器,包括较新的 YOLO 版本、RetinaNet、SSD 和 Faster R-CNN。尽管精度提升,该模型仍然紧凑高效:相比多数竞争方法使用更少参数和更低计算量,在现代显卡上能接近每秒处理 100 张图像,满足实时报警的需求。
穿透黑暗、尘土与眩光
可视化示例展示了系统在那些经常使旧方法失效的场景中的表现:半遮挡的安全帽、仅由微弱灯光照明的画面、距离摄像机较远的工人以及来自光亮表面的强烈反光。在每种情况下,YOLOv11-SRA 都比竞争模型给出更有信心且更一致的检测结果。它更不容易漏检小而暗的安全帽,且在明亮斑点或管道颜色类似安全帽时更能避免误报。消融实验——在这些实验中作者开启或关闭单个模块——表明每一部分都能带来改进,但当三者共同使用时收益最大,证明该设计作为一个整体而非若干孤立技巧的集合更为有效。
从研究原型到更安全的班次
用通俗的话说,这项工作相当于为矿井摄像机赋予了更锐利、更具适应性的“视觉”,专注于基础防护装备。通过在嘈杂、低光的视频流中更可靠地标注未佩戴安全帽的工人,YOLOv11-SRA 系统可以帮助监督人员更早干预,降低头部受伤的风险。由于模型相对轻量,可部署在靠近摄像机的嵌入式设备上,而不仅仅依赖远端数据中心。作者指出,更多样化的训练数据和进一步的精简可能使方法更稳健,但现有结果已指向在现代地下采矿苛刻环境中更智能、更可扩展的安全监控方向。
引用: Wang, L., Wan, X., Shi, X. et al. A method for detecting safety helmets underground based on the YOLOv11-SRA model. Sci Rep 16, 6194 (2026). https://doi.org/10.1038/s41598-026-37148-z
关键词: 地下采矿安全, 安全帽检测, 计算机视觉, 实时监控, 深度学习