Clear Sky Science · zh
在安全的检索增强生成系统中增强语义缓存的对抗鲁棒性
为何更智能的 AI 记忆至关重要
随着聊天机器人和 AI 助手进入职场、课堂甚至医院,它们越来越依赖一种称为“记住”过去问题的技巧,以便更快、更便宜地回答类似问题。这种记忆被称为语义缓存,它可以大幅降低成本和延迟——但也可能为攻击者打开后门,使系统泄露秘密或给出错误回答。本文探讨了这些潜在风险,并提出了一种新设计 SAFE-CACHE,旨在保持 AI 记忆的速度优势,同时大幅提高滥用难度。
当今 AI 助手如何重用过去的答案
现代大语言模型(LLM)常在一种称为检索增强生成(RAG)的架构中工作。当你提出问题时,系统先检索相关文档,然后让 LLM 利用这些材料生成回答。由于许多人以不同措辞提出几乎相同的问题,公司现在加入了语义缓存:存储旧的问题与答案以及它们含义的数学指纹。当新查询到达时,系统会检查其指纹是否与缓存中已存在的某个指纹“足够接近”;如果是,就直接重用旧答案,而无需再次执行完整的检索和生成过程。像 GPTCache 以及微软和谷歌的云平台等工具采用了该思路,能够在客户支持机器人、企业聊天工具和其他高流量 AI 服务中节省开支并加快响应速度。 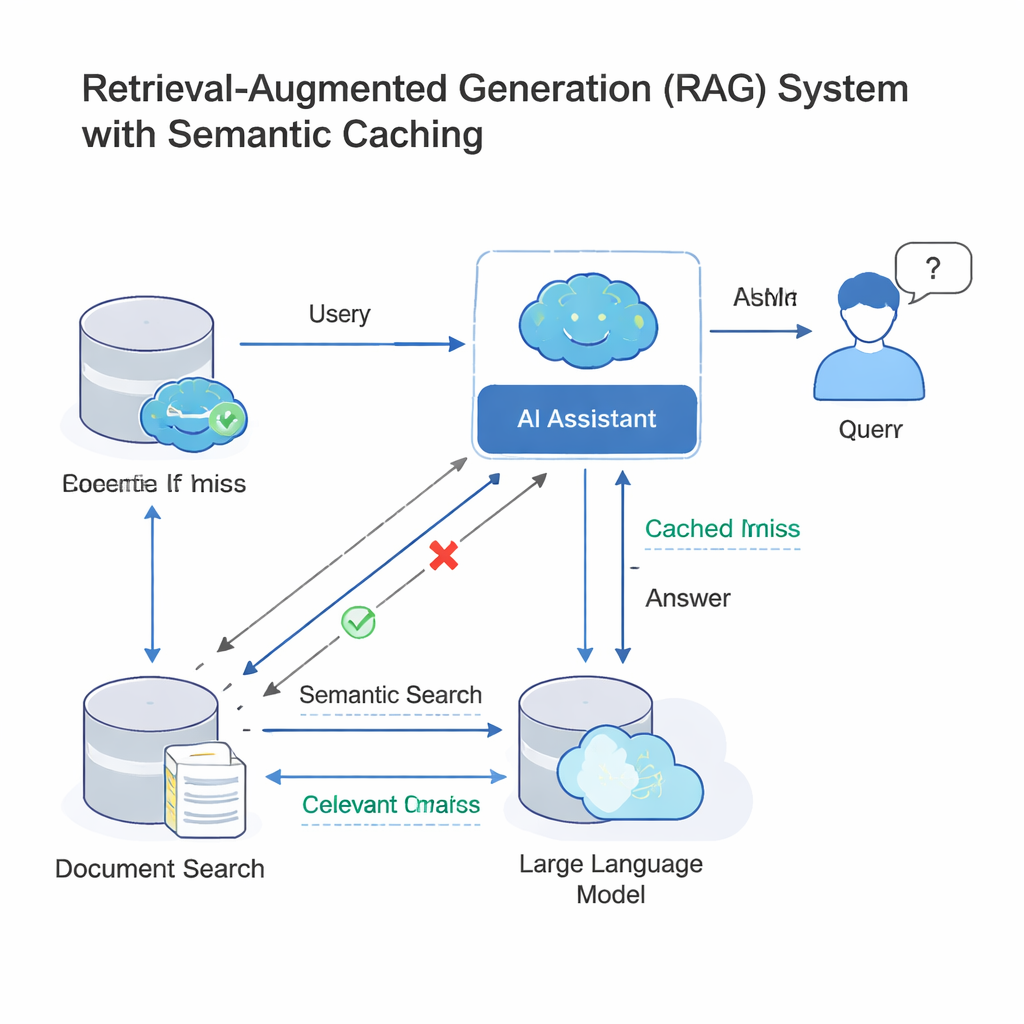
措辞巧妙时如何变成安全漏洞
