Clear Sky Science · zh
在标签噪声下可解释 AI 的解释漂移
为什么 AI 的解释可能在不知不觉中出错
现在很多人依赖人工智能不仅寻求答案,还寻求理由:为什么贷款被拒?为什么系统将一位患者标记为高风险?这项研究表明,即便 AI 模型的准确率看起来令人安心稳定,当训练数据包含错误时,它为做出决策所给出的“为何”可能会剧烈漂移。作者称这种隐藏的解释变化为“解释漂移”——它可能误导依赖 AI 来为重要决定提供理由的专业人员。
当干净的数据遇上混乱的标签
大多数现代 AI 系统是“黑箱”,只给出预测而不说明理由。为提高透明度,许多应用采用类似人类“如果——那么”推理的基于规则的模型:例如,“如果血压高且年龄超过 60 岁,则风险高”。这类规则集在医疗、法律和金融等敏感领域尤为受欢迎,因为用户需要检查并信任其逻辑。但现实世界的数据很少是完美的。一个常见问题是标签噪声——训练数据中所谓“正确答案”有误的情况,例如误记录的诊断或错误标注的客户结果。尽管人们已知标签噪声会损害预测质量,但其对 AI 解释稳定性的影响以前并未被系统地研究过。
测试解释在噪声下的稳健性
作者评估了在标签逐步被损坏时基于规则的解释能否保持稳健。他们使用了来自医疗、银行、肝病甚至数论的四个不同数据集,均设为二元(是/否)预测任务。比较了三种规则学习方法:两种流行且快速的算法(IREP 和 RIPPER)和一种计算开销更大的方法,称为人类知识模型(Human Knowledge Models,HKM),该方法旨在生成非常简单、类似人类的规则集。对于每种方法,研究人员反复训练模型,同时随机翻转不断增加比例的训练标签——从几乎干净的数据一直到接近完全无意义。他们并行跟踪两件事:模型在干净测试集上的预测表现,以及学习到的规则与无噪声数据下规则相比变化了多少。
准确性看似稳定,逻辑却在变动
