Clear Sky Science · zh
低算力边缘 SoC 上的目标检测:可复现的基准与部署指南
为何用于智能摄像头的微型芯片重要
我们周围的许多“智能”设备——安防摄像头、无人机、工厂传感器和门铃——需要实时识别人和物体,但它们依赖的是非常小、低功耗的芯片,而不是耗电的数据中心硬件。公司常常选择流行的 YOLO 目标检测模型,但芯片的标称速度对实际场景中的表现说明甚少。本文通过实验性分析,考察了九种现代 YOLO 变体在三款广泛使用的低成本 Rockchip 处理器上的表现,揭示了当智能下沉到边缘时,哪些因素真正影响速度、能耗和可靠性。
显微镜下的三款常见芯片
作者聚焦于三款在许多嵌入式视觉系统中默默工作的商用系统级芯片(SoC):小型的 RV1106、中端的 RK3568 和更强大的 RK3588。每款芯片都将通用处理器核与专用神经处理单元(NPU)和外部内存结合在一起。在这些平台上,团队部署了九个 YOLO 模型——三代(YOLOv5、YOLOv8、YOLO11)各三种尺寸(Nano、Small、Medium)——全部在相同的基准数据集上训练。他们谨慎地将模型转换为统一格式,量化为 8 位算术,使用 Rockchip 的工具编译,然后运行数百次计时测试以获得延迟、功耗和每帧能量的稳定测量。
速度并非规格表所示
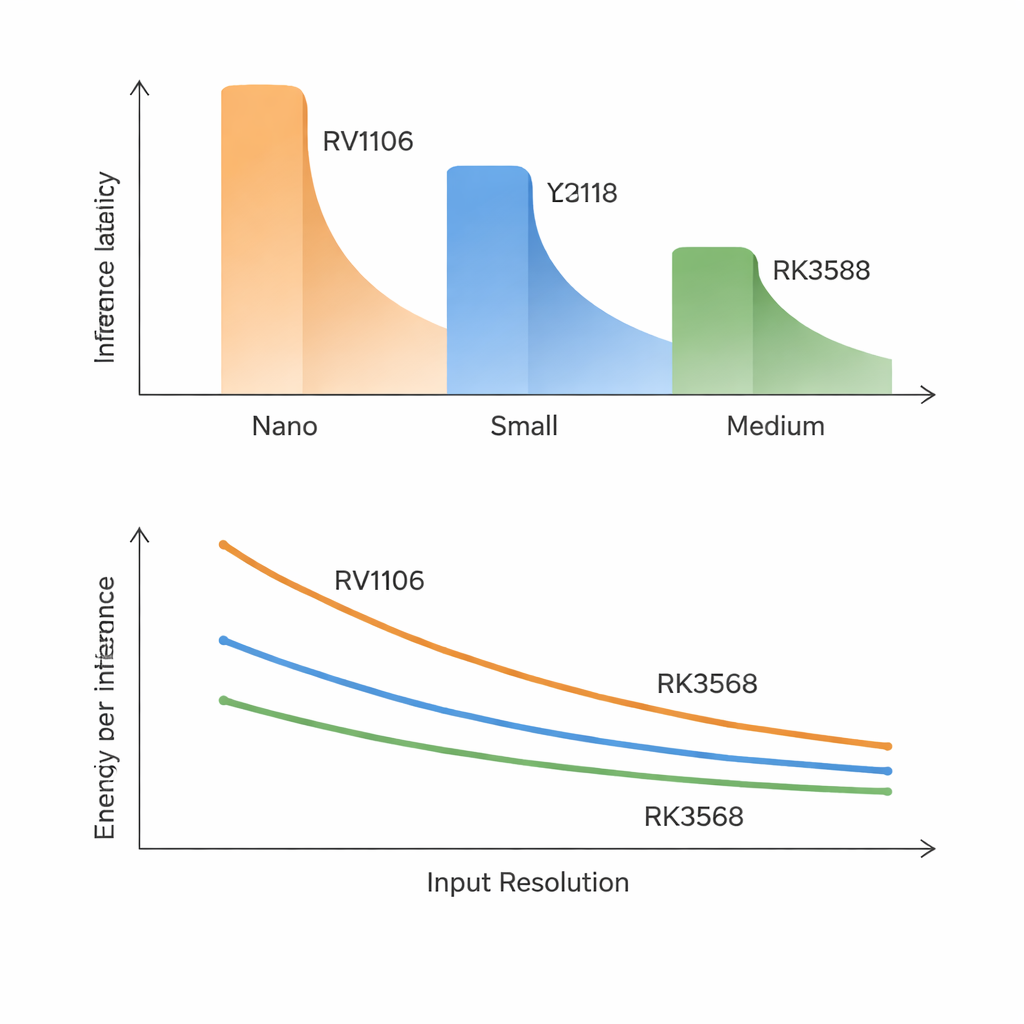
最清晰的结论之一是,传统的模型和芯片参数并不能很好地预测实际速度。在最慢的芯片上,即使是最小的模型每帧也需要大约 70–100 毫秒,中等大小的模型远不能满足实时要求。最快的芯片可以让 Nano 和许多 Small 模型接近 30 帧/秒,但较大的模型仍达不到很高的帧率目标。令人惊讶的是,延迟与模型的准确度比与其计算量或参数数量更相关。更新、更准确的 YOLO 设计增加了有利于精度但对这些 NPU 执行不友好的内部模块,因此在此类硬件上“更聪明”往往意味着“明显更慢”。
更大图像和共享内存的反噬
