Clear Sky Science · zh
核均值匹配在空间分布转移下提升风险估计
为什么在变动的地图下衡量模型风险很重要
机器学习模型越来越多地被用于预测物种分布、肿瘤在组织中的组织结构或污染如何扩散。然而用于训练这些模型的数据往往是在特定地点收集的——城市、医院或易到达的野外站点附近样本密集——而模型应用的区域通常更大且不同。数据来源地与预测应用地的不匹配会让模型看起来比实际更安全、更准确。论文“核均值匹配在空间分布转移下提升风险估计”提出了一个看似简单的问题:当现实与训练数据不同的时候,模型可能会出多大的错,我们如何判断?
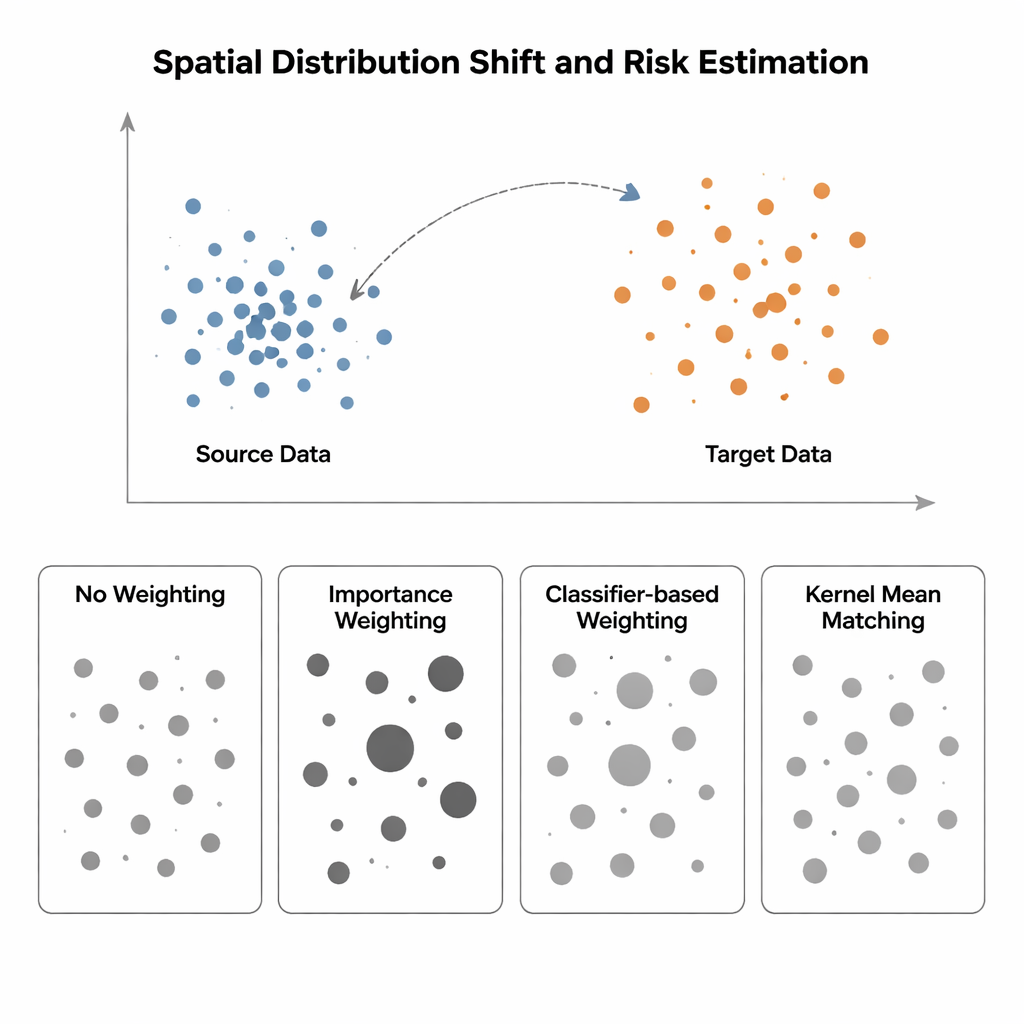
当训练与测试存在不同世界时
在统计学中,模型的“风险”是指其在新的、未见数据上的期望误差。标准评估方法——如交叉验证或随机留出测试集——隐含地假设训练和测试数据来自相同分布。空间数据打破了这一假设。环境梯度、簇状采样和气候变化意味着我们训练模型的条件可能与部署它的地方存在显著差异。例如,物种观测常集中在道路附近,而保护决策却关乎偏远地区;肿瘤样本可能取自组织的某一部分,但需要在其他部位进行预测。在这种情况下,传统的风险估计往往过于乐观,掩盖了模型在新位置可能出现的严重失效。
旧方法在应对空间偏差时捉襟见肘
研究比较了在输入分布从“源”区域(有标签)转到“目标”区域(标签稀少或缺失)时估计模型风险的四种方法。最简单的方法称为无加权,仅在可用数据上测量平均误差并假设源与目标相似——在空间偏差下这一假设会失效。重要性加权试图通过按在目标中相对于源的出现频率对每个源样本进行缩放来修正这一点。理论上这能恢复正确的风险,但实际上需要估计高维概率密度。