Clear Sky Science · zh
使用大型语言模型从电子健康记录中判定移动功能状态
为什么行走能力是强有力的健康信号
随着人们寿命延长,医生不再只关注我们能活多久,还更关注我们能多好地移动、行走和自理。起身困难、爬楼梯或出行受限等问题常常在严重医疗事件发生前很久就出现。然而,关于一个人日常能力的最详细描述通常埋藏在电子健康记录中的医生和治疗师的自由文本笔记里,计算机难以检索。本研究考察了现代大型语言模型——与许多聊天机器人相同类型的人工智能——是否能够可靠地读取这些笔记,并将关于行动的描述转化为结构化、可检索的信息。
把混乱的笔记变成可用的移动数据
研究者关注“移动功能状态”,这是一个涵盖个人改变体位、行走、搬运与处理物品、使用交通工具以及日常生活中移动能力的广泛术语。他们使用了来自明尼苏达州和威斯康星州三家医疗机构的600条真实临床笔记,大部分来自物理治疗和职业治疗的就诊记录,还有一部分来自更通用的门诊记录。专家注释员逐段审阅每条笔记,标记每一段描述五类移动能力之一的内容,并指出患者是否明确受限(“受损”)或功能正常(“未受损”)。这些专家标注作为评估AI系统的黄金标准。
如何训练AI像临床医生一样阅读
团队使用了开源大型语言模型Llama 3,并在本地受控服务器上运行,以确保患者数据不离开医疗系统。他们没有从零开始重新训练模型,而是精心设计了提示——一套书面指令和定义——来教模型要寻找的内容。他们尝试了“零样本”提示(仅给出指令)和“少样本”提示(还包含少量示例笔记)。随后分析模型出错的地方,并制定了一个“基于错误的”提示,明确说明应包含什么、应忽略什么(例如未来的治疗计划),以及如何处理诸如跌倒、头晕或使用轮椅等复杂情况。模型被要求对每条笔记的每个段落和每个移动类别判断是否提到了移动能力,如果提到了,再判断患者是否受损。
在患者层面表现良好并持续改进
