Clear Sky Science · zh
使用无监督探索的监督与集成模型在阿尔茨海默病预测中的比较分析
为何早期预警至关重要
阿尔茨海默病会在很长一段时间内悄然剥夺人的记忆和独立性,常常在确诊之前就已开始影响生活。当预警信号被尽早发现时,家庭、医生和医疗系统都能从中受益,因为此时治疗、计划和支持能发挥最大的作用。本研究提出了一个务实的问题:基于常规临床和脑部扫描信息精心设计的计算程序,能否比现有标准工具更可靠地发现痴呆症——同时揭示疾病发展中隐藏的模式?
将病历转化为可用信号
研究者利用了一个知名的数据集 OASIS-2,该数据集随访了 150 名年龄在 60 至 96 岁之间的老年人多年。每次随访中,数据包含年龄、受教育年限、社会经济状态等基本信息,以及认知测验分数和来自 MRI 脑部扫描的测量值,例如总体脑体积。在进行预测之前,团队对数据进行了清理,去除标识信息与模糊病例,填补少量缺失值,并将所有数值测量放到统一量表。他们还处理了一个关键的现实问题:数据集中健康人远多于痴呆者。为避免模型在训练时简单地总是猜“无痴呆”,研究者使用了加权方案,使得对较少数的痴呆组犯错在训练中被赋予更高的权重。
将经典工具与模型团队进行比较
在准备好的数据上,作者比较了常用的机器学习工具与更先进的“集成”方法,后者将多个模型组合成一个更强的预测器。经典方法包括逻辑回归、决策树、支持向量机和随机森林。集成方法则包含 AdaBoost、XGBoost 和一个融合了三种调优分类器的多数投票模型。所有模型都在数据的一部分上训练,并在保留的测试集上评估,性能通过准确率、正确识别痴呆个体的能力(召回率)以及 ROC 曲线下面积(衡量模型将健康与患病个体区分开的能力的综合指标)来判断。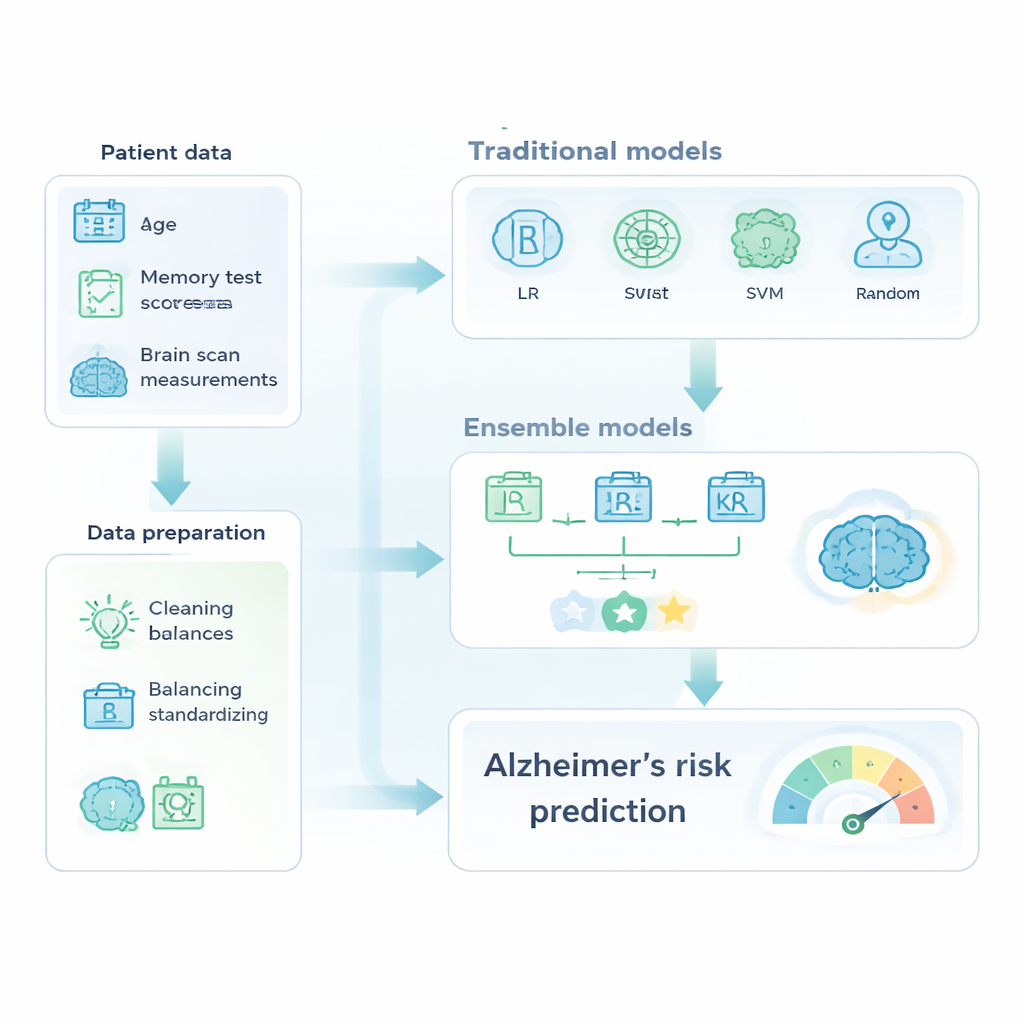
众人胜于一人
