Clear Sky Science · zh
弥合性能差距:系统化优化本地 LLM 以进行日语医疗 PHI 提取
这对患者隐私为何重要
医院掌握着大量可以改善医疗和研究的病历记录,但这些记录充满了姓名、地址和日期等敏感信息。强大的云端 AI 系统在隐藏这些信息方面表现优异,然而许多医院不被允许将未经处理的患者数据发送到外部服务器。本研究表明,通过精心调优,完全在医院内部运行的较小 AI 模型能够出人意料地接近顶级云端系统的性能——提供了一种在保持患者数据本地安全的前提下使用 AI 的可行路径。
隐私与进步的两难
现代大型语言模型通常能可靠地识别并移除医疗文本中的受保护健康信息(PHI),准确率常超过 90%。但将未经编辑的病历发送到云服务会在 HIPAA、GDPR 以及日本的个人信息保护法(APPI)等法规下引发法律和伦理问题。许多机构坚持完全的“数据主权”,要求信息不离开其内部计算机。迄今为止,能够在内部硬件上运行的本地模型通常漏检更多标识符,使医院在云端的强大分析能力与本地的更严格隐私保护但较弱工具之间不得不做出权衡。作者们着手评估是否能将这一差距缩小到适合真实临床使用的程度。
分阶段推进的本地 AI 优化方案
研究团队设计了一个五步优化框架,逐步提升本地语言模型在日语放射学报告 PHI 移除任务上的表现。他们从 14 个不同规模的模型开始,全部在一台与互联网隔离、模拟医院安全环境的计算机上运行。使用 160 篇精心构造的合成报告——真实感但完全虚构——评估每个模型识别并标注八类标识符的能力,从姓名、身份证号到日期和科室。在初始基线测试后,团队先制定更有用的通用提示(prompts),再针对每个模型的特点调整指令,加入自动化的“自检与修正”循环,最后在保留的测试报告集上评估最优候选模型。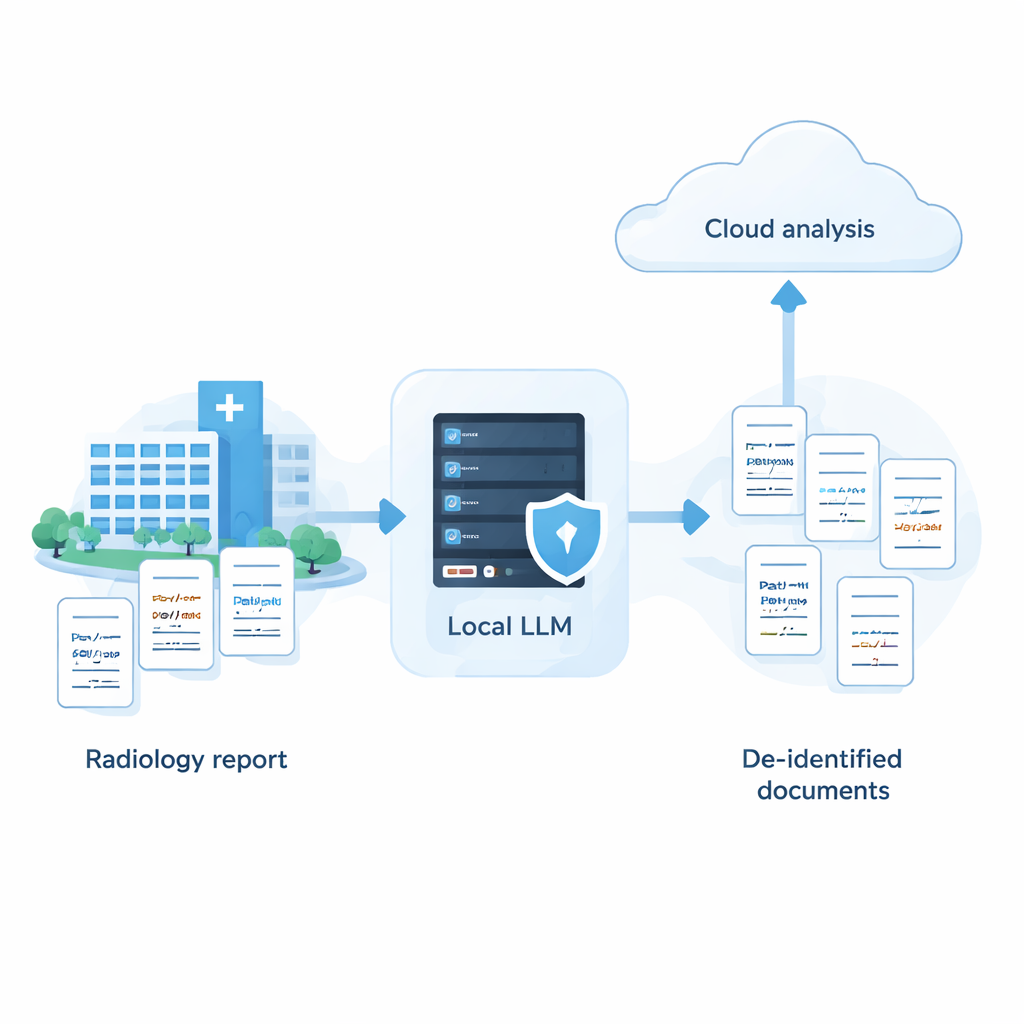
逼近云端水平的表现
通过这一分阶段流程,研究者发现模型的原始规模并非成功的关键;一些非常大的系统仍然表现不佳。相反,对指令设计和错误分析反应良好的模型更有希望。一款中等规模的系统 Mistral-Small-3.2,经由定制提示和自我精炼步骤(模型复查并有选择地修正自身输出)后成为明显的优胜者。