Clear Sky Science · zh
通过异构 CNN-Transformer 编码与跨维语义融合提升远程深度估计
用一只眼睛看见深度
现代机器人、自动驾驶汽车和无人机经常依赖昂贵的三维传感器来判断目标的远近。这项研究展示了普通彩色相机(如智能手机中的摄像头)还能走得更远:作者设计了一种新方法,让计算机仅凭一张图片推断深度,且将注意力集中在场景中最难估计的部分——远处,那里的障碍物像素小、模糊且容易被误判。
为什么远处物体难以判断
从单张图像恢复深度——称为单目深度估计——是一种视觉技巧。近处物体占据大量像素并具有清晰纹理,因此现有神经网络在短距离和中距离表现良好。而在远处,汽车缩小为少数像素,道路标记在薄雾中消失。标准的卷积神经网络擅长捕捉细小的局部细节,但在把握整条街道的宏观结构方面存在困难。较新的 Transformer 模型能够很好地捕获全局上下文,但对细小边缘和纹理的敏感性较差。因此,这两类方法往往在安全导航最需要可靠估计的地方出现失误:远距离区域。
融合两种观察方式
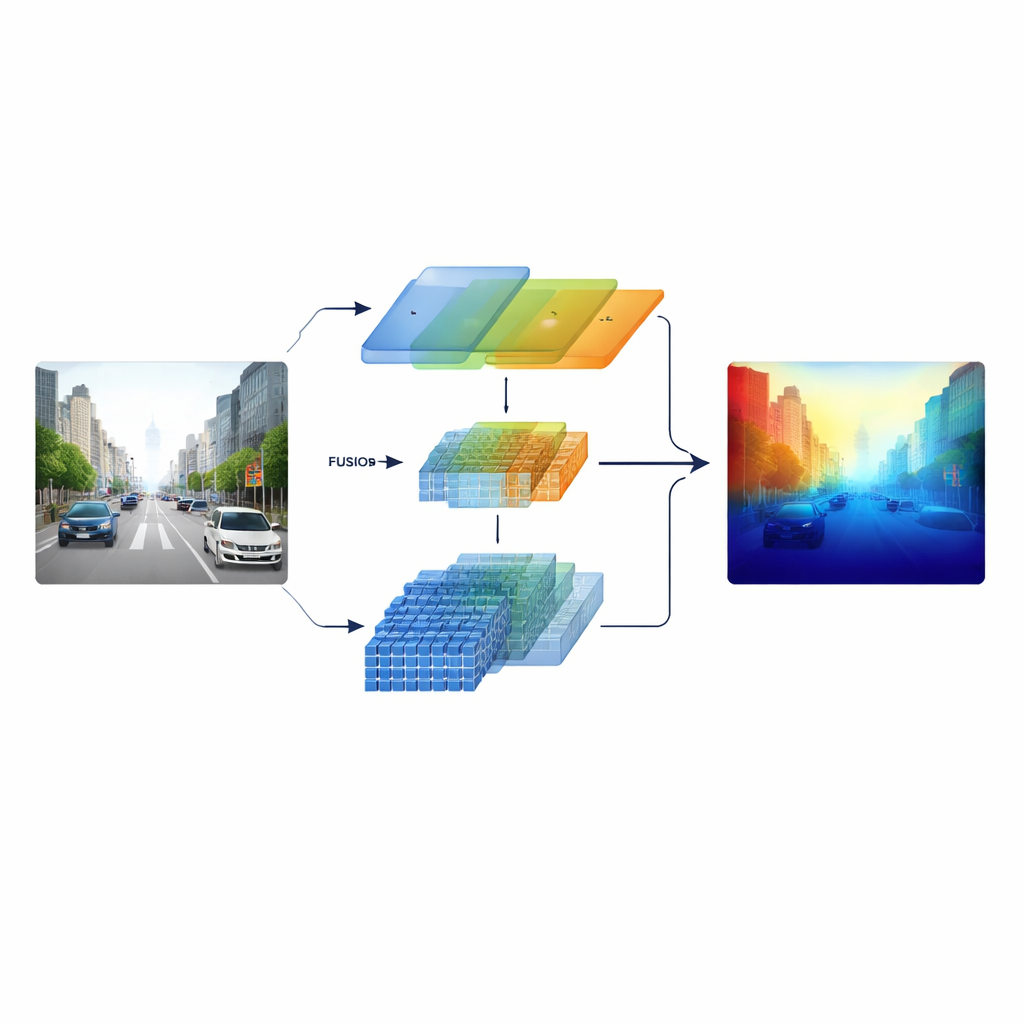
研究者通过构建一个“异构”编码器来解决这个问题,该编码器并行运行两种不同的视觉处理分支。一个分支基于经典的 ResNet 风格卷积网络,专注于清晰的局部模式,如车道标线、杆状物和物体边缘。另一个分支使用 Swin Transformer,旨在捕捉图像中跨越长距离的连接,例如道路走廊的布局或远处建筑的天际线。系统并非仅在末端合并这两种视角,而是保留来自两条分支的多尺度特征并将其送入精心设计的融合阶段,使细节结构与广域语境在整个过程中相互作用。
跨通道、空间与尺度的融合
模型的核心是一个跨维语义融合模块,它像一间智能会议室,供两条信息流交互。首先,它决定哪些通道——不同类型的学习到的视觉模式——应获得更多关注,平衡来自细节纹理和高级场景线索的信号。接着,它沿水平方向和垂直方向分别处理信息,这在充满道路、建筑和树木的场景中尤为有意义,以突出横跨图像的重要结构。最后,它在多个尺度上将浅层的细节丰富特征与更深的抽象特征混合。可学习的加权步骤让网络为每个区域决定信任各分支的程度,从而避免远处的小物体被近处场景淹没。
锐化最终结果图
