Clear Sky Science · zh
从 CNN 到变换器与多模态融合:目标检测的演进
教计算机识别日常物体
每当你的手机在照片中标注朋友、汽车发现行人,或医生的工具在扫描中标出肿瘤时,一种强大而低调的技术在发挥作用:目标检测。本文综述解释了目标检测在过去十年中如何迅速演进——从早期的图像处理技巧发展到今天基于变换器和多传感器的系统——以及这些进展为何对更安全的街道、更智能的机器人和更准确的医学诊断至关重要。
从像素到可识别的事物
目标检测的任务是在图片或视频中定位并标注特定对象——汽车、骑行者、动物、医学结构等。文章首先描绘了该能力的广泛应用:自动驾驶、监控、医学成像和机器人等。早期系统依赖手工设计的规则来挑选形状和纹理,而现代方法则直接从数据中学习,借助深度学习。目前占主导的两大类方法是:卷积神经网络(CNN),擅长发现边缘和角点等局部模式;以及变换器,善于理解更广阔的场景和远处对象之间的关系。它们共同定义了当前机器“看”世界的方式。
经典视觉引擎的工作原理
基于 CNN 的方法仍然驱动着许多实时应用。它们用小型滤波器扫描图像,逐步构建出愈发丰富的特征图,然后将这些特征输入检测头以绘制边界框并分配标签。综述解释了两种主要策略。像 Faster R-CNN 的两阶段系统先提出可能的目标区域,然后对其进行精化,常常在精度上占优但计算代价较高。像 YOLO 系列的一阶段系统则跳过候选区步骤,在一次前向中预测框和标签,以速度换取一部分精度。近期的 YOLOv5 和 YOLOv8 版本经过大量调优——加入更智能的特征金字塔以处理小目标、为边缘设备设计的轻量化构件以及改进的损失函数——能够在保持在困难基准上有竞争力的同时达到数百帧每秒的速度。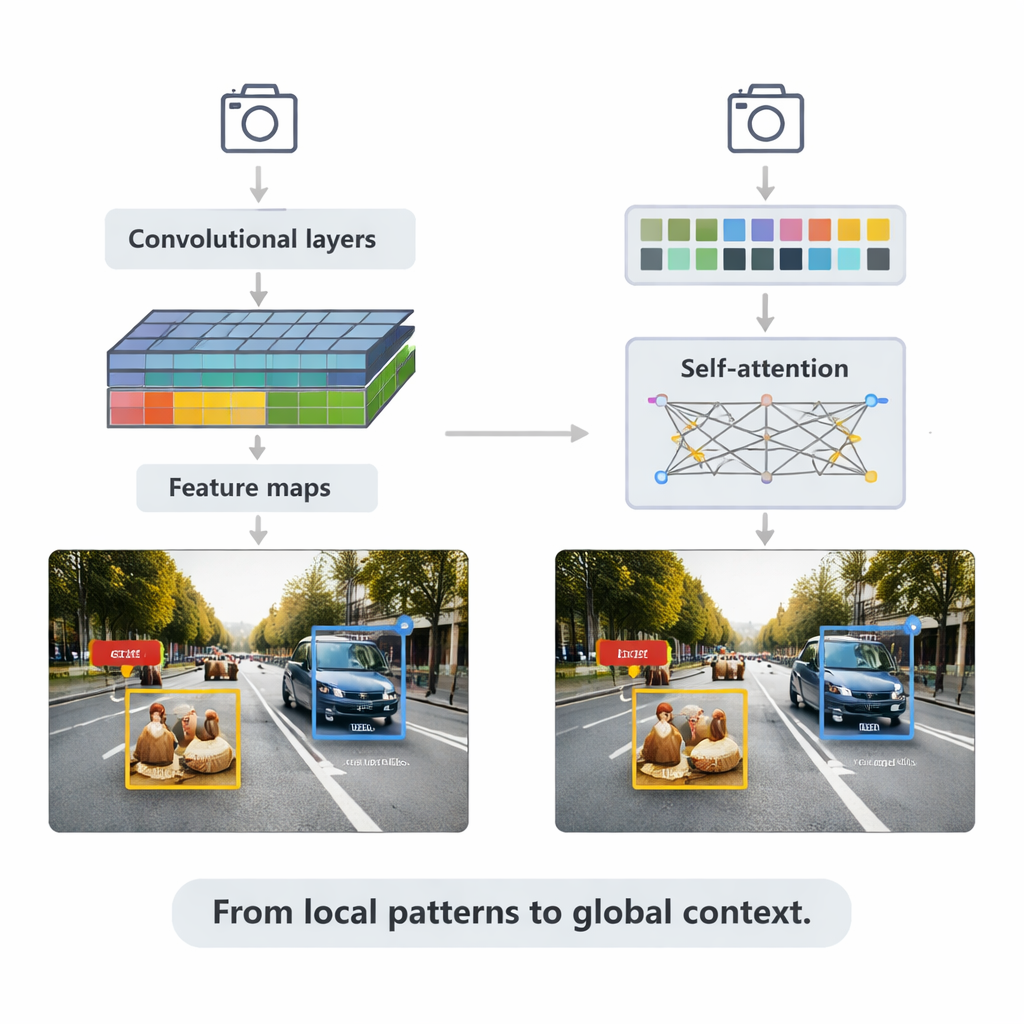
