Clear Sky Science · zh
种子质量标准文档的知识图谱构建与应用
为何种子规范关系到每个人的食物
每一袋大米或一包蔬菜种子背后,都藏着一套技术标准网络,这些标准在幕后保障作物产量与粮食安全。然而,这些种子质量规则通常散见于难以检索和理解的密集 PDF 文档中,对农民、监管者和企业来说并不友好。本研究展示了如何将那些静态文档转化为互联事实的“地图”——知识图谱,以使农业标准更透明、可检索,并为数字化农业时代做好准备。 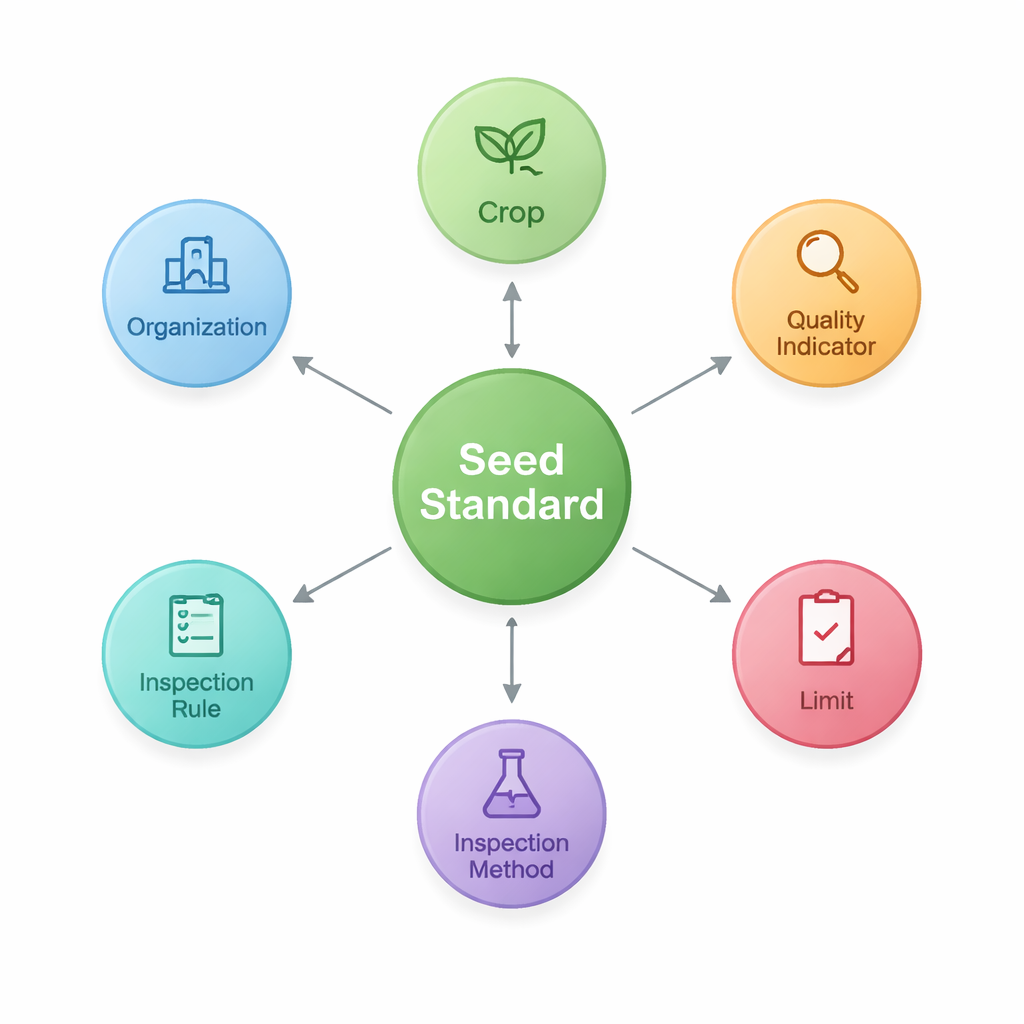
从纸质标准到智能信息
种子质量标准规定了何为合格种子:批次应达到的纯度、发芽率应达多少、允许的含水量以及用于检测这些性状的方法。在中国,此类文件数量激增,且许多仍以扫描页或非结构化文本存在。简单的关键词检索难以回答诸如“该作物的纯度限值是多少?”或“哪条规则替代了旧规则?”等实用问题。作者指出,为了跟上农业快速变化的步伐,这些标准必须从面向人的页面转向机器可理解的知识,以支持快速查询、比较和自动化校验。
构建种子知识的地图
为此,研究人员首先设计了一套“本体”——一种共享的蓝图,定义种子标准的主要构件及其相互关系。他们识别出七类核心实体,包括标准本身、其涵盖的作物、如纯度或发芽率等质量指标、这些指标的数值限值、检验方法和规则,以及起草或发布文档的组织机构。该结构捕捉了诸如“作物–质量指标–限值”之类的模式,这在农业领域尤为重要。基于这一蓝图,他们将提取出的事实以节点和链接的形式存储在图数据库(Neo4j)中,构建了包含2,436个实体和3,011条关系的网络。
规则与机器学习的结合