与专家标注相比,经过优化的系统表现良好。在整个患者层面——将该患者的所有笔记信息汇总后——AI在检索移动信息方面的F1值(一个常用的准确性衡量)约为0.88,在判断患者是否受损方面约为0.90。这意味着其判断与人工审阅者高度一致。在查看单个笔记段落时表现略低,因为段落措辞可能简略或含糊,但当信息在整条笔记内汇总,再在该患者的所有笔记中整合时,准确性有所提高。在第二项分析中,研究者将“临床上合理的推断”计为正确——例如,即使笔记未明确表述,也可推断出严重膝痛在行走时很可能限制行走。在这种更宽松的标准下,患者层面的提取F1值超过0.96,受损分类的F1值超过0.95。
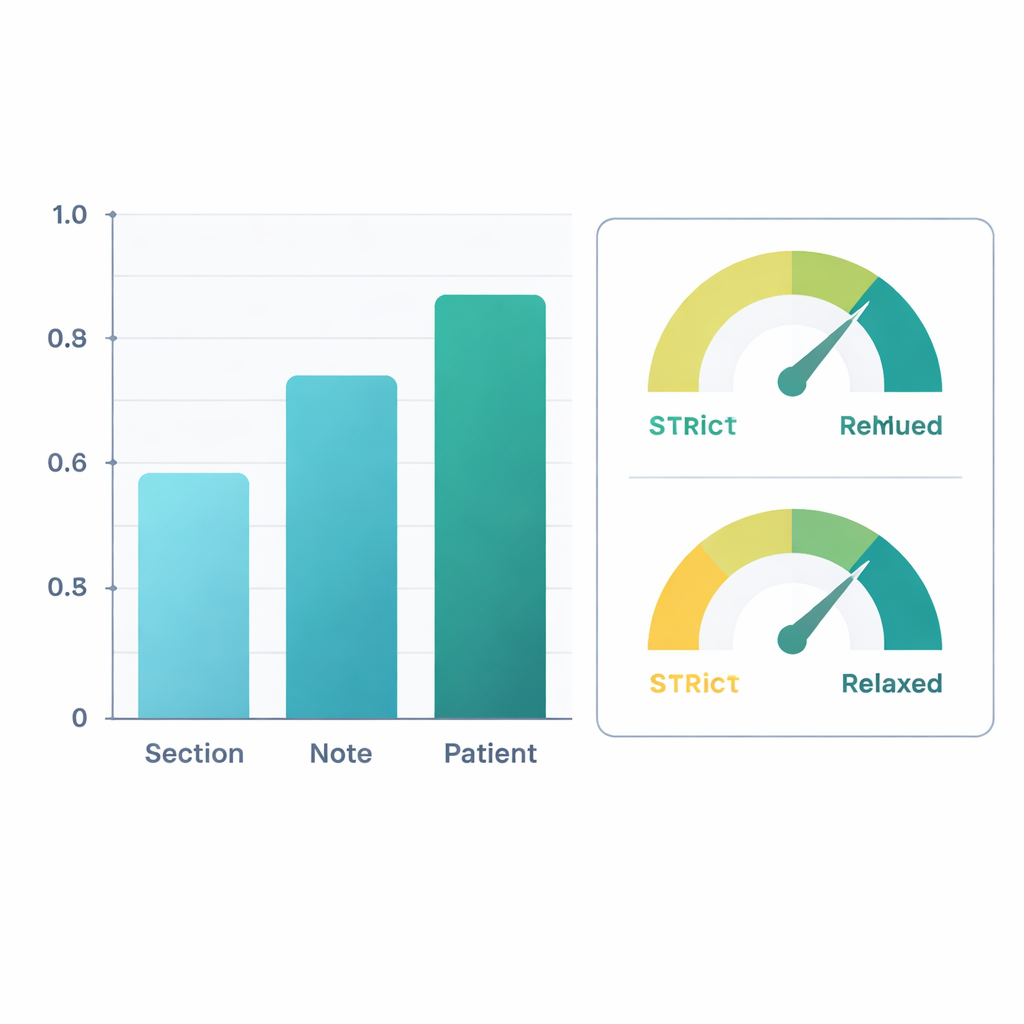
AI出错的地方——以及这些错误为何仍有意义
大多数错误来自模型的“读懂弦外之音”。它常常基于疼痛、头晕或未来的治疗计划推断出移动问题,即便笔记中并未明确指出患者受限。其他错误反映了定义中的灰色地带,例如是否应将反复跌倒视为行走问题或视为改变体位时的平衡问题。被称为“移动,未指明”的类别——用来涵盖日常活动与锻炼——尤其难以界定。尽管存在这些问题,错误通常在临床角度来看是合情合理的,而非随机或荒谬的。通过在锁定的本地服务器上以确定性方式(不引入随机性)运行模型,团队还确保了结果的可复现性并保护了患者隐私。
这如何改变老年人的护理
对普通读者来说,结论是:现在AI系统可以足够好地读取常规医生与治疗师的笔记,总结患者的移动能力以及他们在哪些方面存在困难。这意味着医疗系统可以在不增加新问卷或测试的情况下,追踪行走、平衡和日常活动随时间的变化,识别高跌倒或住院风险的人群,并找出可能受益于物理治疗或居家安全评估的对象。通过将数百万条自由文本笔记转化为结构化的移动性数据,这种方法帮助医生更全面地了解老化和疾病如何影响日常生活——使医疗更接近真正以功能为中心的个性化医疗。
引用: Liu, X., Garg, M., Jia, H. et al. Mobility functional status ascertainment in electronic health records using large language models. Sci Rep 16, 6045 (2026). https://doi.org/10.1038/s41598-026-37025-9
关键词: 移动能力, 电子健康记录, 大型语言模型, 功能状态, 临床人工智能