Clear Sky Science · zh
用于评估大型语言模型在与患者对话中诊断提问效率的基准
为何更聪明的医疗提问很重要
当你看医生时,最初听到的诊断很少来自你提到的单一症状。相反,医生会提出一系列跟进问题——关于时间、强度、相关问题等——以逐步缩小可能的病因。尽管当今的人工智能系统十分强大,但大多数测试仍把它们当成做选择题的对象,而不是与真实人交流。本论文提出了 Q4Dx,一种新的评估方式,用来判断大型语言模型(LLM)能否扮演“好奇的医生”:以恰当的顺序提出恰当的问题,从而高效地得到正确诊断。
从考试题到真实对话
现有的大多数医学 AI 测试给模型的是结构完备、像教科书一样的病例,并要求模型选出诊断。那能显示系统“知道”什么,但无法反映它在与可能忘记细节或用日常语言描述症状的患者进行混乱、真实对话时会如何表现。作者认为这是一个严重的盲点。在临床中,信息往往缓慢而且不精确地浮现;优秀临床医生的能力既体现在他们已有的知识上,也体现在他们会问什么问题。Q4Dx 的设计旨在弥合这一差距,将关注点从静态问答转向随时间推进的提问策略。
构建逼真的患者故事
为创建这一新测试平台,研究者从一个经过策划的医学资源出发,该资源将特定疾病与典型症状集合关联起来。他们随机选取了 100 对此类疾病—症状对,然后利用 AI 模型将枯燥的症状列表转换为听起来更自然的患者自述——类似人们在诊室里真实会说的故事。从每个完整病例,他们生成了较短的版本,其中只有大约 80% 或 50% 的关键症状被提及。这种受控的信息“隐藏”使他们能够研究在重要线索缺失或仅被暗示的情况下,不同模型如何适应。对症状重叠的检查证实,较短版本确实包含较少可用信息,而不仅仅是更少的词语。
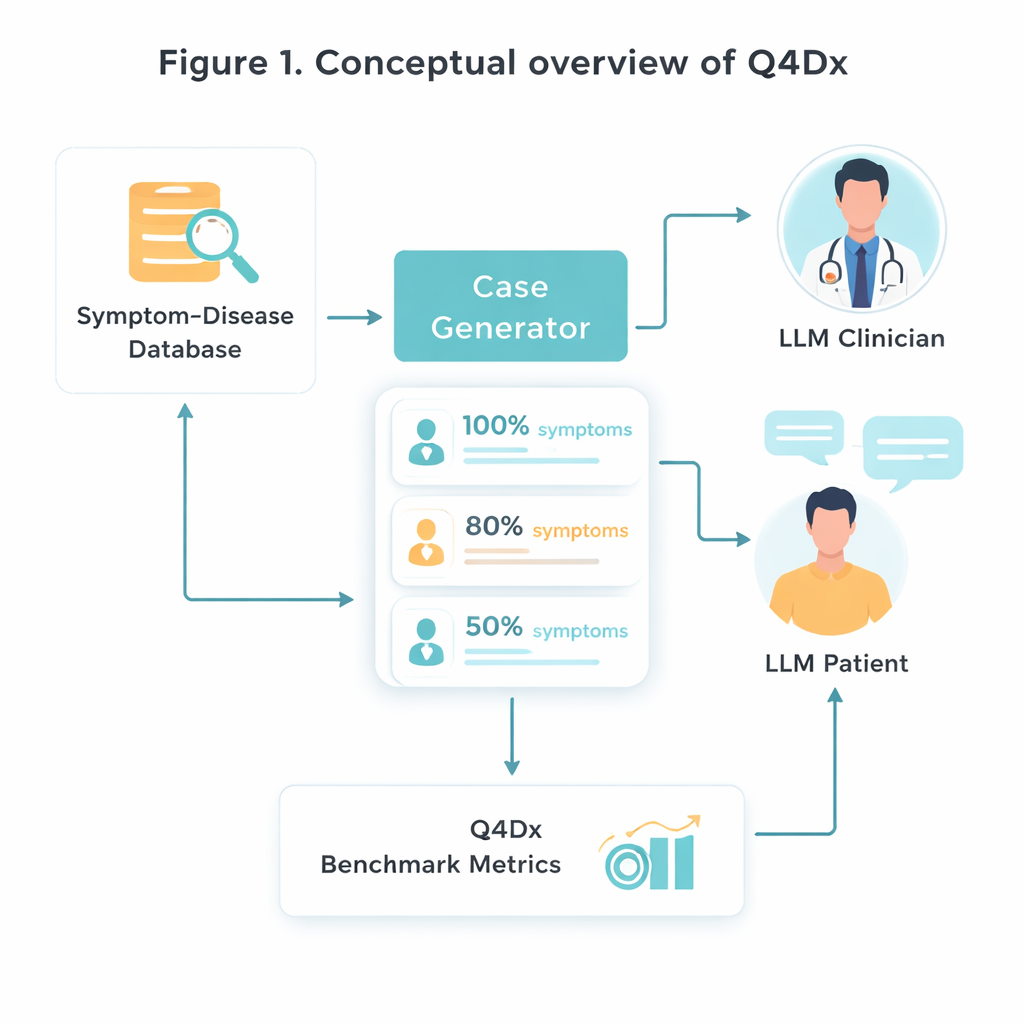
模拟的医患对话
Q4Dx 的核心是一大批由两个 AI 代理生成的模拟对话。其中一方扮演患者,完全掌握基础疾病及其完整症状集合;另一方扮演医生:起始时仅看到部分且可能模糊的病例描述,必须决定接下来要问什么。在每次患者回复后,医生代理都会给出一个临时诊断,记录出其思路如何一步步演进。通过记录所有问题、回答和中间猜测,基准不仅捕捉模型是否正确,还捕捉它是如何得出结论的。这些 AI 生成的问题序列被用作参考策略——不是完美的医学真理,而是一个一致的标尺,可用于比较未来模型甚至人类学员的表现。
