Clear Sky Science · zh
基于机器学习模型预测肺癌术后远处转移的比较研究
为什么预测癌症扩散很重要
即使外科医生切除了所有可见肿瘤,肺癌仍然是最致命的癌症之一。许多患者随后出现隐匿的癌灶,在大脑、骨骼、肝脏或其他器官处复发。医生希望在术后尽早识别出哪些患者更可能发生这种远处转移,以便个体化随访与治疗。本研究探讨了现代计算方法(即机器学习模型)是否能利用医院常规收集的信息来预测谁具有更高风险。
对大量患者的深入观察
研究者审查了来自中国一家癌症中心的3,120名Ⅰ至Ⅲ期肺癌患者的病历,这些患者均接受了肿瘤切除并至少随访两年。对于每位患者,研究团队收集了52类信息,包括年龄、性别、体重、吸烟史、影像学发现、手术细节、实验室检查以及术后是否接受化疗或放疗等。随访期间,596名患者发生了远处转移,2,524名未发生转移。这一真实世界的样本组合使团队能够识别与未来转移相关的特征。
教计算机识别风险模式
研究者没有依赖单一公式,而是比较了九种不同的机器学习方法,从简单的决策树到将许多弱模型组合起来的更先进技术。研究先用数学筛选方法将原始的52个变量缩减为更小且信息量更高的集合。随后,他们在重复的轮次中用部分数据训练每个模型,并在其“未见过”的患者上测试。由于约五分之一的患者发生了转移,他们在训练时作了平衡调整,以免模型简单地对所有人都预测“低风险”。研究用多项评估指标判断性能,包括模型区分高低风险患者的能力以及预测风险与实际发生的贴合度。
找到最可靠的模型
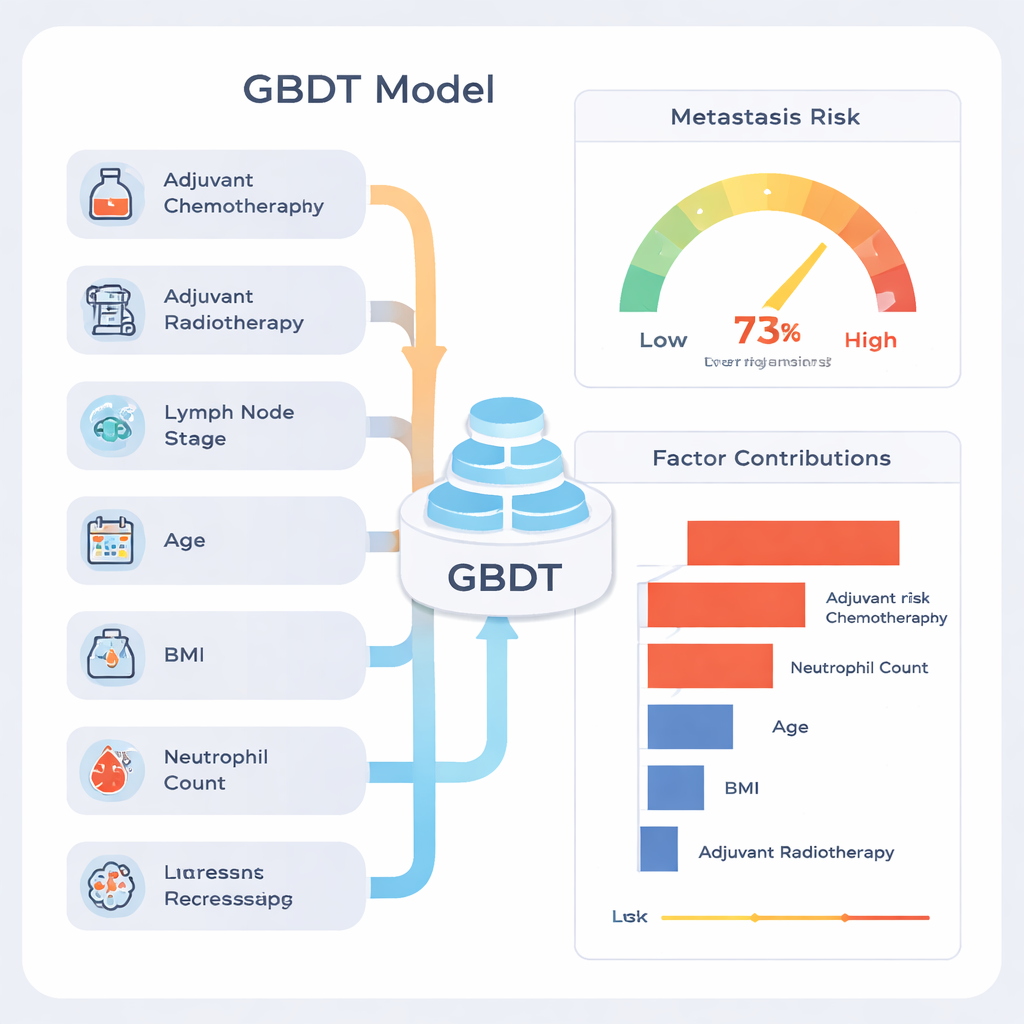
在九种方法中,一种称为梯度提升决策树(GBDT)的模型表现突出。在测试数据上,它对患者风险的总体排序准确率约为77%,其区分能力的汇总指标(ROC曲线下面积)为0.81,这在医学预测工具中被认为是很强的表现。该模型尤其擅长识别将保持无转移的患者(即高“阴性预测值”),意味着低风险结果通常令人放心。当团队在多次不同的随机数据切分上检验模型时,其性能保持稳定,表明该模型并非仅记住某一特定子集的偶然特征。
驱动模型决策的因素
机器学习常被批评为“黑箱”。为了解释模型,作者使用了一种叫做SHAP的解释方法,该方法为每个因素在每位患者最终风险估计中分配贡献值。分析显示,最强的信号包括患者是否在术后接受了化疗或放疗、受累淋巴结数量、年龄、体质指数(BMI)以及术前中性粒细胞计数(一种白细胞)。淋巴结累及更严重和系统性炎症征象的患者倾向于具有更高的预测风险。作者强调,化疗和放疗对风险的高贡献并不意味着这些治疗导致转移;相反,它们是临床上被判定为病情更具侵袭性的标志,因此这些患者术前就处于更高的风险。
这如何在临床中帮助患者
由于该模型使用的是大多数癌症中心已记录的信息,经进一步验证后可集成到医院软件中。对于刚做完肺部手术的新患者,系统可自动抓取其数据,输出个体化的远处转移概率,并给出哪些因素在推高或降低风险的简要说明。临床医生据此可决定谁需要更密集的影像随访、额外的随访咨询或临床试验入组,谁可以安全地避免强化监测。该研究仅在一家医院开展,因此该工具仍需在其他地区和医疗体系中验证和优化。但它为将常规临床数据与具有解释性的机器学习相结合以改善肺癌患者长期护理提供了有前景的蓝图。
引用: Guo, X., Xu, T., Luo, Y. et al. Comparative study on predicting postoperative distant metastasis of lung cancer based on machine learning models. Sci Rep 16, 6468 (2026). https://doi.org/10.1038/s41598-026-37113-w
关键词: 肺癌, 远处转移, 机器学习, 风险预测, 术后随访