Clear Sky Science · zh
用于入侵检测系统降维的特征重要性引导自编码器
为何更智能的网络防御很重要
你发送的每封电子邮件、观看的每段视频和进行的每笔购买都在不断受到攻击的网络中传输。入侵检测系统(IDS)就像这些网络的报警系统,在入侵变成破坏之前发现可疑行为。但现代网络数据庞大且复杂,筛查所有细节会拖慢系统,或导致错过难以察觉的攻击。本文探讨了一种智能缩减数据的新方法,使 IDS 工具在加速的同时,更善于捕捉那些罕见且难以发现的网络攻击。 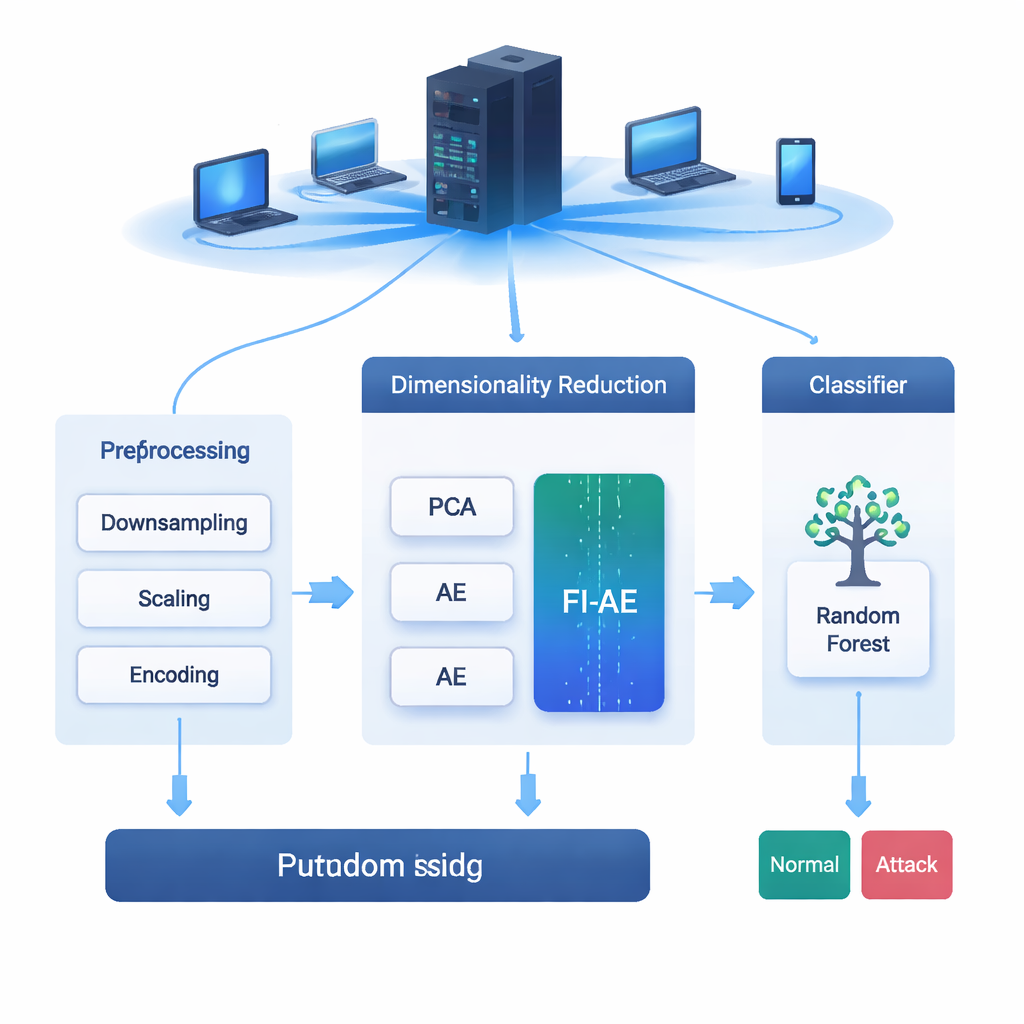
网络数据过载的问题
网络流量记录为每次连接包含几十到数百个度量——例如持续时间、字节数和错误率。基于机器学习的 IDS 模型依赖这些度量来判断流量是正常还是恶意的。然而,使用全部度量会降低检测速度,有时甚至损害准确性,尤其当某些攻击比其他攻击罕见得多时。常见的降维方法,如主成分分析(PCA)和标准自编码器,会压缩数据,但主要关注整体流量的重构。这意味着它们可能更关注占多数的常见连接,而忽视那些标示少数攻击类型的微弱、独特模式。
按真正重要的特征排序的新方法
作者提出了一种称为一对多(OVA)特征重要性的特征排序方案,以应对这种不平衡。与其问“哪些度量总体最有用?”,OVA 为每种攻击类型分别提出这个问题。对每一类(例如正常流量、拒绝服务或密码暴力猜测),训练一个随机森林模型来将该类与其他类区分开来。该模型的内置重要性分数随后揭示了哪些度量对该特定类别尤其有帮助。通过对每个类别重复此过程,然后对每个度量取其在任一类别中获得的最高重要性,该方法构建出一个单一的权重向量,突出那些至少对一种攻击类型重要的特征——即使该攻击在数据中很少见。
教自编码器关注关键信号
为了利用这些权重,研究者设计了基于特征重要性的自编码器(FI-AE)。与传统自编码器相似,FI-AE 将输入压缩为低维“瓶颈”表示,然后重构原始数据。不同之处在于训练目标:模型使用加权均方误差,不再将所有重构误差一视同仁,而是将每个特征的误差乘以其基于 OVA 的重要性。简单来说,FI-AE 对误表示那些对区分攻击至关重要的度量受到更重的惩罚,而对信息量较少的细节则惩罚较轻。其架构本身紧凑,将网络记录压缩到仅16个数,同时使用批量归一化、dropout 和 Adam 优化器等标准技术以保持训练稳定。