这种加速的捷径也可能被利用来对付系统。攻击者可以精心构造查询,使其在结构上看似相似但含义不同——改变日期、替换人物或地点,或颠倒问题的含义。由于当今的缓存主要信任嵌入向量(这些含义指纹)的数值相似性,恶意查询可以在这个向量空间与良性查询发生“碰撞”,尽管意图已经发生变化。此类碰撞可能导致缓存返回错误答案,进而可能暴露机密信息或让错误数据被存入以备后用。已有研究表明,向量数据库和语义缓存容易被如此投毒,尤其是在多租户系统中大量用户共享同一缓存时。
将分散的问题变为稳定的意图簇
作者认为根本问题在于将每个查询孤立对待。他们的解决方案 SAFE-CACHE 将过去的问题-答案对分组为代表潜在意图的簇——例如“谁赢得了 2022 年亚利桑那州参议院选举?”或“特斯拉全自动驾驶软件的价格是多少?”SAFE-CACHE 不再将新查询直接与单个旧查询匹配,而是将其与每个簇的中心(即质心)比较。为构建这些簇,它首先对每个完整的问题加答案进行嵌入(而不仅仅是问题本身),以便回答中的差异——例如拒绝透露敏感数据——也能影响分组。然后使用社区发现算法找到自然簇,并用统计检验标记可能混合了不同意图或包含对抗性条目的嘈杂簇。对这些可疑簇使用专门训练的双编码器进行清理与拆分,该模型学会把诚实示例拉拢到一起、把被投毒的示例推离开来。
教一个小模型来强化 AI 的记忆
某些意图在实际流量中只出现少数次,使得其簇变得脆弱。为稳定这些簇,SAFE-CACHE 使用经过微调的轻量语言模型(一个 10 亿参数量级的 Gemma-3 变体)生成保持相同意图但措辞各异的释义。这些额外示例使簇更密集、质心更可靠,而无需人工标注成千上万的变体。在运行时,每个新查询都会被嵌入并与这些质心比较。