Clear Sky Science · zh
基于机器学习的方差估计在两阶段抽样下的应用:以卫生与教育部门数据为例
为什么更聪明的平均值对实际决策很重要
无论是医生研究血压,还是教育者跟踪学生成绩,他们关心的不仅是平均水平,更需要了解个体在该平均值周围的差异有多大。这个差异,称为变异性,决定了试验需要招募多少患者、辅导项目应有多大规模,以及我们对政策决策可以有多大信心。本文总结所基于的论文提出了一种新的、统计学上有理论支撑的方法,通过把经典抽样思想与现代机器学习结合,在卫生和教育数据上进行检验,从而更精确地测量这种变异性。
在信息不完整时测量差异
在理想情况下,研究者在开展调查前会知道总体中每个人的更多细节:年龄、学习习惯、病史等。但现实中这些信息往往缺失或采集成本高。作者在一种称为两阶段抽样的设计框架下处理这个问题。第一阶段,他们抽取较大且相对便宜的样本,记录简单的背景信息,如年龄或是否有互联网接入;第二阶段,从中抽取较小的子样本,测量更昂贵或耗时的结果变量,例如收缩压或期末成绩。关键挑战是利用这两层信息来估计整个总体中结果变量的真实变异程度。
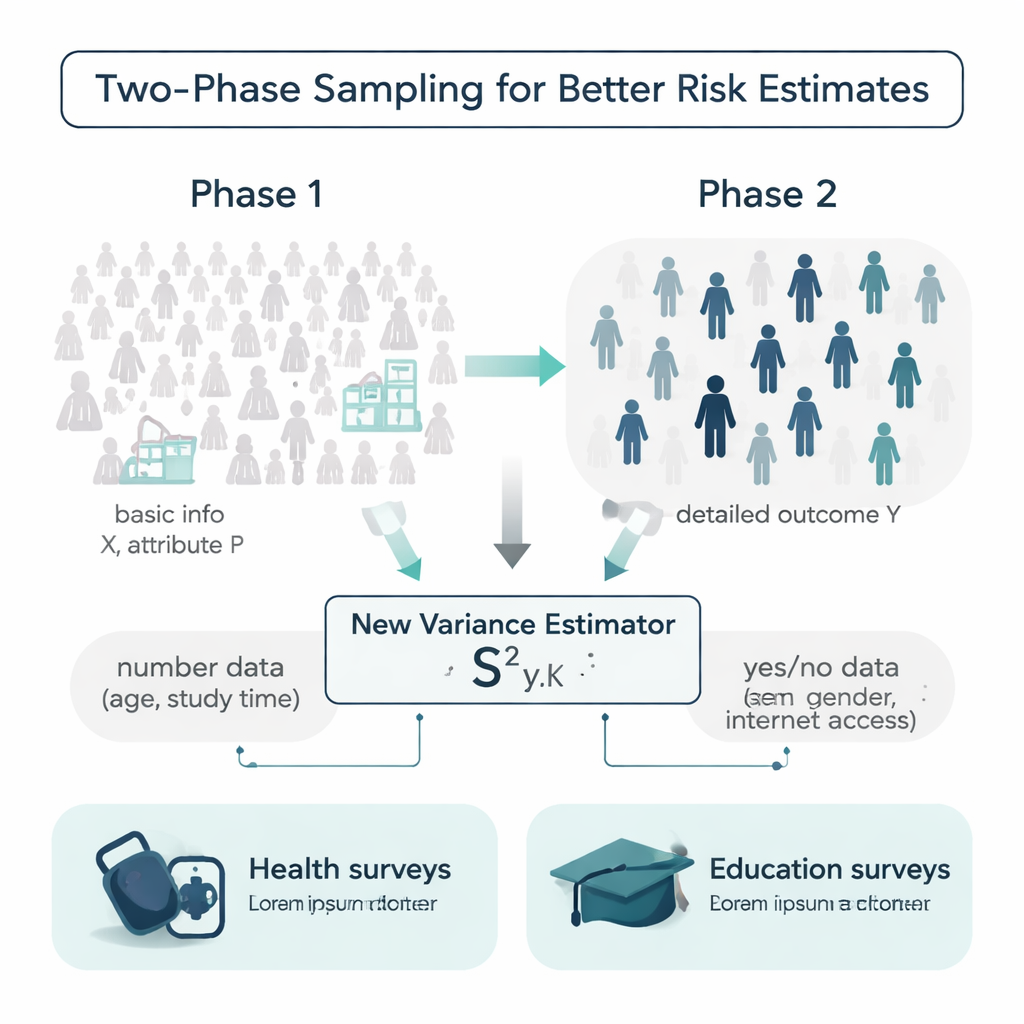
一种同时利用数值与二元特征的新估计量
大多数传统的方差测量工具仅依赖结果本身或单个辅助变量,并且常假设数据服从方便的钟形分布。作者提出了一种新的方差估计量,同时使用两类辅助信息:数值型辅助(例如年龄或每周学习时长)和二元属性(如性别或是否有互联网接入)。他们在数学上推导了这种混合估计量的性质,给出了其偏差和均方误差的公式——这是衡量准确性的两个关键指标。在合理条件下,该估计量近似无偏,其期望误差比广泛使用的竞争方法更小,这意味着在相同数据量下能提供更为精确的不确定性评估。
在多种数据情形下检验性能
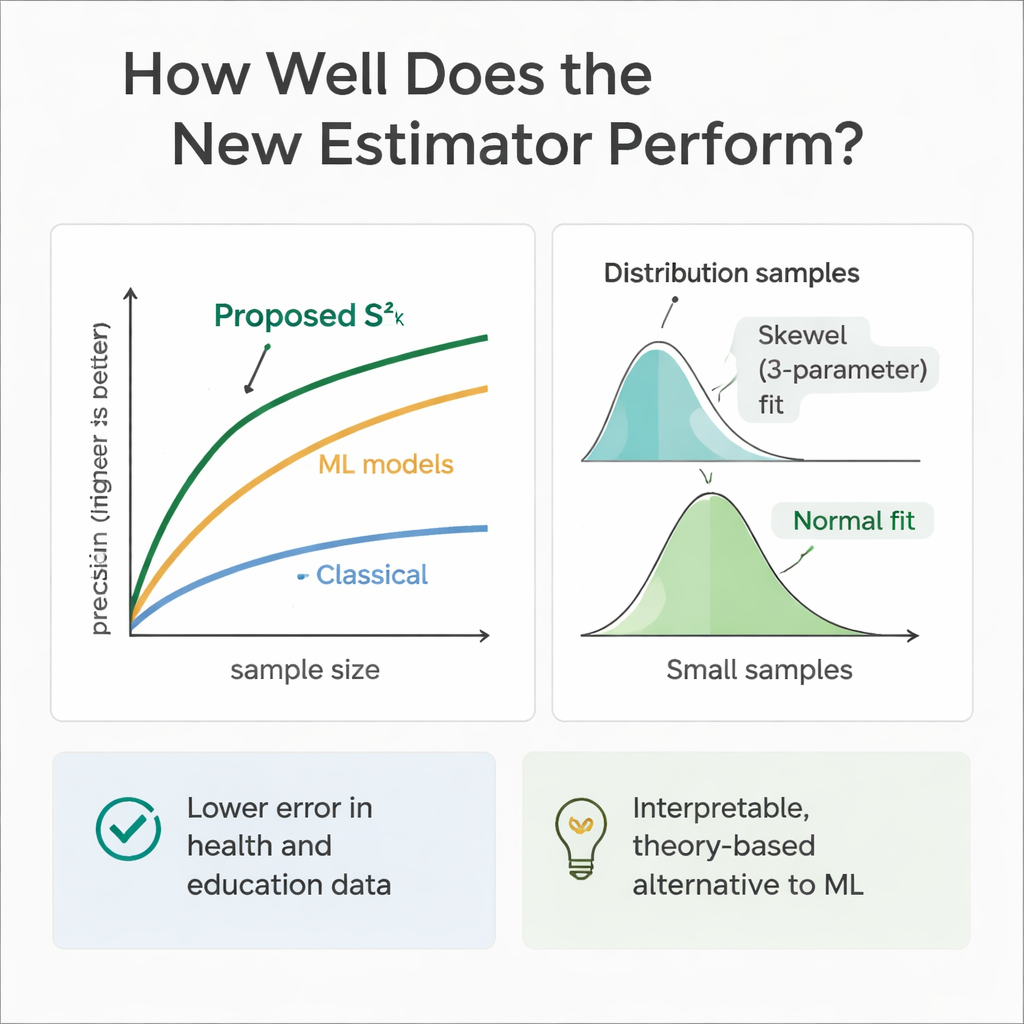
为验证理论在实践中的表现,研究团队进行了大量计算实验。他们模拟了多种总体结构,其中辅助变量和结果变量服从从对称(正态和均匀分布)到偏态(伽马和韦伯分布)的不同分布。通过重复抽样,将新估计量的误差与若干已知方法在不同样本量下进行比较。在几乎所有情形中,尤其是样本量增大时,新方法展现出更高的相对效率——通常相比经典方差估计器能将误差降低30%到70%。作者还检查了估计量自身的抽样分布,发现对于中等样本量,三参数韦伯分布能较好地拟合其分布,而随着样本量增大,分布则趋向正态。