研究表明,增大输入图像不仅仅是平滑地增加计算量。理论上,宽度和高度各翻倍会使成本增长四倍,但在低带宽芯片上增长可能更快。随着图像变大,中间数据不再能轻松放入本地缓存,必须反复搬运到片外内存。在最小和中端 SoC 上,这会变成交通堵塞:中等大小的模型比预期慢得多,其他任务带来的背景内存占用会将延迟抬高 50–270%。相比之下,RK3588 拥有远更高的内存带宽,能优雅地处理分辨率提升,在额外的 CPU 或内存负载下几乎不受影响,这突显了内存速度——而非原始计算能力——往往才是真正的瓶颈。
更多核心与更高功率并不保证效率
Rockchip 最快的芯片包含一个三核 NPU,但在多个核心上运行 YOLO 的收益有限。对于大多数模型,将工作拆分到两核或三核通常把延迟降低不足 10%,有时性能甚至下降。协调多核和共享同一内存池的开销抵消了理论上的大部分收益。功耗测量带来了另一层转折:三款 SoC 在运行时的瞬时功耗都只有几瓦,但每帧能量消耗可能相差三倍。高端的 RK3588 在任一时刻使用更多功率,但完成工作所需时间更短,因此通常在能效上最有优势,尤其是对于中等大小模型和更高分辨率的情形。
面向真实设备的实用要点
对于考虑智能摄像头、机器人或物联网设备的读者来说,结论很直接。在最小的芯片上,只有在中等图像尺寸下极小的 YOLO 模型才实际可行,即便如此实时视频也很吃力。中端芯片可以比较轻松地支持小型模型,若能放宽帧率或电池寿命要求,有时也能运行中等模型。高端的 RK3588 则真正使运行更准确的中等大小 YOLO 变体变得现实,同时还能将每帧能耗控制在合理范围。总体而言,论文主张设计者应在选模型时紧贴具体硬件,密切关注内存带宽,并偏好节省内存的技巧,而不是追求愈来愈大的网络。最终重要的不是宣传的每秒万亿次运算,而是整套系统能否在现实世界的复杂条件下提供快速、稳定且节能的目标检测。
引用: Kong, C., Li, F., Yan, X. et al. Object detection on low-compute edge SoCs: a reproducible benchmark and deployment guidelines. Sci Rep 16, 5875 (2026). https://doi.org/10.1038/s41598-026-36862-y
关键词: 边缘 AI, 目标检测, 嵌入式视觉, YOLO 模型, 低功耗 SoC