Clear Sky Science · zh
使用机器学习通过临床和实验室数据对脂肪性肝病进行诊断与分级
为什么脂肪肝对普通人重要
脂肪肝已经悄然成为全球最常见的慢性肝病之一,约影响三分之一的成年人,甚至许多看起来完全健康的人也可能患病。如果肝脏中脂肪堆积过多且未能及早发现,可能会缓慢进展为肝纤维化、肝功能衰竭,甚至肝癌。然而,目前最可靠的检测要么是侵入性的,例如穿刺活检,要么依赖昂贵的影像设备,许多门诊无法配备。本研究探讨了是否可以用常规的血液检查和身体测量数据,结合现代计算技术,提供一种更简便的方法来识别谁患有脂肪肝以及病情的严重程度。
一种可能变严重的隐形疾病
脂肪变性性肝病(常称脂肪肝)始于脂肪在肝细胞内的积累。起初,这种脂肪堆积(简单性脂肪变性)可能没有任何症状,常被意外发现。但随着时间推移,脂肪可引发肝脏炎症和损伤,导致疤痕形成(纤维化)、组织硬化,最严重时可发展为肝硬化和肝衰竭。因为早期通常无症状且具有可逆性,在出现明显纤维化之前就发现疾病至关重要。问题在于,目前许多用于评估肝损伤的常用工具——如专用超声设备和基于血液的评分系统——要么太昂贵、覆盖不足,要么在肥胖人群中准确性较差,而这些人群恰恰处于高风险之列。
将常规体检转为肝脏健康筛查
研究人员探寻是否能将日常临床信息转化为有力的筛查工具。他们利用了来自伊朗德黑兰一家消化疾病门诊的210名成年患者的病历。对每位患者收集了身高体重等基本测量值,以及胆固醇、甘油三酯、空腹血糖、肝酶和铁代谢相关标志物等常规血检。肝脏脂肪堆积和纤维化的严重程度已通过一种称为FibroScan的专用设备测量,研究团队据此将参与者分为五组:从健康肝脏到轻度、中度、重度脂肪堆积,再到有进展性纤维化的患者。这些分组作为计算模型训练和测试的“实际真值”。
扩充数据并训练模型
由于210例患者对于机器学习来说样本量偏小,研究团队通过在真实数据上加入受控的随机变异,创建了额外的“合成”患者记录。他们验证了这些模拟记录仍保持与原始数据相似的总体模式,并将数据集扩展到1500个样本。接着,他们测试了八种不同的机器学习方法,包括决策树、随机森林、支持向量机和神经网络,以及这些方法的组合。每个模型被要求仅基于临床和实验室数据预测某人属于五个肝脏健康分组中的哪一类。评估不仅依据总体准确率,还关注模型将病人错误判为健康的情况——这是任何筛查工具极为重要的考虑点。
