Clear Sky Science · zh
空间硬件故障报告中的分类建模与分类
在航天故障中寻找模式
每一次太空任务都依赖于无数硬件部件的可靠运行,从螺栓和电缆到生命维持系统。当出现问题时,工程师会提交详细的差异报告,但 NASA 现在已有超过 54,000 条此类记录——人力逐条阅读已不现实。本研究展示了如何用现代语言处理与机器学习工具,将这座文字“山”转化为有序的知识,帮助工程师发现故障模式、改进设计并提高航天员的安全性。
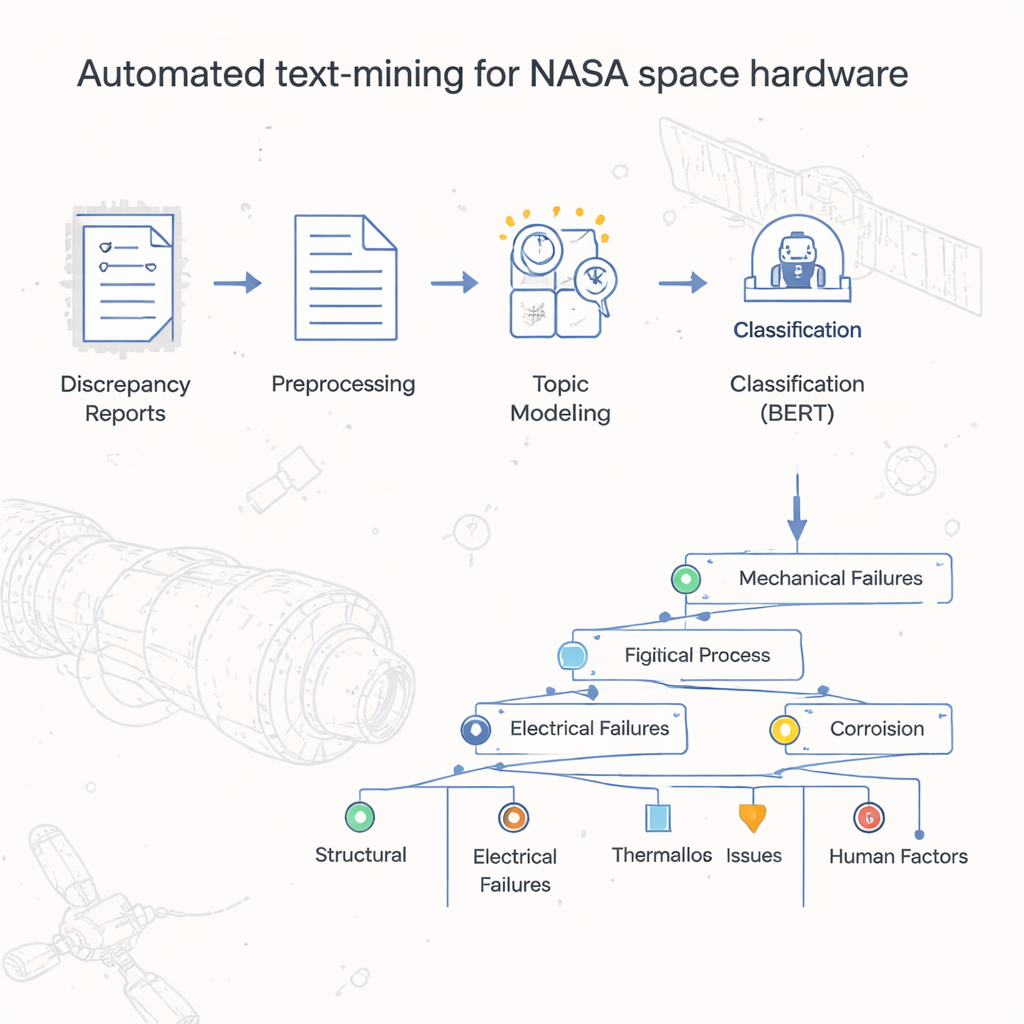
从一堆报告到有组织的洞见
几十年来,NASA 约翰逊航天中心把硬件故障与差异报告以数字文档形式保存,类似于旧纸质表单的扫描件。简单的电子表格统计能显示哪些官方缺陷代码出现得最频繁,但真正的情况——导致问题的具体原因、步骤与条件——埋在自由文本字段中。人工阅读并分类 54,000 多条记录的工作量极其庞大。作者们着手构建一种自动化方法,对这些报告进行分类与分组,创建一种“地图”或分类法,以呈现日常实践中航天硬件的实际失效方式。
教电脑“读”工程语言
团队首先清理每条报告的文本,使计算机能够有效处理。他们删除了增加噪音的杂散符号与数字,将句子拆分为单个词,并将词转换为更简单的基础形式(例如把“leaked”和“leaking”统一为“leak”)。像“the”或“and”这样的常见低信息词被过滤掉。文本标准化后,研究者将其转换为机器学习算法可处理的数值表示,采用了能反映词频及其在文档中表征度的成熟技术。这些基础工作使他们能够把原本为通用语言任务开发的强大工具,应用到高度专业化的航天硬件报告领域。
构建故障类型树
该项目的核心是作者称为 LDA-BERT 的两步模型。第一步,潜在狄利克雷分配(LDA),通过在数千份报告中寻找常同时出现的词模式,自动发现主题(即 topics)。一份报告可以同时包含多个主题,反映出一个硬件问题常常有多个促成因素。第二步使用 BERT 这一现代语言模型来检验并精炼这些主题的区分度。研究者把 LDA 主题视为临时标签并训练 BERT 去预测它们,从而确定出能提供稳定、准确分类的主题数量与组合。随后,他们又用聚类和统计检验将每个主题进一步细分为子主题,构建出一棵从宽泛缺陷代码到详细流程层面标签的分支式分类树。