在最终 60 个测试案例上,这一优化的本地配置得分为 91.54(满分 100),约为领先云端模型 93.56 分的 97.8%,且在格式规则上完美遵循。从实际意义上看,其剩余差距被评为临床上可忽略。主要代价是速度:本地处理平均每份报告约需 25 秒,而云端不到 2 秒,但对于常规的非紧急批量工作而言,这是可接受的。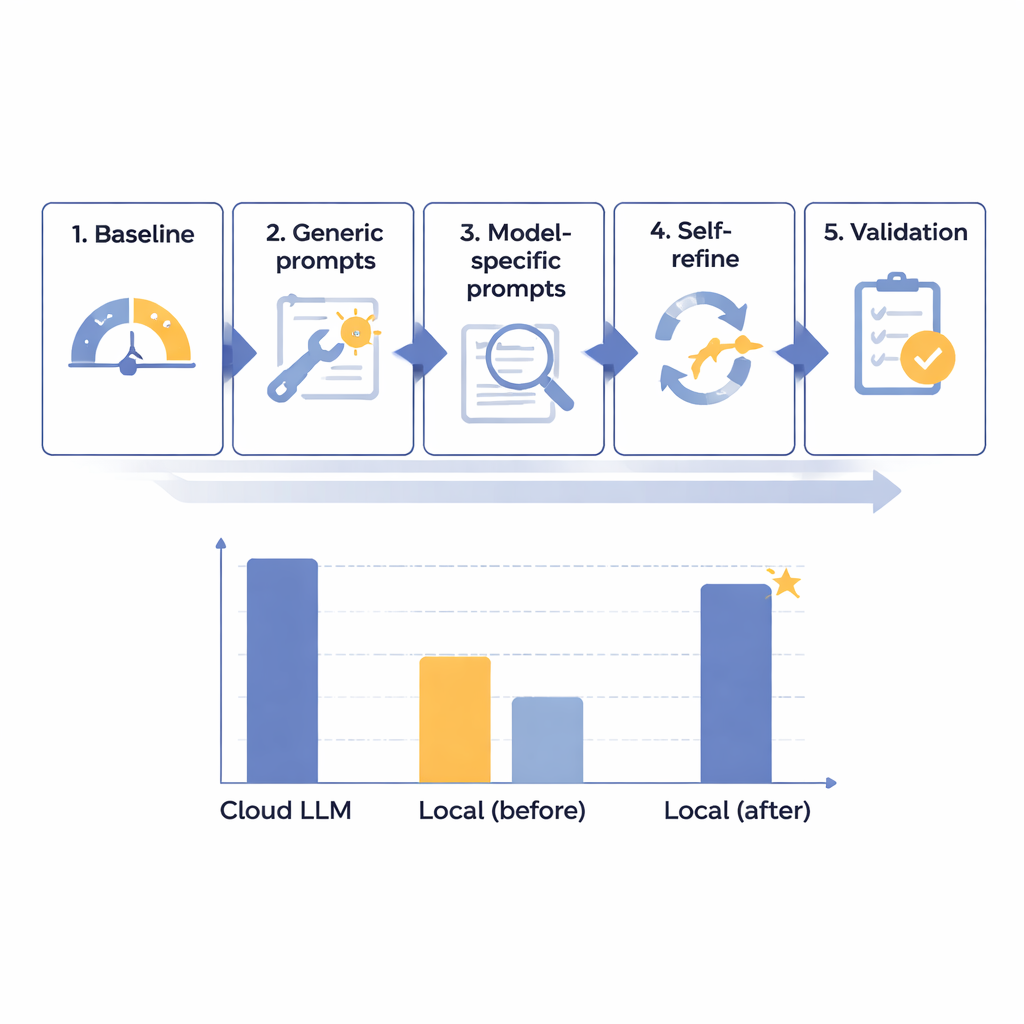
自我修正的一个意外阈值
一项最有趣的发现是在作者所用的 100 分量表上出现了约 87–88 分的分水岭。基线得分低于该水平的模型——例如 Mistral-Small-3.2——通过自我精炼循环获益良多,通过修正自身少量错误几乎提升了七分。那些基线就高于该阈值的模型几乎没有改进,有时还会徒劳地尝试“修正”原本正确的答案。这表明高级优化工具应优先用于表现良好但尚未卓越的模型,从而让医院将计算资源和人员时间集中在收益最大的地方。作者提醒这一定律仅基于两款模型的观察,需要进一步验证,但它为部署规划提供了早期的经验法则。
对医院和患者的意义
研究认为医院不必在强隐私与强 AI 之间二选一。通过系统化的方法——筛选多个模型、根据其长短制定提示并加入智能自我复核步骤——完全本地化的系统有可能接近顶级云服务在移除医疗文本敏感信息方面的准确率。实际操作上,这为混合策略打开了大门:在医院自有机器上安全去除 PHI,仅将已匿名化、去除姓名和其他标识符的报告发送到云端以进行更高级的分析。虽然目前的工作基于合成的日语放射学报告,仍需在真实世界数据和其他语言上验证,但它为希望在以患者信任和隐私为核心的前提下利用 AI 的机构提供了可操作的路线图。
引用: Wada, A., Nishizawa, M., Yamamoto, A. et al. Bridging the performance gap: systematic optimization of local LLMs for Japanese medical PHI extraction. Sci Rep 16, 5910 (2026). https://doi.org/10.1038/s41598-026-36904-5
关键词: 医疗去标识化, 患者隐私, 本地语言模型, 医疗保健人工智能, 放射学报告