Clear Sky Science · zh
基于自然语言处理的专家指派系统,用于玛丽·居里行动
为何选择合适的专家至关重要
当数千份研究提案争夺有限资金时,一切取决于谁来评审它们。如果被指派的专家并不真正理解提案的主题,有前景的想法可能会被误解或忽视。本文探讨了人工智能,尤其是现代语言处理系统,如何比现有基于关键词的工具更准确、更公平地将提案与最合适的专家匹配。
关键词清单的问题
迄今为止,像玛丽·斯克沃多夫斯卡-居里(Marie Skłodowska-Curie)博士后奖学金这样的欧洲主要资助计划在专家指派上高度依赖关键词。当前平台会扫描提案描述和评审人员档案以查找匹配术语,然后建议三位专家及备选人员。但主管副主席——负责监督流程的高级科学家——最终会更改约40%的这些指派。如此高比例的人为修正使系统劳动强度大、速度慢且不够透明,尤其是每年高达1万份提案涌入时,而固定关键词列表在新兴领域往往表现不佳。
像人类一样大规模“阅读”研究
作者开发了一个新的指派系统,试图像人类专家那样“阅读”研究。它不依赖标签,而是通过 ORCID(全球研究者识别系统)收集每位专家的论文,并构建了超过2,800篇文章摘要的数据库。然后将提案摘要和发表论文摘要输入 GALACTICA——一个专门在科学文本上训练的大型语言模型。GALACTICA 会将每个摘要转换为捕捉其含义(而不仅仅是措辞)的数值指纹。通过比较这些指纹,系统可以估算提案内容与每位专家既往工作的契合度。
三种汇总专业知识的方式
一个挑战是专家可能有数十篇出版物。系统需要为每位专家与每份提案给出一个单一评分,因此作者测试了三种简单的相似度合并方法。求和策略将所有相似度分数相加,奖励广泛和反复的相关性。乘积策略将它们相乘,强调在多篇论文间持续一致的相似度,但会对任何弱匹配进行严重惩罚。最大值策略仅保留单个最强的匹配,认为一篇非常相关的论文可能就足以证明指派的合理性。然后使用这些分数对每份181份提案的48位候选专家进行排序,并将这些排序与副主席最终选择的专家进行比较。
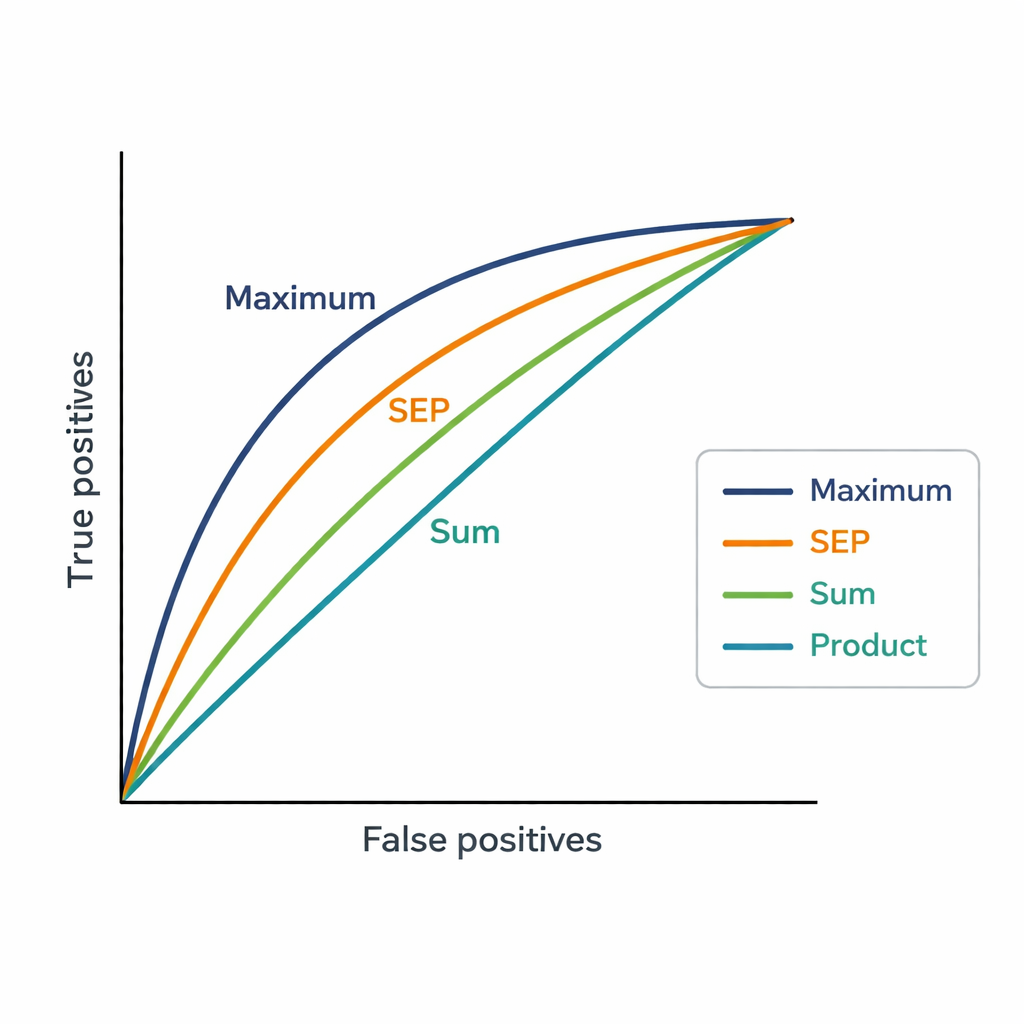
数字揭示了人类决策的特点
最大值策略与副主席的决策最为吻合,达到了0.82的AUC,优于现有基于关键词的系统(AUC为0.75)和其他汇总方法。实际上,副主席选择的专家通常会出现在最大值策略生成的前四个建议中。这表明,在指派评审时,人们倾向于关注是否存在专家既往工作与提案之间至少一项非常强的联系,而不是要求专家的所有出版物都一致地相关。新方法还生成比平台粗糙“亲和度”等级更细粒度的分数,使得在紧密排名的专家之间区分更加清晰。
这对未来资助评审意味着什么
对普通读者来说,结论很直观:通过使用能够理解科学语言的人工智能,资助机构可以更好地将提案与合适的专家匹配,减少人工修改,使流程更一致、更透明。虽然从出版物中汇总证据的不同方式会突显专业知识的不同方面,但简单的“最佳单一匹配”规则似乎反映了人类实际的决策方式。随着这些系统在更广泛的范围内并结合更新的语言模型进行测试,它们有望成为促进更公平、更高效的全球研究评估的重要组成部分。
引用: Álvarez-García, E., García-Costa, D., De Waele, I. et al. Expert assignment system based on natural language processing for Marie Sklodowska-Curie actions. Sci Rep 16, 6396 (2026). https://doi.org/10.1038/s41598-026-37115-8
关键词: 同行评审, 专家匹配, 研究资助, 自然语言处理, 大型语言模型