Clear Sky Science · zh
在异构计算环境中用于精确任务调度的 QLSA-MOEAD 集成
为什么更智能的计算调度很重要
从地震模拟到太空望远镜,今天的科学依赖于由多种芯片混合构成的大型计算系统——传统 CPU、图形处理器和可重构硬件。决定哪个芯片运行哪一段工作,以及以何种顺序运行,出乎意料地困难,如果处理不当会浪费时间和能量。本文提出了一种新的方式来协调这些复杂工作负载,使大任务更快完成、硬件利用率更高,并且在某些情况下降低能耗。
不同芯片与交错任务
现代高性能计算机是“异构”的:它们结合了 CPU、GPU、FPGA 及其他加速器,各自具有不同的优势。科学和工业应用通常将工作划分为许多由数据依赖连接的小任务,自然形成有向无环图(DAG)。某些任务必须在其他任务开始前完成,并且任务在不同芯片上运行时快慢不一。挑战在于将数百个相互依赖的任务分配到混合处理器上,使总体完成时间短、机器被充分利用而非空闲,并且对于特定工作流使能耗保持在可控范围。从数学上讲,这属于 NP 难问题,意味着对现实系统进行穷举搜索不可行。
为何老方法不够
传统调度方法通常假定环境稳定,并集中于单一目标,例如最小化完成时间。知名启发式算法如 HEFT 按优先级对任务排序,而模拟退火或禁忌搜索等元启发式方法在可能的调度空间中漫游以寻找改进。这些方法在较小或较简单的系统上可行,但它们通常从随机初始调度开始,一旦条件变化便不够自适应,也难以同时平衡多项目标——如时间、硬件负载平衡和能耗。近来的基于机器学习的调度器提高了自适应性,但通常需要大量训练数据,且仍缺乏一种有原则的方法来生成多目标权衡的完整解集。
一种既规划又精炼的混合学习器
作者提出了 QLSA-MOEAD,一种融合了三种思想的混合框架:Q 学习、模拟退火和一种称为 MOEA/D 的多目标进化技术。首先,训练一个 Q 学习智能体通过试错来构建任务顺序。它反复构造调度,观察完成所需时间,并更新捕捉哪些选择倾向于带来更好结果的“Q 值”表。该智能体并不依赖固定规则,而是逐步学习将任务映射到处理器的良好模式,包括在执行过程中出现新任务时如何反应。利用该学习到的策略,系统生成一个强有力的初始调度,而不是随机调度,为后续优化过程提供先机。
微调与平衡相互竞争的目标