真正的挑战在于从杂乱的源文档中抽取干净、可靠的事实。种子标准混合了格式整齐的表格、规范的首页元数据以及冗长的自由文本条款。没有单一技术能全部搞定。因此,团队构建了一个混合抽取系统。他们使用精确的规则模式(正则表达式)读取倾向于严格格式的结构化表格和基本文档信息。对于更复杂的叙述性文本——例如详尽的检验规则——他们训练了一个现代语言模型流水线 BERT–BiLSTM–CRF 来识别关键名称、编码和技术短语。该模型通过精心标注的示例学习,即便在措辞多样或句子较长的情况下也能识别实体。 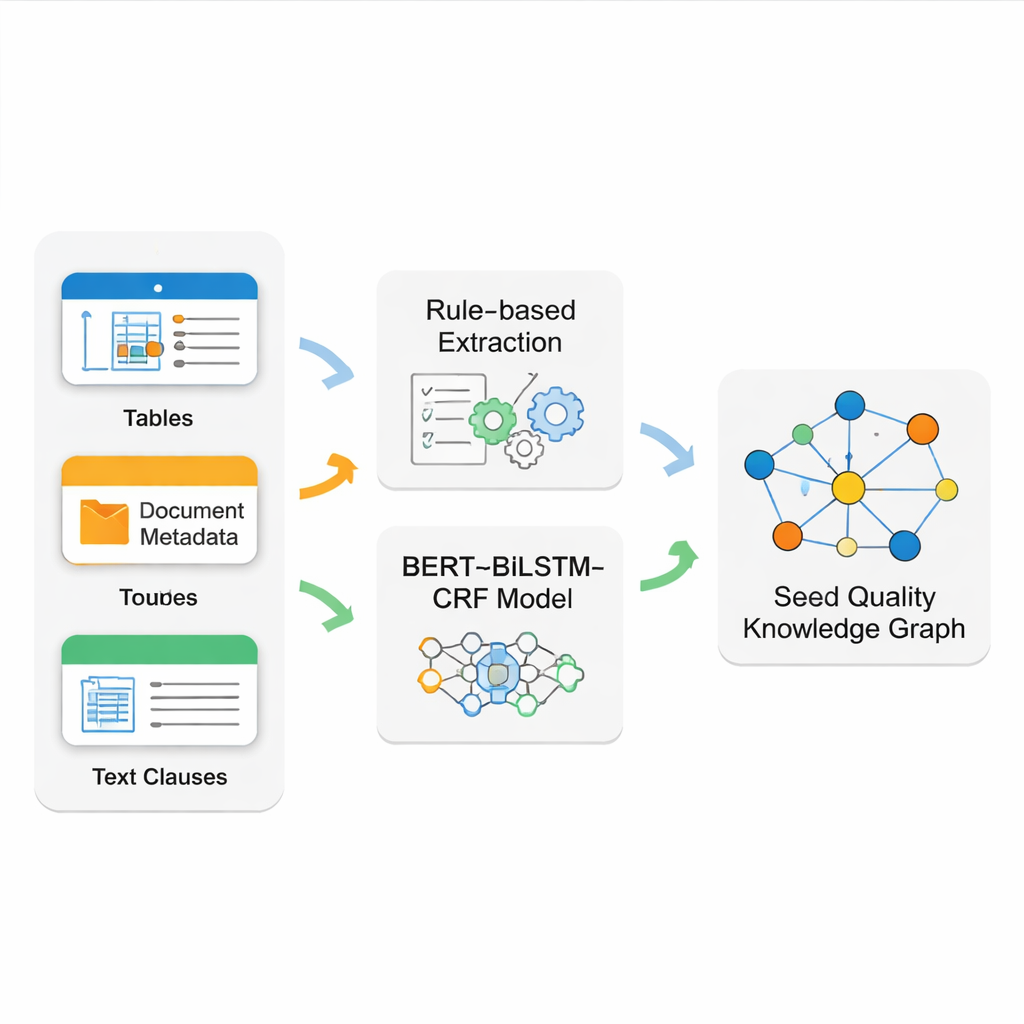
系统在实践中的表现如何
经测试,混合方法表现强劲。语言模型取得了约91.6%的总体 F1 分数(衡量准确性与完整性的平衡),超过了两种常用的基线模型。它在识别标准代码等结构化元素方面尤其出色,即便在处理诸如冗长检验规则等更难任务时也能保持稳健。一旦所有信息加载到知识图谱中,用户即可可视化地探索某一标准与早期版本的关系、起草单位、所涉作物与指标以及规定的检测方法。监管者和种子企业无需翻阅冗长的 PDF,就能在数秒内运行定向检索并查看关联结果。
这对农民和食物体系意味着什么
对非专业人士而言,结果是一种更智能的方式来管理保障种子可靠性和作物高产的规则。研究表明,结合清晰的概念设计与基于规则和基于学习的抽取方法,可以将分散的种子标准转化为连贯、可检索的知识库。这为计算机可读、可核验并能随法规变更而更新的“智能”标准奠定了技术基础。长期来看,此类工具可帮助农民与农业企业快速核实种子是否符合现行质量要求,支持监管者追踪修订和空白,并有助于提高收成稳定性与粮食安全。
引用: Yang, Z., He, Q. & Zhang, J. Construction and application of knowledge graph for seed quality standard documents. Sci Rep 16, 5997 (2026). https://doi.org/10.1038/s41598-026-37084-y
关键词: 种子质量标准, 知识图谱, 农业数字化, 命名实体识别, 智能标准