来自诊所与课堂的真实数据
该方法随后应用于两项真实案例。卫生数据集中,结果变量为收缩压,数值型辅助为年龄,二元属性为性别;教育数据集中,结果为期末成绩,辅助为每周学习时长,属性为学生是否有互联网接入。在这两类数据中,所提估计量在所有被测试的统计方法中均获得最小的均方误差,显著收窄了围绕平均收缩压和平均学生表现的变异估计。此种改进转化为更精确的置信区间以及在组间或干预效果比较时更可靠的结论。
与机器学习的比较
鉴于机器学习模型在预测方面表现出色,作者还在相同的模拟卫生与教育情境中训练了回归树、随机森林和支持向量回归。这些模型在使用相同的辅助变量时,常常在纯预测精度上能与新估计量相匹配或略有超越。然而,它们更像黑箱:难以追溯其信息的组合方式,且缺乏用于传统抽样推断的解析公式。相比之下,所提出的估计量透明且根植于抽样理论,在需要可解释性与可证明性的监管、临床或政策场景中更容易被采纳。
对实际调查的意义
简而言之,这项工作表明,研究者无需大幅增加样本量,就能通过有纪律地利用已有的简单额外信息获得更可靠的变异测量。将一个数值因子(如年龄或学习时长)与一个简单的二元特征(如性别或互联网接入)在两阶段抽样方案中结合使用,新估计量比长期使用的方法能给出更尖锐、更稳定的方差估计。尽管先进的机器学习工具仍然是有益的基准,这一方法提供了一个实用且可解释的中间方案,帮助卫生与教育领域的分析者在数据有限的情况下得出更有力的结论。
引用: Al-Marzouki, S., Nafisah, I.A., Dalam, M.E.E. et al. Machine learning based variance estimation under two phase sampling using health and education sector data. Sci Rep 16, 7760 (2026). https://doi.org/10.1038/s41598-026-36844-0
关键词: 抽样调查, 方差估计, 机器学习, 健康数据, 教育研究