找出最有价值的少数指标
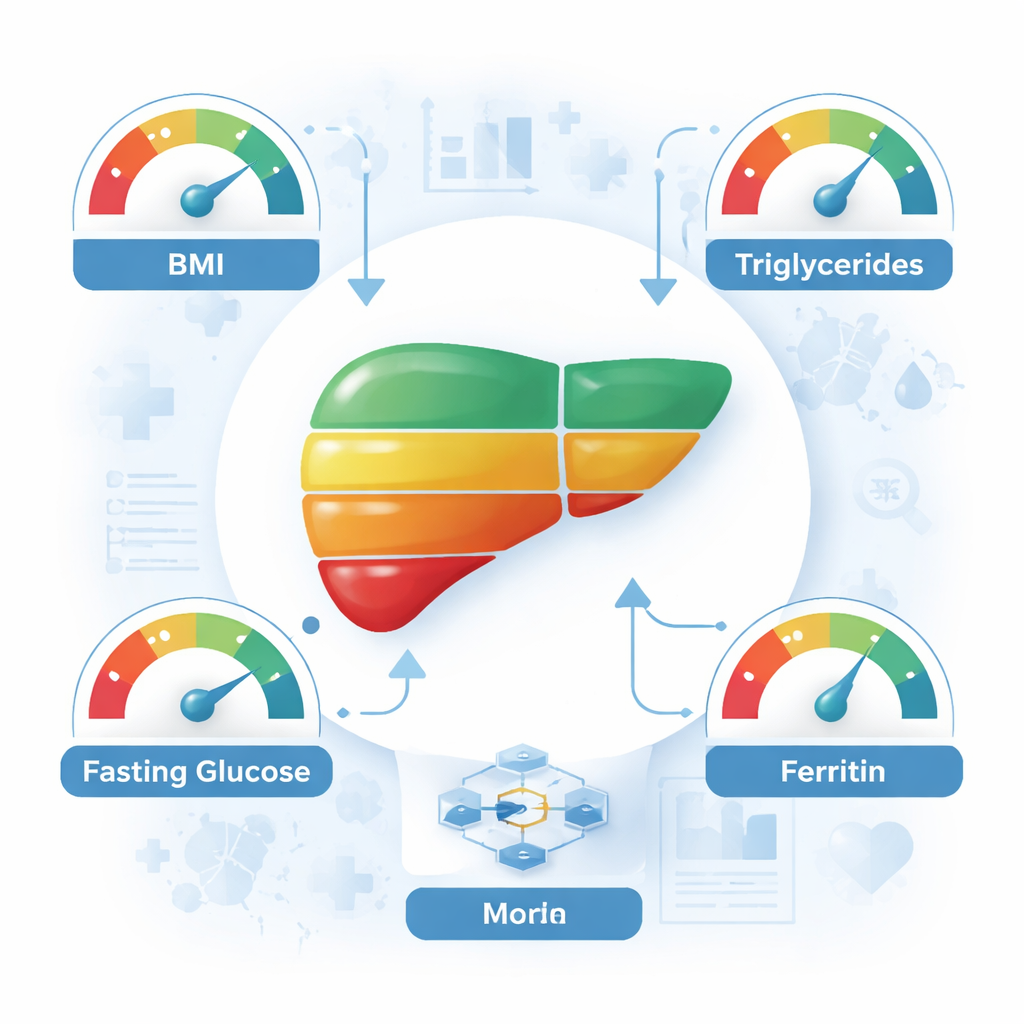
一些模型表现优异,尤其是一种将支持向量机与提升方法结合的混合模型(SVM–XGBoost),在使用全部26项特征时达到了约93%的准确率。为了让工具更简洁易用,研究者接着分析了哪些测量对预测贡献最大。统计技术首先筛选出八个特别重要的特征,包括体重指数(BMI)、甘油三酯、空腹血糖、铁蛋白(储铁蛋白)、血小板、碱性磷酸酶、肌酐和一个凝血指标。肝病专家随后审核这些结果,并挑选出四项既与疾病生物学强相关又在日常诊疗中易于获得的指标:BMI、甘油三酯、空腹血糖和铁蛋白。令人惊讶的是,当仅用这四项输入重新训练模型时,模型仍能在约70%的情况下正确分类患者,表现最佳的方法准确率可达76%。
这对患者与门诊意味着什么
对普通读者来说,主要信息是:常规体检中的少数几项指标——用于计算BMI的体重与身高,以及反映脂质、血糖和储铁情况的简单血液检测——在经过设计良好的计算模型解读后,能提供对肝脏健康出人意料的细致洞见。尽管这些工具不能替代专家的医学判断或在有条件时的专用影像检查,但它们为识别高风险人群提供了有前途的途径,特别适合资源有限的门诊和脂肪肝高发的地区。更早的发现可以促使采取生活方式干预,如减重、更健康的饮食和增加体力活动,这些措施已被证明能改善肝脏健康。本研究表明,在不久的将来,你的常规化验结果可能会成为这类隐匿但严重疾病的早期预警系统的一部分。
引用: Sadeghi, B., Zarrinbal, M., Poustchi, H. et al. Diagnosis and grading of steatotic liver disease via clinical and laboratory data using machine learning. Sci Rep 16, 6866 (2026). https://doi.org/10.1038/s41598-026-36834-2
关键词: 脂肪肝疾病, 机器学习, 血液检测, 体重指数和甘油三酯, 无创诊断