方法的实证检验
团队在三个广泛使用的入侵检测数据集上评估了 FI-AE:NSL-KDD、UNSW-NB15 和 CIC-IDS2017,这些数据集合计涵盖百万级连接和多种攻击类型。训练前,他们通过平衡极度偏斜的类分布、缩放数值特征以及以保留与目标标签关系的方式编码类别来清理数据。随后他们比较了三条都以随机森林分类器结束的管道:一条使用 PCA、一条使用标准自编码器、另一条使用 FI-AE 进行降维。在所有三个数据集上,FI-AE 一致地提供了更高的准确率和 F1 分数,尤其在传统方法通常表现不佳的少数和罕见攻击上,提升更为明显。 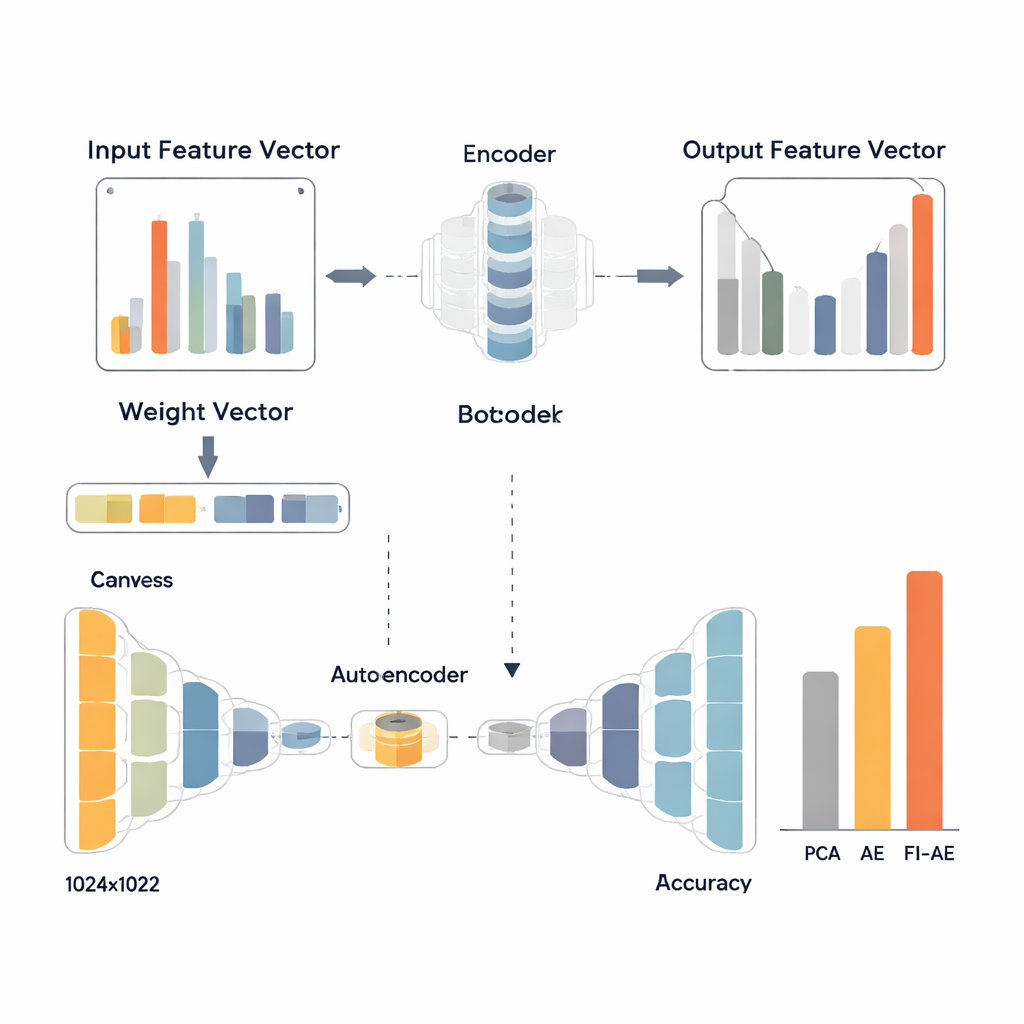
对日常安全的意义
对于非专业读者,关键结论是这项工作为网络监控提供了一种更有辨识力的视角。FI-AE 不只是简单地压缩数据以减小体量,而是学会保留那些对检测不同类型攻击真正重要的度量,包括那些可能最具破坏性的罕见攻击。仅用 16 个提炼后的特征,基于该方法构建的入侵检测系统能更高效地运行,同时仍能达到或超过最先进的检测准确度。实际上,这意味着安全工具可以扫描更多流量、更快响应,并为人们日常依赖的数字服务提供更好的保护。
引用: Abdel-Rahman, M.A., Alluhaidan, A.S., El-Rahman, S.A. et al. Feature importance guided autoencoder for dimensionality reduction in intrusion detection systems. Sci Rep 16, 5013 (2026). https://doi.org/10.1038/s41598-026-36695-9
关键词: 入侵检测, 网络安全, 降维, 自编码器, 特征重要性