Clear Sky Science · zh
使用连接的BERT与GloVe嵌入,通过深度学习验证乌尔都语新闻真实性
为什么识别乌尔都语假新闻很重要
在巴基斯坦和世界各地,越来越多的人从网站和社交媒体获取新闻,而不是从报纸或电视。这一转变使得虚假报道比以往任何时候都更容易快速传播,尤其是在像乌尔都语这样的国家语言中,数字工具较为有限。本研究处理一个简单但紧迫的问题:现代人工智能能否自动区分真实的乌尔都语新闻与假新闻,从而帮助普通读者、记者和平台抵御误导性信息?
不断加剧的在线虚假信息挑战
作者首先概述了捏造的标题和扭曲的报道如何塑造公众舆论、激化政治紧张局势,甚至损害人们的健康和财务。虽然许多事实核查网站和研究项目集中在英语上,但乌尔都语等地区语言常被忽视。现有的乌尔都语资源仅包含几千条新闻,许多是从英语翻译而来,并集中在诸如政治等狭窄主题上。这使得很难训练出在大多数巴基斯坦人实际阅读的语言中可靠识别可疑内容的计算机系统。
构建大规模乌尔都语新闻语料库
为弥补这一差距,研究人员组建了他们所称的迄今最广泛的乌尔都语假新闻数据集,包含2017年至2023年间从受尊重的巴基斯坦新闻网站和在线平台收集的14,178篇新闻文章。报道涵盖日常生活的十五个领域,包括政治、健康、教育、商业、犯罪、体育和环境。研究人员使用诸如PolitiFact、FactCheck以及专门的新闻API等事实核查来源,对每条条目标注为真实或虚假;部分真实的条目被归为真实新闻,以反映更为细微的报道差异。随后,团队通过去重、移除网页地址与多余标点、将句子切分为单词并剔除非常常见的填充词来清理文本。
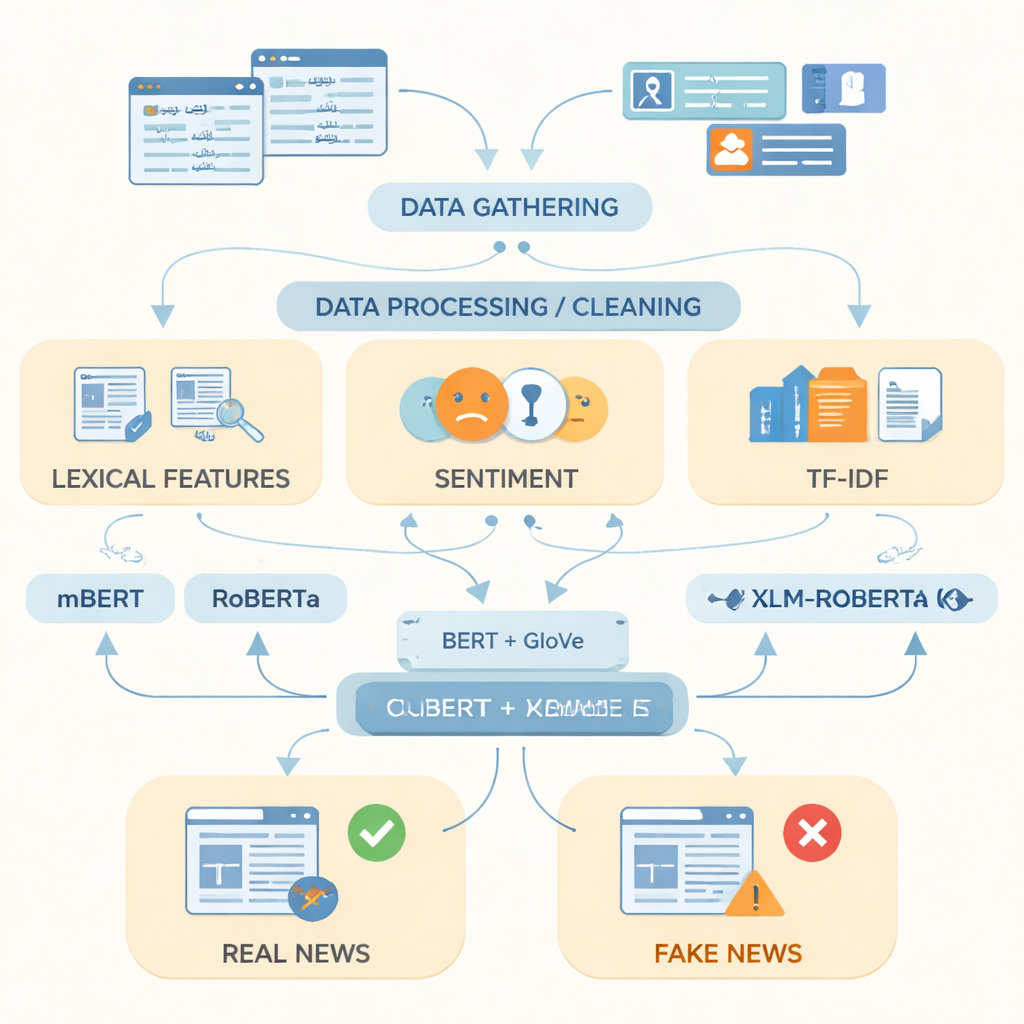
教计算机识别假新闻的样子
在准备好数据后,作者着重研究如何以计算机可用的方式表示乌尔都语文本。他们将简单的指标(如常用词、语言的情绪倾向和词频得分)与两种强大的词表示技术结合起来。一种称为GloVe,将每个词视为基于其与其他词在整个语料中共现频率的固定数值向量;另一种基于BERT风格的模型,根据单词在句子中的上下文为其赋予语境感知的含义。通过将这两种语言视角结合成单一、更丰富的表示,系统既能捕捉整体模式,也能识别常常区分真假报道的措辞细微变化。