变换器与上下文的力量
文章随后转向变换器,这是一种从语言模型借用的新型架构。与只关注局部邻域不同,变换器使用“自注意力”机制,将图像的每个补丁与其它补丁进行比较,学习哪些区域对每个决策最为相关。Detection Transformer(DETR)及其后续版本去除了许多手工设计的技巧,力求更干净的端到端流程。Deformable DETR、RT-DETR 等变体减少了计算量并加快了训练速度,使变换器能够实时运行,同时在广泛使用的 COCO 基准上取得部分最高的精度分数。这些模型在复杂场景中表现尤为出色:当物体相互遮挡或背景混乱时,全局上下文有助于区分例如部分被汽车遮挡的行人。
融合相机、激光与语言
真实世界的条件——雾、黑暗、眩光、杂乱——常常会击败单一传感器系统。综述的一个主要关注点是多模态融合:将常规相机(RGB)、深度传感器如 LiDAR、热成像相机甚至文本描述的数据结合起来。作者提出了一个清晰的分类法来说明这种融合如何发生:早期融合在输入端混合原始数据,中期融合在网络内部合并学习到的特征,而晚期融合在末端结合各个检测器的输出。现代的“融合变换器”使用注意力机制对齐这些数据流,使得来自 LiDAR 的精确距离测量、RGB 图像的丰富外观信息和语言提供的语义提示相互增强。这种方法提升了自动驾驶、医学成像、视频理解以及富文本场景中的检测性能。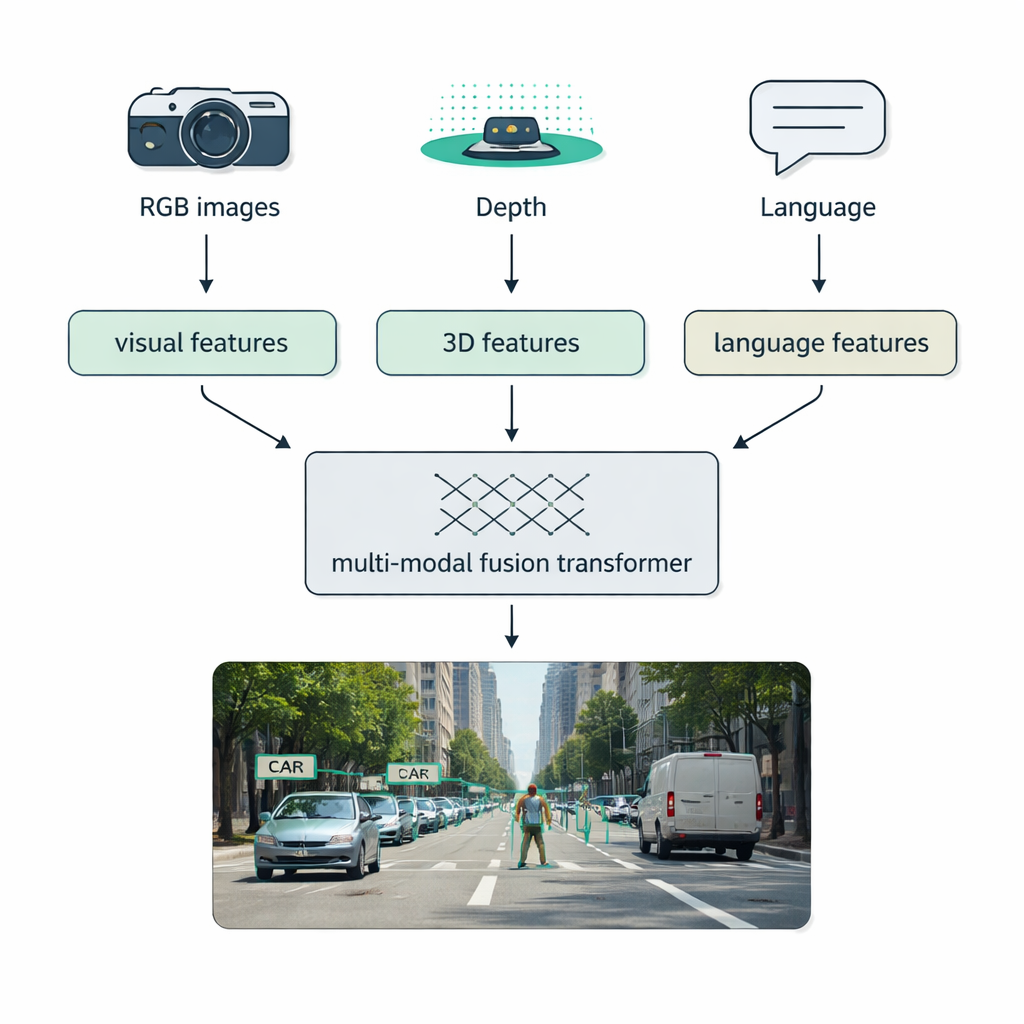