衡量好问题,而不仅仅是正确答案
为评判表现,作者设计了三项简单但互补的度量。零样本诊断准确率(ZDA)问:如果事先给模型完整病例,它能否立即说出正确疾病?首次正确诊断所需平均提问数(MQD)反映效率:平均而言,模型在首次给出正确诊断前需要问多少个患者问题,最多计入五个问题?审问序列效率(ISE)则考察提问路径本身的质量——模型所选问题在含义上与参考序列有多相似。利用这些指标,团队展示了一款强大的通用模型(GPT‑4.1)在信息完整时约有一半的诊断正确率,但随着症状被隐藏其准确率下降。与此同时,其交互式会话通常在几个恰当的问题后就能成功,且随着轮次推进,其问题与专家式策略的对齐度也在提高。

这对未来医疗 AI 有何意义
对非专业人士来说,这项工作的要点很直接:在医学中,提出聪明的问题与拥有正确答案同样重要,AI 需要在两者上都被评估。Q4Dx 提供了一个可重复使用、公开可用的框架,正是为此而设计。通过提供带有不同程度缺失信息的真实患者故事、详尽的对话轨迹以及清晰的准确性和效率度量,该基准使研究者能够在受控条件下比较不同的 AI 系统,甚至将其与人类临床医生相互对照。随着时间推移,像 Q4Dx 这样的工具可以帮助训练更安全、更可靠的临床助理,并改进医生和学生的诊断访谈学习——最终为真实患者提供更好的护理。
引用: Werthaim, M., Kimhi, M., Apartsin, A. et al. A benchmark for evaluating diagnostic questioning efficiency of LLMs in patient conversations. Sci Rep 16, 6121 (2026). https://doi.org/10.1038/s41598-026-37022-y
关键词: 医疗人工智能, 诊断推理, 临床对话, 大型语言模型, 提问策略