接着,模拟退火通过交换任务对微调学习到的调度,并偶尔接受更差的选项以逃离局部陷阱,类似于摇动一个拼图以落入更好的布局。最后,MOEA/D 将调度问题视为真正的多目标问题。它不将所有目标压缩为单一分数,而是将问题分解为多个子问题,每个子问题代表了尽快完成与保持处理器负载均衡之间不同的权衡——对于称为 CyberShake 的地震危险工作流,还包括降低能耗。一个进化过程并行探索这些权衡,在相邻子问题之间交换信息,以生成多样的“帕累托前沿”调度,在该前沿上改善一个目标必然会使另一个目标变差。
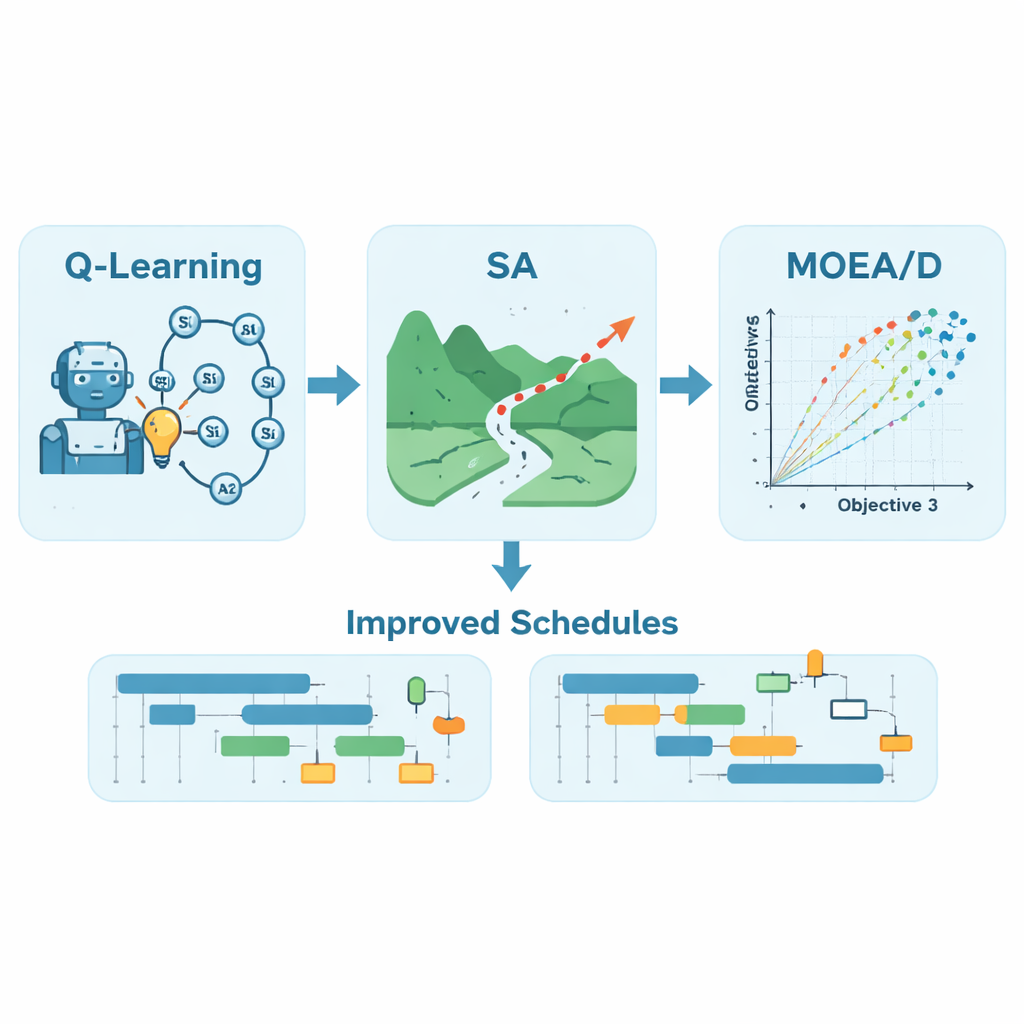
方法的测试
为评估性能,对 20 个工作流案例测试了 QLSA-MOEAD,包括合成的快速傅里叶变换和分子工作负载、大型天文图像拼接工作流(Montage),以及真实世界的 CyberShake 地震模拟。在 16 个合成案例中,该新方法在 14 个案例中提供了最佳解质量,与多个先进基线相比缩短了完成时间并提高了硬件利用率。对于同时优化能耗的 CyberShake,其在一种标准的多目标质量度量上相较于先前最先进方法取得了 2 到 4 倍的改进,同时保持了良好的权衡解分布。在新的任务动态到达的测试中,学习型调度器能在两毫秒内响应,比从头重新计算计划快得多,尽管在通信延迟极端的情况下有时会以牺牲最优性为代价。
对日常计算的意义
对于非专业读者而言,结论是更智能的基于学习的调度器可以在无需持续人工调优的情况下,使大型混合芯片计算机更快且更环保。通过结合基于经验的规划器(Q 学习)、精细的局部搜索(模拟退火)和权衡探索器(MOEA/D),所提出的框架持续找到使大任务更早完成、昂贵硬件更好被利用并且在部分应用中降低能耗的调度方案。尽管仍有局限——例如训练成本和在极端条件下性能下降——该研究展示了朝向更自主、高效地协调复杂科学与工业工作流的切实路径。
引用: Saad, A., Abd el-Raouf, O., Hadhoud, M. et al. QLSA-MOEAD integration for precision task scheduling in heterogeneous computing environments. Sci Rep 16, 7194 (2026). https://doi.org/10.1038/s41598-026-36916-1
关键词: 任务调度, 异构计算, 强化学习, 多目标优化, 节能工作流