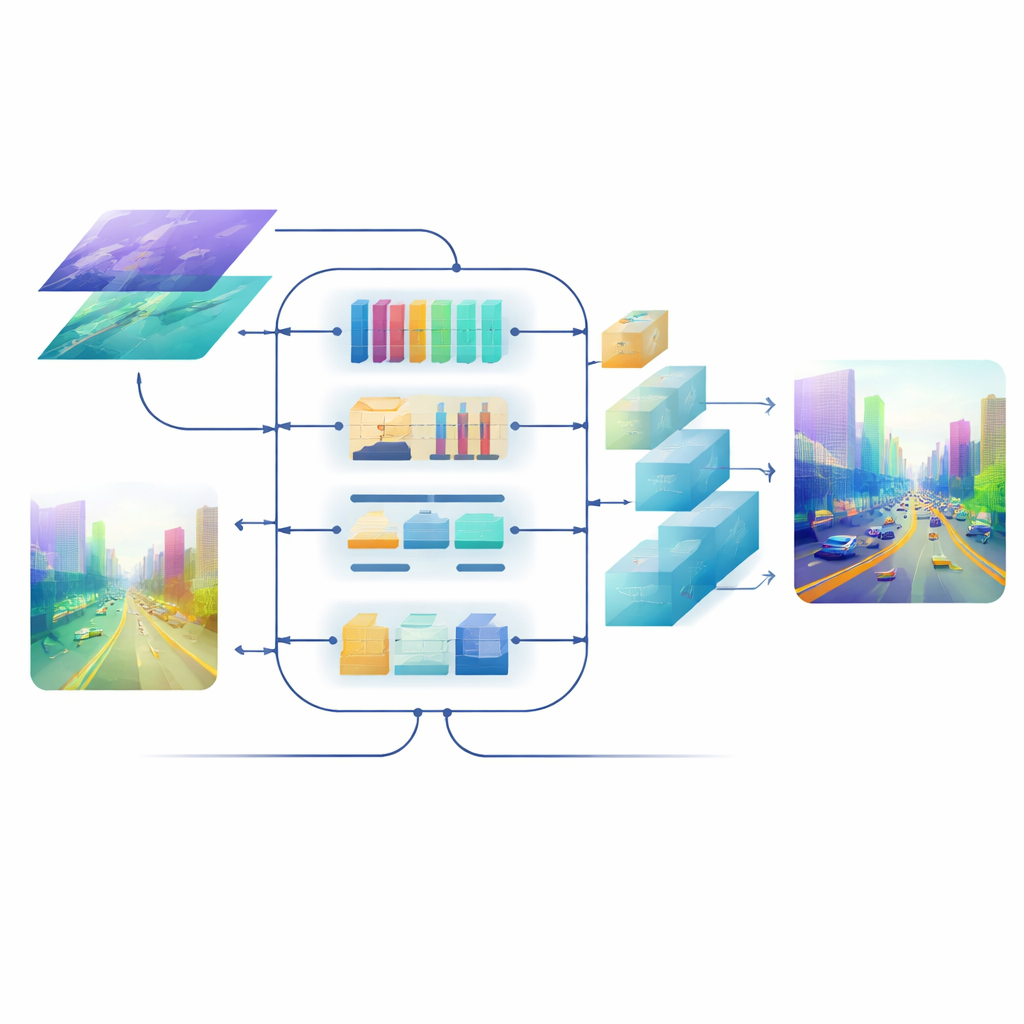
即便融合了良好的特征,将其恢复为全分辨率深度图也可能使边缘模糊、细薄结构被冲淡。为避免这一点,团队设计了一个由注意力驱动的解码器。其上采样模块使用轻量的深度可分离卷积在放大地图时保留上下文,且多尺度自注意力机制对特征通道进行分组,从而高效地计算注意力。该步骤在每个尺度上精炼深度预测,同时控制计算量。结果是一幅平滑且连贯的深度场景,物体边界——比如远处骑行者的轮廓或双层床的横档——保持清晰。
在真实世界中的表现如何
该方法在若干标准数据集上进行了测试。在 KITTI(一个大规模驾驶场景集合)上,模型在大多数常用评测指标上达到了最先进的准确度,并且关键的是,在指定的远程区域产生了最低的误差。它在物体边界的深度干净度方面也优于竞争系统。在包含室内场景的 NYU Depth V2 和 SUN RGB-D 基准上,同一模型成功泛化,能令人信服地以三维点云重建家具和房间布局。消融研究——通过移除或替换组件进行的系统性测试——表明,从混合编码器到融合模块以及解码器的注意力模块,每一部分的加入都能显著提高性能,尤其是在远距离低纹理区域。
这对日常技术意味着什么
简而言之,这项工作教会神经网络同时使用放大镜和广角镜头,并明智地将二者结合。通过更好地平衡局部细节与全局场景理解,所提出的框架显著提升了单目相机在远处道路或房间远端判断深度的能力。这使得在机器人、车辆和无人机上使用更廉价传感器变得更实际,同时仍能赋予它们丰富的三维感知——这是迈向更安全、更强大且更经济实惠的自主系统的重要一步。
引用: Chen, Y., Yin, Q., Zhao, L. et al. Enhancing long-range depth estimation via heterogeneous CNN-transformer encoding and cross-dimensional semantic fusion. Sci Rep 16, 9396 (2026). https://doi.org/10.1038/s41598-026-36755-0
关键词: 单目深度估计, 计算机视觉, Transformer 与 CNN 融合, 自动驾驶, 三维场景重建