当源数据紧密簇集而目标数据更为分散——这是空间生态或医学影像中常见的情形——这些密度估计变得不可靠,一些样本会获得极大的权重,使风险估计极不稳定。基于分类器的方法通过训练分类器来区分源点和目标点并将其概率转换为权重,避免了显式密度估计,但常常产生校准不佳的风险估计,因为它们优化的是分类准确率而不是分布对齐。
另一条路径:直接匹配分布
作者主张使用核均值匹配(KMM),这种方法完全绕开了密度估计。KMM不是试图计算每个点在源和目标分布下的概率,而是寻找源样本的权重,使它们在一个由核定义的灵活特征空间中的平均“特征”与目标样本匹配。直观地说,它通过拉伸或缩小每个源点的影响,使加权后的源样本云看起来像目标样本云。找到这些权重后,风险作为源误差的加权平均进行估计。一个互补工具——局部相关函数(Local Correlation Function)——用来量化数据在空间上的簇状程度;它可作为诊断,判断分布转移是否足够强,以致重新加权可能有效。
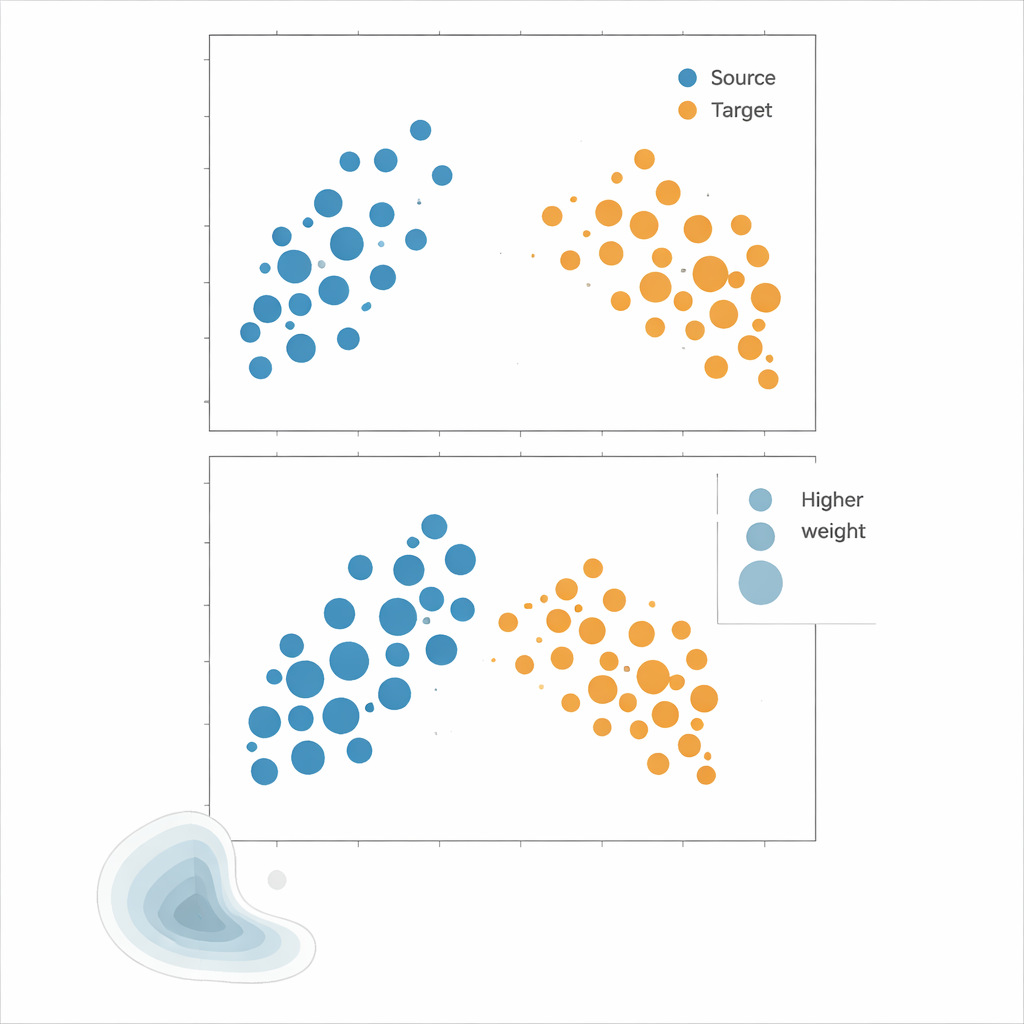
将这些方法付诸检验
为比较各策略的效果,作者在合成与真实世界数据上进行了大量实验。合成“景观”由高斯簇的混合构建,其扩散、形状和覆盖域可精确控制,便于进行结构化测试,如裁剪域的一部分、改变特征间的相关模式或在紧密簇集与近乎均匀的点模式间切换。真实数据集包括北欧植物物种记录(用气候与位置信息描述)以及肿瘤中免疫细胞的空间布局。在这些场景中,模型在簇集的源数据上训练,在较不簇集的目标数据上评估,以模拟常见的采样偏差。性能通过若干误差指标评估,重点是各方法估计的风险与目标上的真实误差有多接近。
