Clear Sky Science · zh
MQADet:一种即插即用范式,通过多模态问答增强开放词汇目标检测
为什么更智能的物体识别很重要
手机、汽车、家用机器人和搜索引擎越来越依赖能够在图像中找到物体的软件:比如正在过马路的孩子、桌子上丢失的钥匙,或货架上的某个特定产品。但如今大多数系统仅能理解像“狗”或“汽车”这样简短、简单的标签。当你询问“沙发垫后面躺着、戴着红色项圈的小狗”时,它们常常会困惑。本文提出了MQADet,一种可将现有目标识别系统升级的方法,使其在不重新训练底层模型的情况下理解这种丰富、细致的描述。
从固定类别到开放式理解
传统目标检测器在固定的类别列表上训练,例如流行的COCO数据集中包含的80种日常物品。只要物体属于这些类别之一并且请求短而明确,它们就能表现良好。然而现实世界并不总是如此。人们使用冗长短语、微妙属性和关系来指代事物,例如“穿黄马甲站在卡车后面的那个人”。较新的“开放词汇”检测器试图打破固定列表,通过将图像与文本关联来实现更广泛的识别,但它们仍然难以处理复杂措辞和训练数据中稀少的“长尾”类别。要提升表现,它们也通常需要大量计算和数据。
让语言模型指导搜索
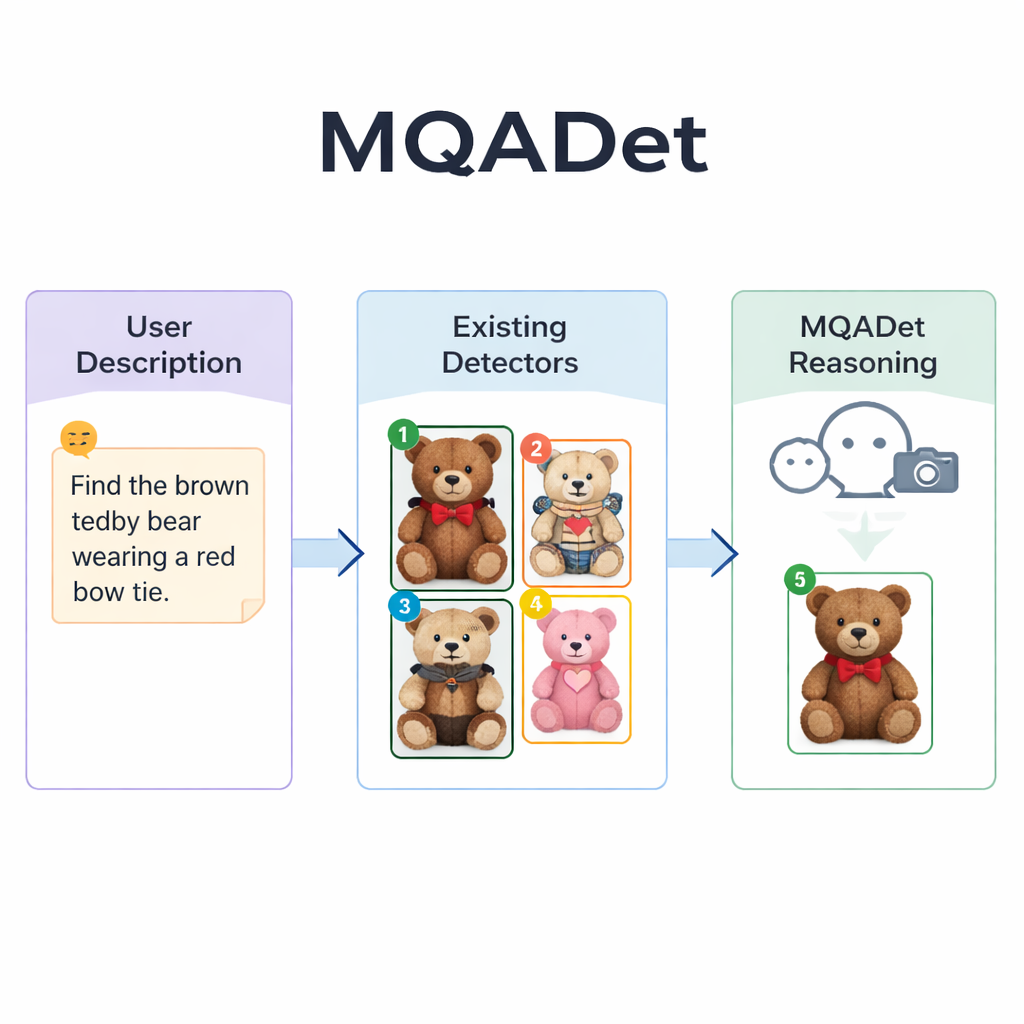
MQADet通过将一个多模态大语言模型——能够查看图像并理解文本的系统——置于现有检测器之上,采用三步问答流程来解决这些问题。首先,一个称为文本感知主体提取的阶段读取用户的整句话,提取出真实目标,例如从长描述中识别出“雨伞”和“行人”。这类似于人在扫视场景前先快速识别句子中的主要名词。关键在于,这一阶段利用了语言模型对自然语言的深刻理解,因此它能处理冗长的描述性短语,而不仅仅是单个词。
在图像中标记候选物体
第二阶段,文本引导的多模态物体定位,MQADet将这些提取出的主体与图像一并交给现有的开放词汇检测器——例如 Grounding DINO、YOLO‑World 或 OmDet‑Turbo。检测器为每个主体提出若干可能的位置,在图像中为每个候选区域画一个框并在框内放置一个简单的编号。结果就是一张显示所有可行选项的“标记图像”。重要的是,MQADet并不重新训练这些检测器;它只是按原样使用它们。这使得该方法真正具备即插即用特性:每当出现更好的检测器,都可以无需额外数据或微调即可替换进流水线中。

推理以找到最佳匹配
第三阶段称为多模态大语言模型驱动的最优对象选择,它将最终选择转化为对语言模型的多项选择问题:给定原始描述和带编号框的标记图像,哪个编号最符合文本?由于模型同时看到详细措辞和视觉布局,它能够权衡细粒度线索——图案、颜色、诸如“在左侧”之类的空间关系以及对象之间的交互。作者表明,去掉这一推理步骤会显著降低准确率,凸显了其重要性。利用这一三步设计,MQADet在四个以长自然句为主的严格基准上提升了准确率,常常在不改变检测器内部权重的情况下将现有检测器的性能提高10–40个百分点。
这对日常技术意味着什么
对非专业读者来说,关键是我们不再需要从零开始重建目标检测器就能让它们变得更聪明。MQADet像一个智能助手一样置于现有系统之上,帮助它们解释富含细节的人类描述,并在复杂场景中选出正确的物体。这可以使视觉搜索、辅助工具和自主设备在处理人们自然说话方式时更可靠——充满细节、微妙性和上下文——为更直观的基于语言的视觉交互铺平道路。
引用: Li, C., Zhao, X., Zhang, J. et al. MQADet: a plug-and-play paradigm for enhancing open-vocabulary object detection via multimodal question answering. Sci Rep 16, 6286 (2026). https://doi.org/10.1038/s41598-026-36936-x
关键词: 开放词汇目标检测, 多模态大语言模型, 视觉问答, 计算机视觉, 图像理解