基准、极限与未来方向
在 MS COCO 等标准测试上,综述比较了 CNN 与变换器检测器的精度与速度。经典的两阶段 CNN 仍然强劲但较慢,YOLO 风格的模型在轻量级硬件上占优,而基于变换器的系统现在在精度上领先并正在缩小速度差距。专门的红外方法在低能见度条件下取得了很高的分数。然而仍有棘手问题:非常小或极大的物体、严重遮挡、变化的天气与光照,以及在微型设备上可靠运行的需求。展望未来,作者指出了朝向统一感知模型的趋势:同时处理检测、分割与生成描述,以及将视觉与语言融合的“基础模型”,能够识别用普通文本描述的对象,即便这些对象在训练数据中从未被标注。
这为何与日常生活相关
对非专业读者而言,核心信息是目标检测正从狭窄、手工调优的系统转向灵活的通用视觉引擎,能够适应新任务、新环境和新传感器。CNN 提供快速、有效的模式识别;变换器带来更全局、具有上下文意识的理解;多模态融合则结合了来自深度、温度和语言的额外线索。这些进步共同承诺:使汽车更能预见危险、工具帮助医生时更有把握、家庭设备与环境交互更安全、更智能——将机器感知推向接近人类视觉的丰富性。
引用: Wang, Z., Chen, Y., Gu, Y. et al. The evolution of object detection from CNNs to transformers and multi-modal fusion. Sci Rep 16, 7517 (2026). https://doi.org/10.1038/s41598-026-37052-6
关键词: 目标检测, 计算机视觉, 深度学习, 变换器模型, 多模态融合