表面上,结果可能让用户放松警惕。对于中等噪声水平,尤其是使用 HKM 方法时,用常见的 F1 分数衡量的预测性能似乎相对稳定。然而对规则集的更近一步观察却讲述了不同的故事。使用对规则集合进行比较的相似性度量,作者发现即使是适度的标签噪声也会迅速侵蚀原始解释与受噪声影响解释之间的重叠。换言之,模型在许多案例上的判断可能仍然正确,但其理由却越来越不同。更复杂的规则集尤其脆弱:当规则中的条件数量增加时,数据中的微小变化更容易使这些规则破裂或被替换,从而加速可解释性稳定性的丧失。
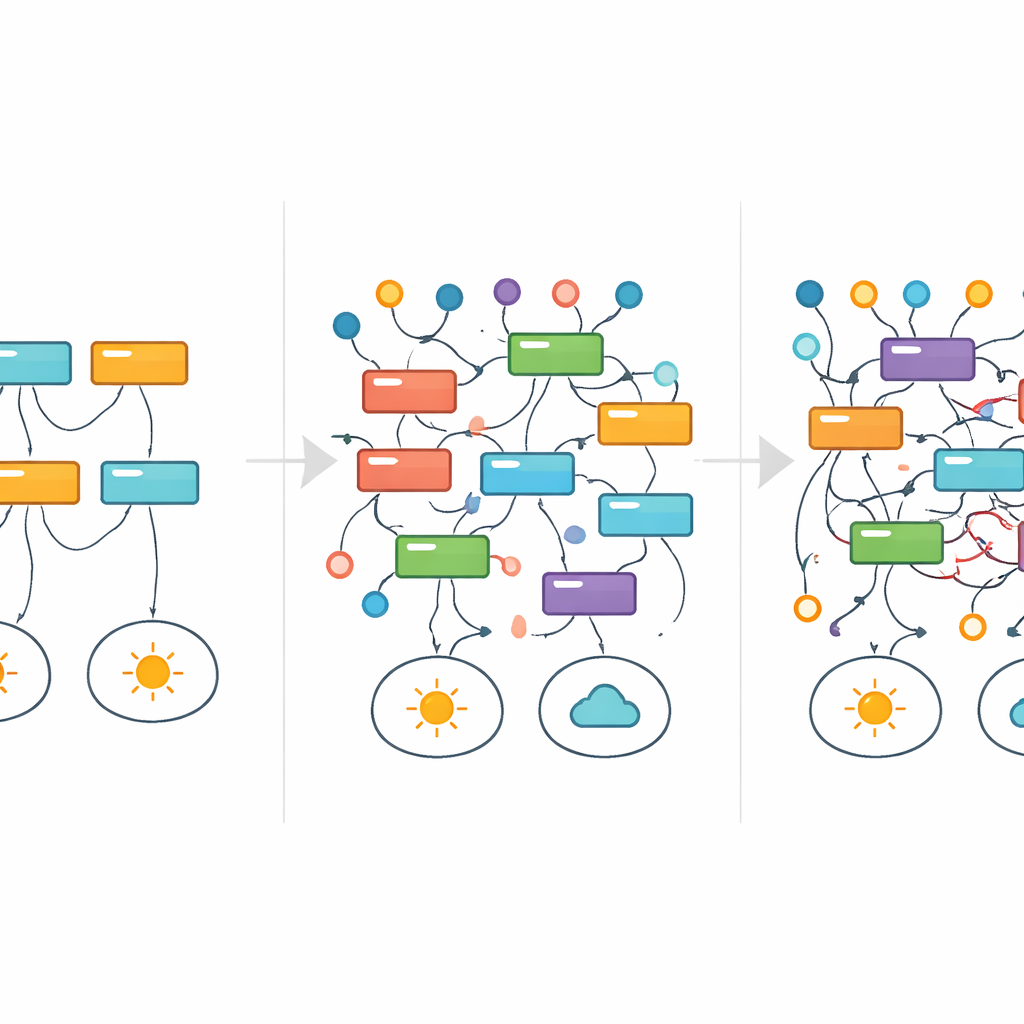
追踪规则的出现与消失
为了可视化随着噪声增加单个解释如何存活或失效,研究人员借用了医学中的一种工具:生存分析。他们不是跟踪患者随时间的存活,而是追踪随着标签噪声增加某条特定规则在最佳模型中持续出现的时长。许多规则并非缓慢消退,而是闪现进出——这表明在不同噪声水平下,完全不同的解释可能占主导,哪怕是针对相同的基础任务。例如,在一个简单的数字可整除性数据集中,干净且数学上正确的规则逐渐被更宽泛的近似规则取代,最终被仍能拟合被损坏标签的复杂且看似任意的模式替换。在这一过程的大部分时间里,主要的性能指标并未清晰发出任何异常信号。
对依赖 AI 的人的意义
核心信息是,“值得信赖”的 AI 不能仅凭准确性来评判。即便是以人类可读规则呈现其逻辑的模型,在所学习的标签不完美时也可能悄然改变其推理——而这正是大多数现实数据库中的常见情况。作者主张,开发者和监管者应将解释稳定性视为与准确性和公平性并列的一项一级要求。若要让 AI 系统对世界的叙述与其预测一样可靠,必须开发直接衡量模型解释在噪声下保持一致性的度量,并提供能提醒用户解释漂移的工具。
引用: Raikovskaia, A., Rakhimzhanov, N. & Pianykh, O.S. Interpretation drift in explainable AI under label noise. Sci Rep 16, 8528 (2026). https://doi.org/10.1038/s41598-026-37070-4
关键词: 可解释的人工智能, 标签噪声, 模型可解释性, 基于规则的模型, 解释漂移