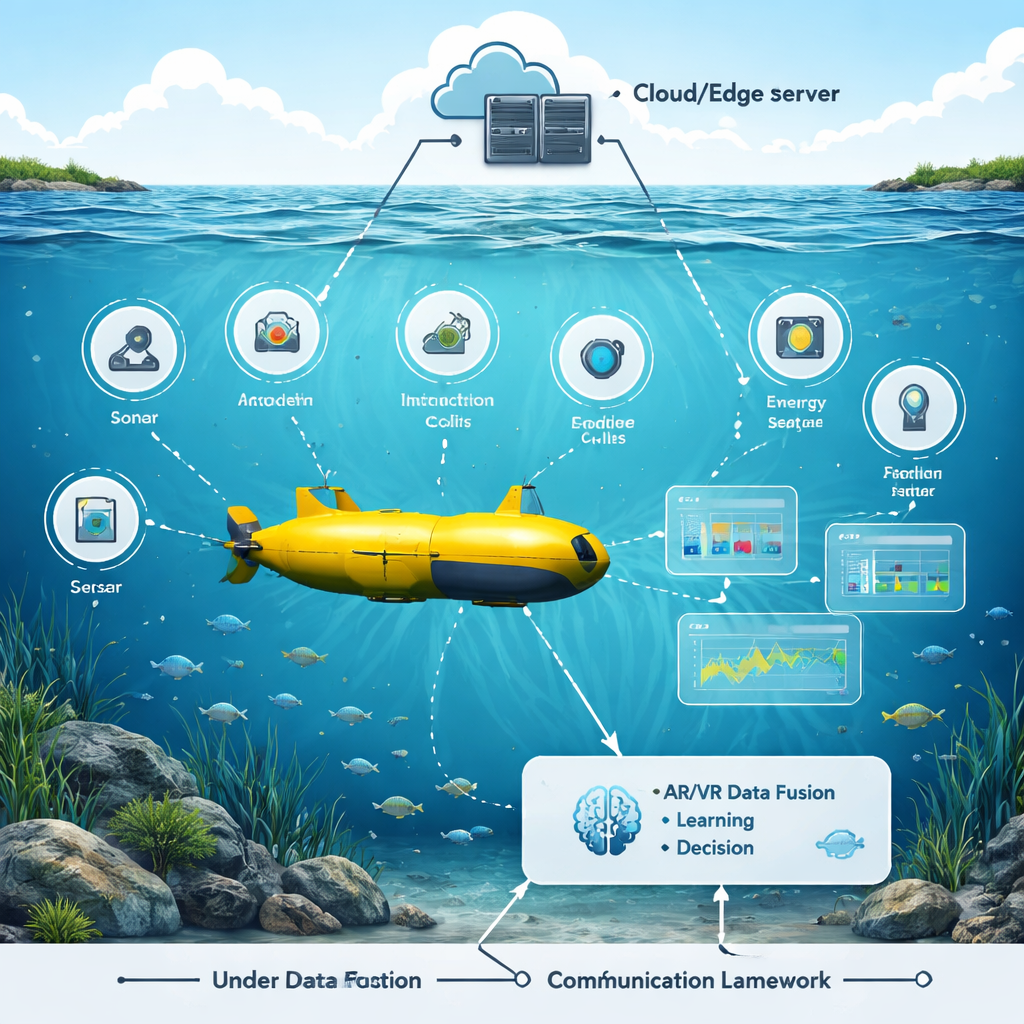
作者构建了一个增强和虚拟现实测试平台,重现了一个繁忙的水下世界:游动的鱼群、岩石、船只和浮标,以及真实的噪声和水中信号衰减。一个模拟的水下航行器在该环境中巡航,配备多种传感器——声纳、摄像头、声学调制解调器、能量计和位置追踪器。在虚拟场景中,研究人员可以滑动控制项来改变物体位置、水体条件和传感器设置,并立即观察机器人如何响应。该 AR/VR 层不仅仅是视觉效果;它将原始传感器数据融合为统一的 3D 图景,更便于 AI 系统理解并采取行动。
教机器人从经验中学习
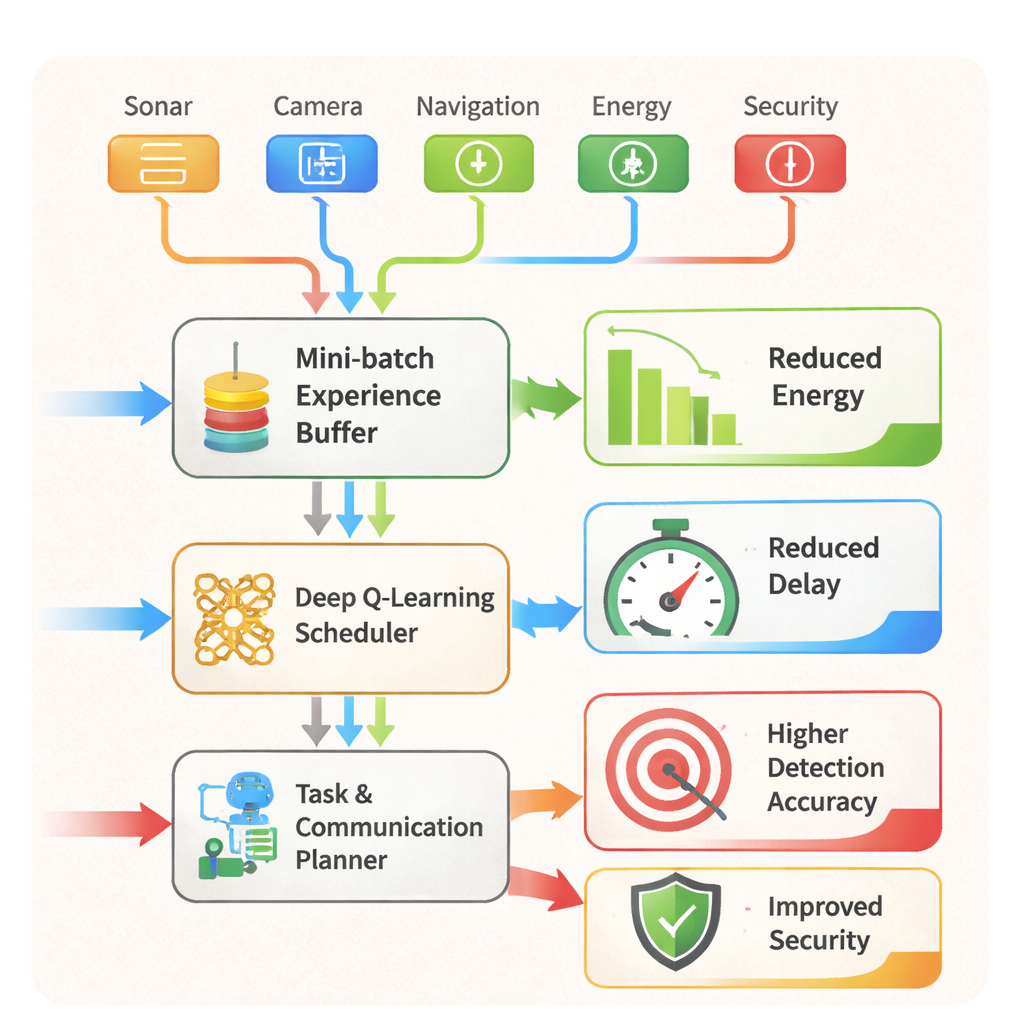
该框架的核心是一种作者称之为自适应增强现实与强化学习调度策略(Adaptive Augmented Reality and Reinforcement Learning Scheduling Strategy,AARLSS)的 AI 策略。机器人不再遵循固定脚本,而是在虚拟海洋中通过试错学习。每时每刻,它观察融合后的传感器状态,选择一个动作(例如改变航向、调整传感器采样率,或在短程与长程通信之间切换),并获得一个奖励。该奖励平衡了四个目标:节能、减少延迟、降低安全风险以及减少计算与网络资源的使用。一个深度 Q 学习网络存储并更新不同决策的期望值,利用保存在回放记忆中的过去经验小批量样本,让机器人能从近期和较早的情形中学习。
引用: Lakhan, A., Mohammed, M.A., Ghani, M.K.A. et al. A novel augmented reality and reinforcement learning empowered communication framework for underwater unmanned autonomous vehicle.
Sci Rep16, 6241 (2026). https://doi.org/10.1038/s41598-026-36647-3