检验先进的语言模型
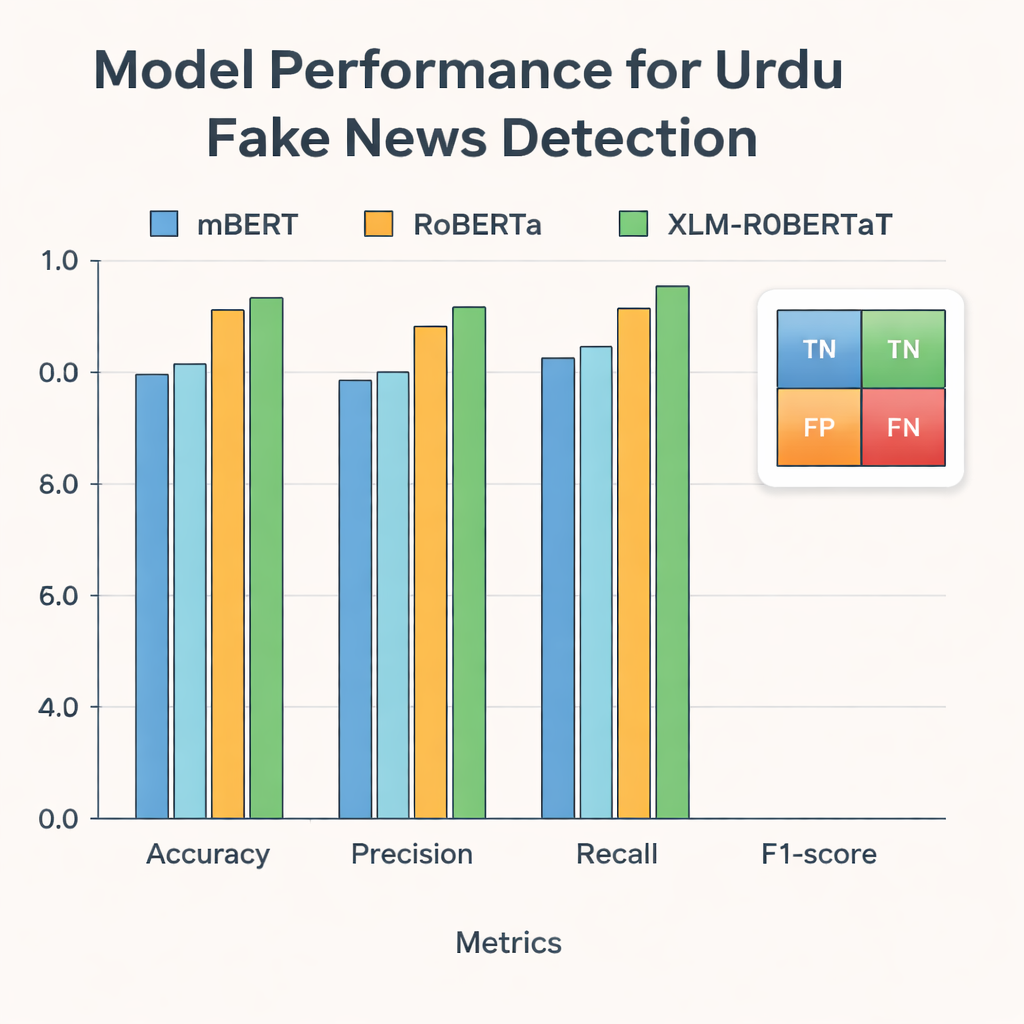
研究人员随后将这些表示输入到三种以多语言文本训练的现代深度学习模型:mBERT、RoBERTa 和 XLM-RoBERTa。这三者都在乌尔都语数据集上进行了微调,以预测每篇文章是真实还是虚假。其表现通过标准指标评估:准确率(预测正确的频率)、精确率(被标记为假的中有多少确实为假)、召回率(他们捕捉到的所有假新闻的比例)以及平衡精确率和召回率的F1分数。尽管每个模型都表现强劲,但将融合的BERT与GloVe表示与XLM-RoBERTa结合使用的效果最好,在测试文章中约有96%被正确分类,F1分数达到0.956——优于那些使用更小数据集或更简单方法的先前乌尔都语假新闻系统。
这对普通读者意味着什么
对于非专业读者,结论很明确:只要有足够高质量的乌尔都语新闻数据和合适的人工智能,就可以构建出能够高可靠性自动标记可能为假的报道的工具。研究表明,更丰富的语言表示和多语种模型能让计算机更好地把握乌尔都语在不同地区和主题中的实际书写方式。尽管当前工作仅聚焦文本,尚未分析图像或社交媒体行为,但它为未来可以跨语言与跨媒体工作的系统奠定了坚实基础。在实际层面上,这项研究使巴基斯坦更接近于拥有浏览器插件、新闻编辑室仪表盘或社交媒体过滤器,帮助人们在日常使用的语言中区分事实与虚构。
引用: Feroz, A., Abbasi, W., Babar, M.Z. et al. Verifying Urdu news authenticity using deep learning with concatenated BERT and GloVe embedding. Sci Rep 16, 7352 (2026). https://doi.org/10.1038/s41598-026-36771-0
关键词: 假新闻检测, 乌尔都语, 深度学习, BERT 与 GloVe, 在线虚假信息