在杂乱、高维空间中更可靠的风险估计
在几乎所有合成设置和真实数据集中,KMM给出最准确且稳定的风险估计。与其他方法相比,它将平均绝对百分比误差降低约12%到87%,并且关键在于避免了在高维情形下困扰重要性加权的“权重爆炸”。例如,在具挑战性的肿瘤细胞布局中,重要性加权可能导致误差超过数千个百分点,而KMM仍保持在可控范围内。基于分类器的重加权通常优于天真的方法,但仍落后于KMM,反映出其侧重判别而非忠实的分布匹配。这些结果表明,对于数据簇集、存在偏差且维度高的空间应用,KMM提供了一种有原则的方法来估计对模型预测应有多少信任。
这对现实决策意味着什么
对于在生态学、环境科学或生物医学中使用机器学习的非专业人士,结论很直接:当部署区域与数据来源不同,标准的测试分数可能具有误导性。核均值匹配通过重新平衡训练样本的影响,使它们在统计上更像你关心的地点或组织,从而提供了一种修正方法。研究显示,这种方法即便在严重的空间偏差和大量输入变量下,也能持续产生更诚实的模型误差估计。实际上,这意味着在模型选择时能得到更可靠的指导,也能更清楚地看出哪些预测是可信的——哪些则应保持谨慎。
引用: Serov, E., Koldasbayeva, D. & Zaytsev, A. Kernel mean matching enhances risk estimation under spatial distribution shifts. Sci Rep 16, 6921 (2026). https://doi.org/10.1038/s41598-026-36740-7
关键词: 分布转移, 空间建模, 核均值匹配, 模型风险估计, 生态与生物医学数据