如果其与最佳匹配质心的相似度超过经过精心调整的阈值,则返回缓存答案;否则系统回退到完整的 RAG 管道,并在之后决定如何对这个新的一对进行聚类。在基于变形重写和 GPT-4.1 的强攻击方法的实验中,SAFE-CACHE 将成功投毒的尝试相比于 GPTCache 风格的设计减少了大约三分之二到四分之三,同时保持了响应速度基本不变。 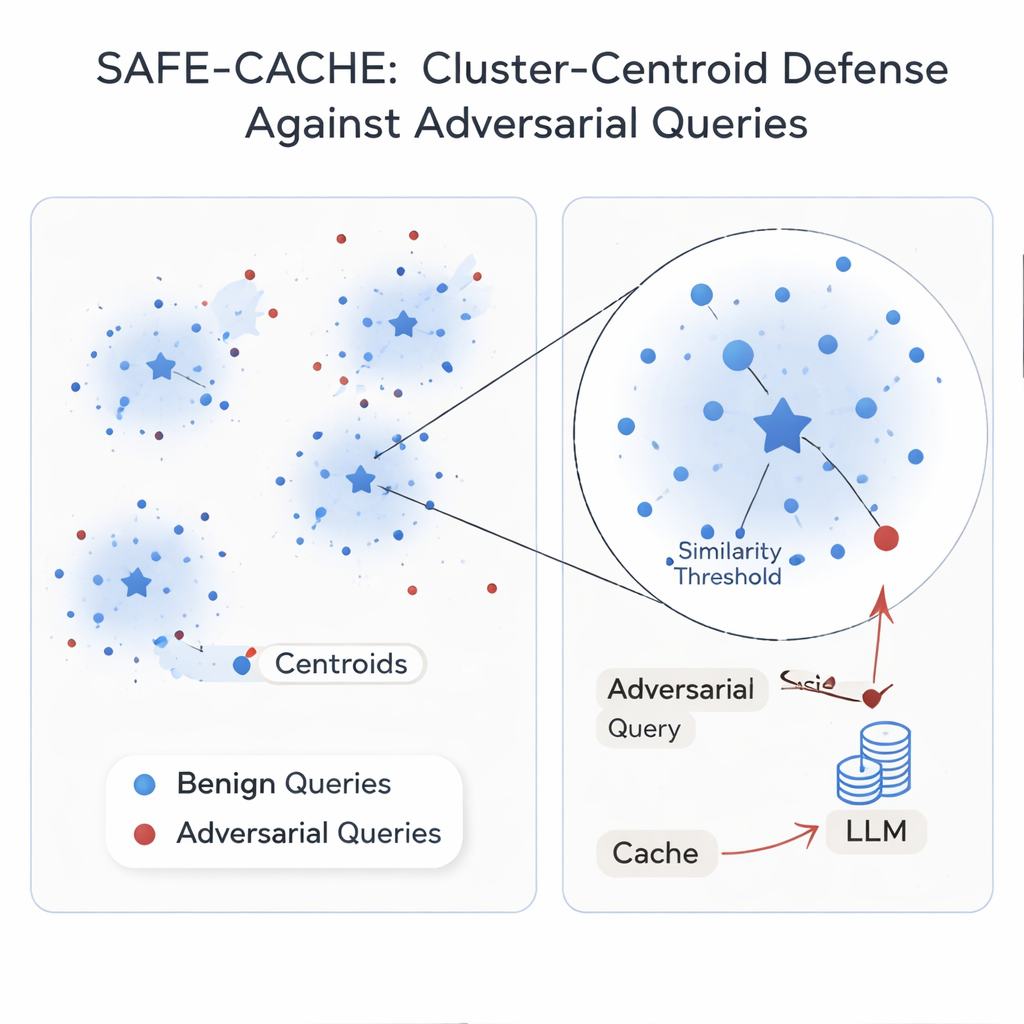
这对日常 AI 用户意味着什么
对非专业读者来说,结论是:赋予 AI 系统“记忆”并非没有代价:简单的设计可能导致秘密泄露或被诱导传播错误答案。SAFE-CACHE 表明,通过围绕更深层的意图模式组织记忆,并用有针对性的释义加强这些模式,可以在保持语义缓存的速度与成本优势的同时,大幅降低被攻击的风险。随着 AI 助手成为访问敏感数据(从公司记录到个人信息)的前门,像 SAFE-CACHE 这样的做法将是确保 AI 所记住的内容不会轻易被用来反对我们的关键。
引用: Afiffy, M., Fakhr, M.W. & Maghraby, F.A. Enhancing adversarial resilience in semantic caching for secure retrieval augmented generation systems. Sci Rep 16, 5936 (2026). https://doi.org/10.1038/s41598-026-36721-w
关键词: 语义缓存, 检索增强生成, 对抗攻击, 基于聚类的防御, 大模型安全