直接比较的结果很明确。虽然最佳的传统方法表现尚可,但其表现趋于平稳,与早期研究报道的水平相近,测试准确率在八成出头到中段范围。相比之下,多数投票集成模型的准确率约为 95%,并具有同样较高的 ROC 得分,超过了常被引用的 92% 基准。AdaBoost 和其他集成模型也优于任何单一传统模型。这种优势来自不同算法能捕捉到数据的不同特性;通过让它们“投票”,集成能平滑掉个别模型的特性与过拟合,从而带来更稳定的预测。代价是透明度降低:与简单回归或单棵决策树相比,集成模型的某一具体决策更难一眼看出原因。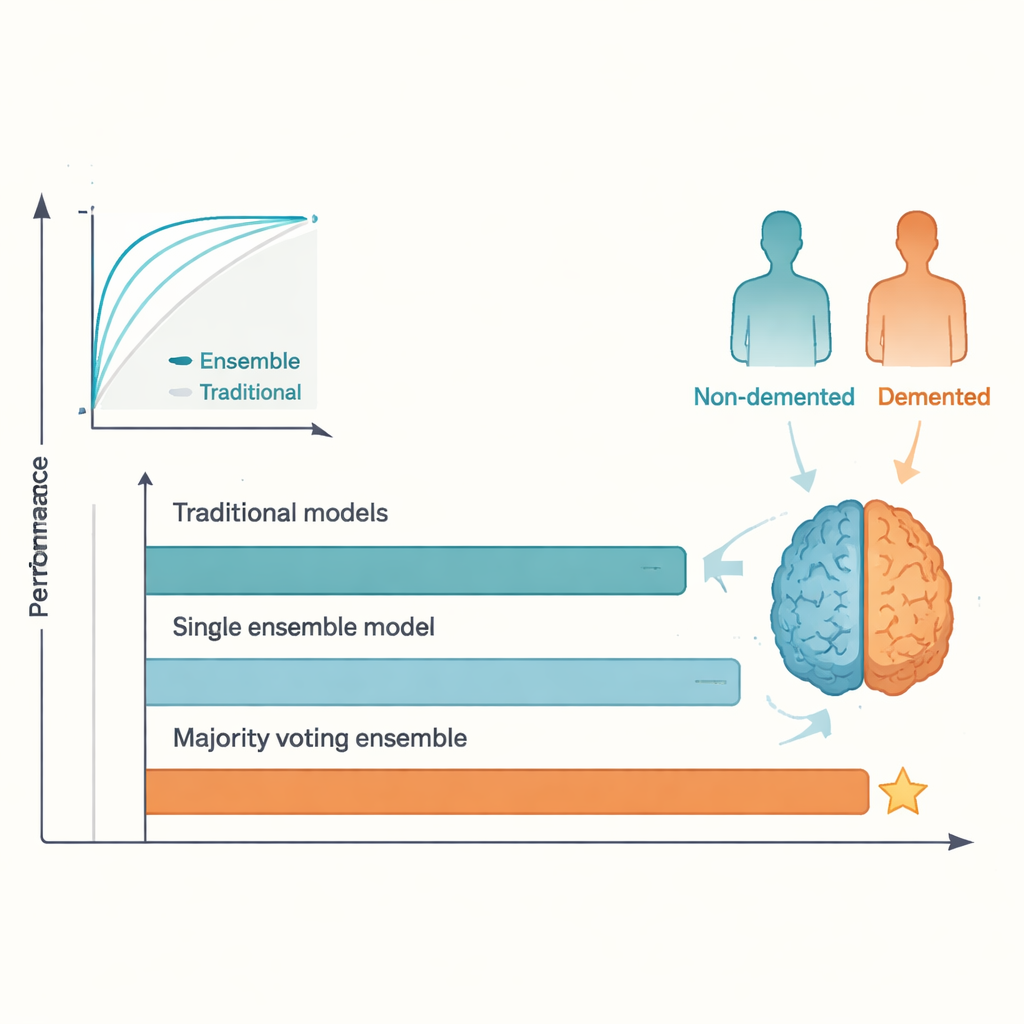
在数据中寻找自然分组
除了判断谁有痴呆外,研究者还探究患者如何在不参考诊断标签的情况下自然分组。为此,他们将所有连续变量转为有序类别——例如不同年龄段或脑体积区间——并应用一种称为多重对应分析的技术,将这些丰富信息压缩为少数潜在维度。随后使用 k-means 聚类将这些点划分为若干连贯的小组。有些簇以脑体积保存良好且认知评分正常的人为主,而另一些簇则包含脑体积低、测试成绩差且痴呆评分较高的个体。这些无监督簇与临床状态高度一致,表明数据中确实携带着关于疾病风险与进展的强烈且一致的信号。
这对患者和临床医师意味着什么
对非专业读者来说,结论很直接:经过周密设计的机器学习模型团队,能够在结构化临床数据中比旧方法更准确地识别与阿尔茨海默病相关的痴呆,而且可以使用许多诊所已在收集的信息。同时,探索性技术显示人群在脑健康与认知功能上呈现出不同的典型特征,暗示疾病可能走向不同的路径。尽管本研究受限于样本量有限以及解释集成模型复杂性的难题,但它表明将强大的预测能力与谨慎的探索性分析相结合,既能增强早期检测,又能加深我们对阿尔茨海默病如何发作的理解。
引用: Amr, Y., Gad, W., Leiva, V. et al. Comparative analysis of supervised and ensemble models with unsupervised exploration for alzheimer’s disease prediction. Sci Rep 16, 7322 (2026). https://doi.org/10.1038/s41598-026-37122-9
关键词: 阿尔茨海默病, 痴呆预测, 机器学习, 集成模型, 脑成像