Clear Sky Science · zh
在工作室与真实世界数据集上对自伤检测动作识别模型的基准测试
用数字之眼守护患者
在精神病院,护士日以继夜地工作以保障患者安全,尤其是那些有自伤风险的患者。然而,即使是最尽责的人员也无法在每个房间、每一秒都保持盯守。本文研究是否可以借助人工智能(AI)自动扫描病房摄像头视频,识别自伤的早期迹象——为人类护理提供额外保护层,而非取代人工护理。
为何自伤难以发现
自伤——指人们对自己实施的任何故意伤害——常发生在短暂且隐蔽的瞬间:被褥下的一次快速划伤,或看不见处使用的一件小工具。精神病房依赖定期查房和摄像监控,但盲区、人员疲劳以及夜间或节假日的有限值守使得持续监控成为不可能。同时,记录和共享真实患者影像带来了严重的隐私与伦理问题。因此,研究人员几乎没有足够真实的视频来训练能够实时检测危险行为的AI系统。
为AI构建更安全的测试平台
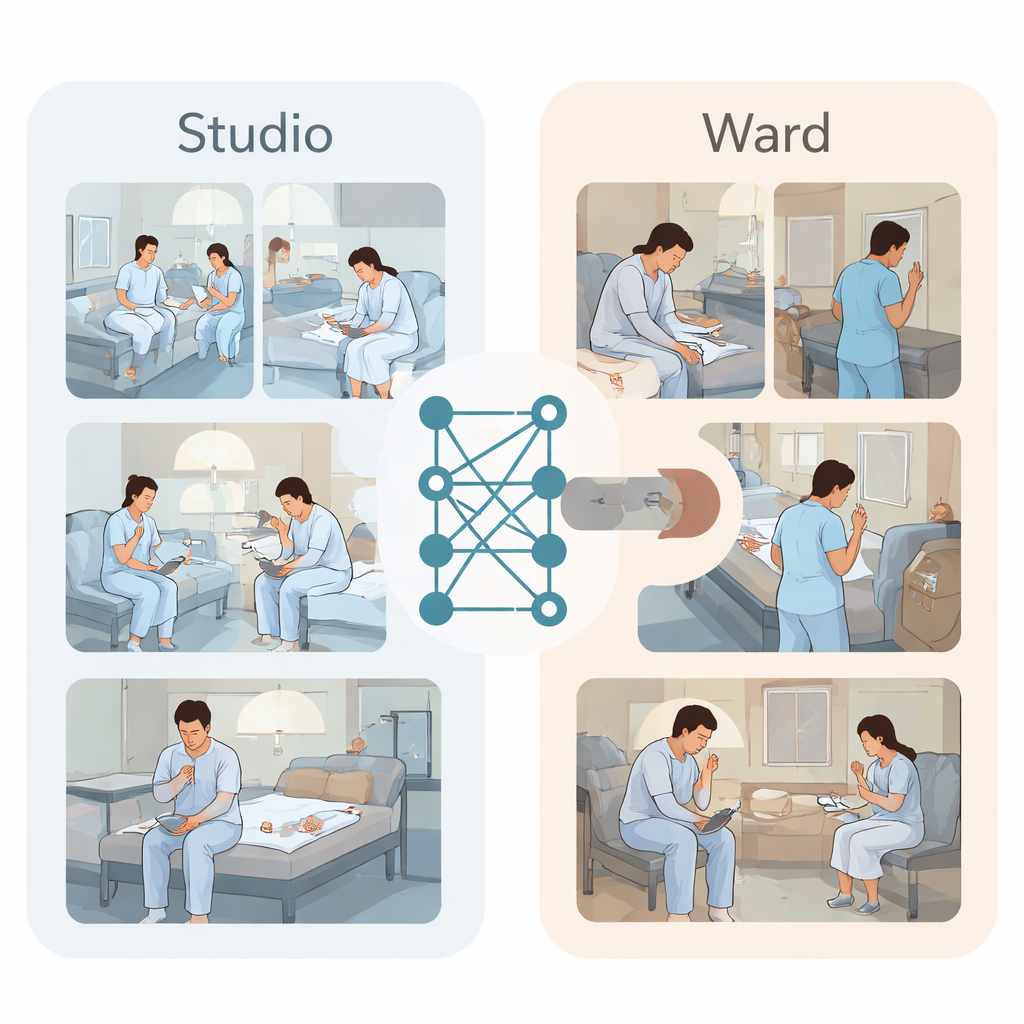
为打破这一僵局,研究团队构建了两类视频数据集。首先,在一个布置成四床精神病房的摄影棚内,七名穿着病号服的青年演员表演了精心设计的场景。他们寻找常见物品,例如塑料盖、润唇膏管或小钉子,然后在手腕、前臂或大腿上演示短暂的自伤动作,顶置摄像头从各个角落拍摄。专家将每段视频标注为正常行为或自伤行为,构建了一个干净且平衡的1120片段集合。其次,团队收集了来自封闭精神病房、时长十个月的真实监控录像。临床人员在病历中检索有关抓挠、抠挖或割伤等行为的记录,然后对应查找相应视频。对面部进行模糊处理并移除识别信息后,他们组装出59个显示真实自伤的片段和59个用于对比的正常片段。
检验当今最先进的视频AI
掌握这些数据后,团队对主流动作识别系统进行了基准测试——这些计算机程序旨在理解视频中人们的行为。一些基于较早的卷积网络,分析短序列帧;更新的基于变换器(transformer)的模型则使用注意力机制连接时空模式。所有模型仅在工作室视频上训练,以判断片段是否为自伤或正常行为。重要的是,研究者采用了严格的测试方案:每一轮都把某一演员的全部片段留作完全新的测试数据,确保算法不能简单地记住某个人。
当干净的实验室视频遇上杂乱的现实
在整洁的工作室录像上,最先进的变换器模型VideoMAEv2表现突出。它在漏判与误报之间取得了比其他模型更好的平衡,F1分数(精确率与召回率的结合度量)约为0.65,而更简单的方法表现接近随机猜测。可视化解释显示,该模型紧密关注工具接触皮肤的位置,而不会被背景运动分散注意力。但当相同训练好的系统在未经再训练的情况下应用到真实病房录像时,性能下降明显。VideoMAEv2尽管仍优于随机,F1分数约为0.61,但它在处理从未出现在模拟数据中的细微行为(如抠挖和抓挠)时遇到困难,并且对体型较小、远离摄像头或部分被遮挡的患者表现较差。
这对患者安全意味着什么
综上所述,结果揭示了明显的“从模拟到现实”差距。在精心布置的视频上看起来有前景的AI系统,面对真实医院生活中的杂乱、奇特角度和多样行为时可能会失灵。该研究的主要贡献不是一个完备的安全产品,而是一个起点:一个公开的、注释良好的工作室数据集、一组经过精心收集的真实世界测试集,以及一个透明的基准,展示当前方法的薄弱环节。对非专业读者来说,结论很直接:AI已经可以帮助突出病房视频流中的可疑时刻,但尚不足以作为独立的守护者。要弥合这一差距,需要更丰富、更具多样性的训练数据以及更聪明的模型,并在开发过程中把隐私、公平和临床判断放在首位。
引用: Lee, K., Lee, D., Ham, HS. et al. Benchmarking action recognition models for self-harm detection in studio and real-world datasets. Sci Rep 16, 6850 (2026). https://doi.org/10.1038/s41598-026-36999-w
关键词: 自伤检测, 精神病房, 视频动作识别, 医疗保健中的人工智能, 患者安全