把分类法变成可操作的趋势信息
分类法建立后,团队通过仪表盘和交互工具将其可视化。树的每个分支与子分支都可以链接到报告中的其他信息:问题首次记录的时间、解决所需的时长、负责的组织以及最终决定。时间序列图显示某些问题类型(例如检查疏漏或公差数据问题)多年来是趋多还是趋少。词汇图则在无需逐条阅读报告的情况下,快速传达每个聚类中常用的语言。这些视图帮助管理者聚焦于高增长率和高影响力的流程性失效,从而在培训、流程修改或设计更新方面采取重点行动。
自动化根因追溯的局限
研究者还探索了试图超越标注与趋势发现、从文本中推断直接因果关系的工具。他们测试了像 INDRA-Eidos 的系统以及基于 spaCy 语言库定制的规则集。尽管这些工具能提取一些因果对并将其可视化为互动网络,但许多建议的关联过于模糊或令人困惑,难以直接应用。实际上,模型面临的困难在于原始报告常常并未明确写出根本原因;工程师很多时候是暗示原因或将其留待后续调查。本研究得出结论:要可靠地自动发现根因,既需要更丰富的数据输入——例如为可能原因设置明确字段——也需要更昂贵且高度定制的模型训练,这对于一次性分析并不划算。
这对未来任务的重要性
通过将大量无结构的故障报告档案转化为清晰、分层的分类法,这项工作为 NASA 提供了一种实用的手段,用以持续监测硬件问题随时间出现的方式与原因。尽管这些方法尚不能取代人类在深度根因分析中的判断力,但它们擅长扫描海量文本以突显问题聚集的领域以及通常涉及的流程类型。这类早期预警与结构化洞见可以帮助工程团队更有针对性地分配注意力、优化流程并设计更鲁棒的系统——这是向更安全、更可靠的登月、火星及更远目标迈进的实际步骤。
引用: Palacios, D., Hill, T.R. Taxonomical modeling and classification in space hardware failure reporting. Sci Rep 16, 5868 (2026). https://doi.org/10.1038/s41598-026-36813-7
关键词: 空间硬件故障, 自然语言处理, 主题建模, 工程风险分析, NASA 差异报告