Clear Sky Science · zh
用于智能学习环境的学生行为智能识别
为什么更智能的教室需要“看见”学生在做什么
在许多课堂中,教师不得不猜测哪些学生在跟上进度、哪些学生迷茫、哪些学生在悄悄走神。本文探讨了人工智能如何从普通课堂照片中自动识别学生正在进行的活动——例如阅读、书写或举手。通过将原始图像转化为可靠的课堂活动度量,该系统旨在在不依赖耗时的观察或具有侵入性的监控的情况下,为教师提供关于参与度的实时反馈。
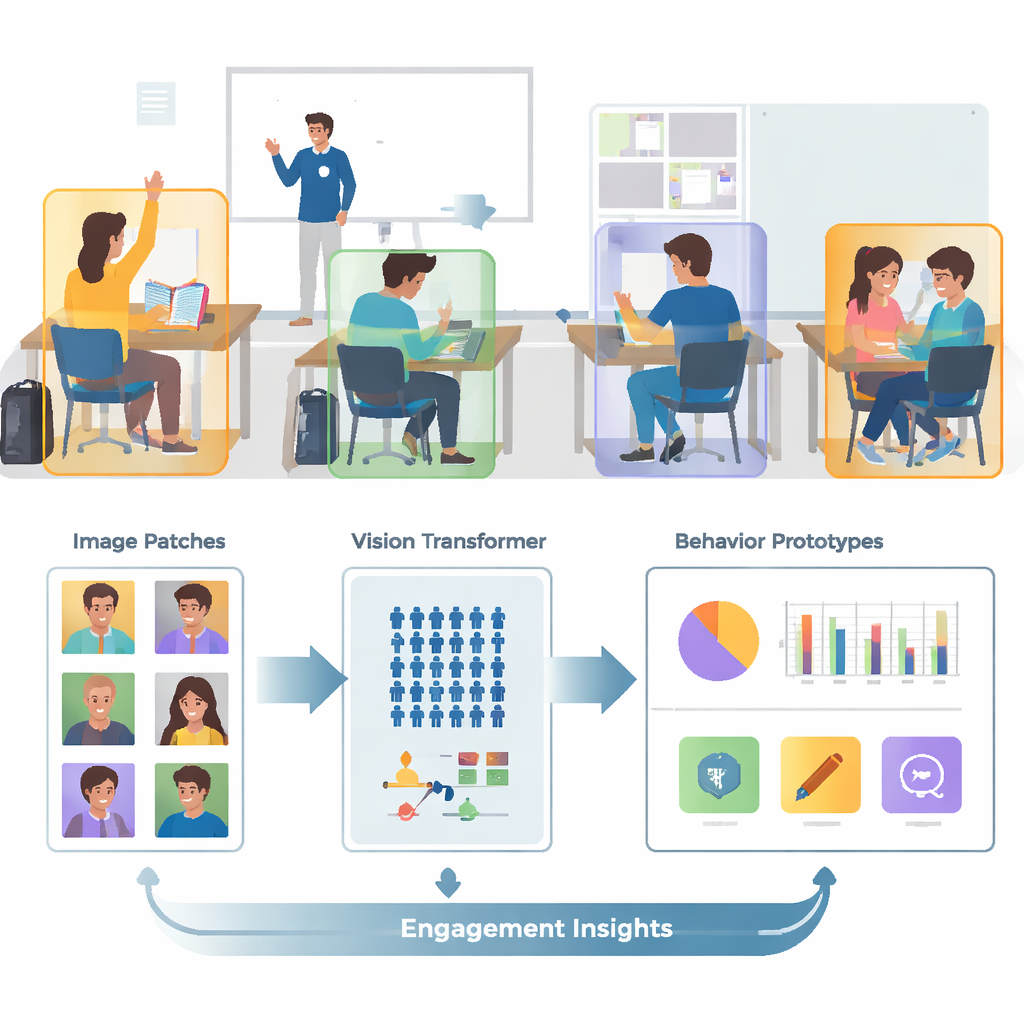
从杂乱的照片到聚焦的快照
真实课堂往往拥挤、繁忙且视觉上混乱。一张图像可能包含数十名学生、重叠的身体以及诸如墙面、投影屏和海报等干扰性背景细节。作者基于一个名为 SCB‑05 的公共图像集合构建,该集合包含数千张标注了特定行为的课堂照片——例如举手、阅读、书写、站立、讲话或在黑板前互动。系统并非将整个场景输入到计算机,而是先使用标注文件裁剪出每位学生或教师周围的区域。此预处理步骤去除了大量视觉杂波,使模型能够专注于姿势、手的位置以及区分不同行为的其他线索。
AI 如何从极少样本中学习新行为
一个主要难题是某些课堂行为在数据中很常见(如阅读),而另一些则很罕见(如短时登台互动)。为每种可能的行为收集足够的标注图像既昂贵又会带来隐私问题。为了解决这一点,作者使用了一种称为“少样本学习”的策略,即让模型能够仅从少量示例中识别新类别。他们将训练组织为许多小任务,每个任务只包含少数行为和每种行为的少量样本图像。对于每个任务,系统通过对这些示例的内部表征取平均来形成每种行为的简单“原型”。然后通过查看新图像与哪个原型最接近来进行分类,使模型即使在数据稀缺时也能快速适应。
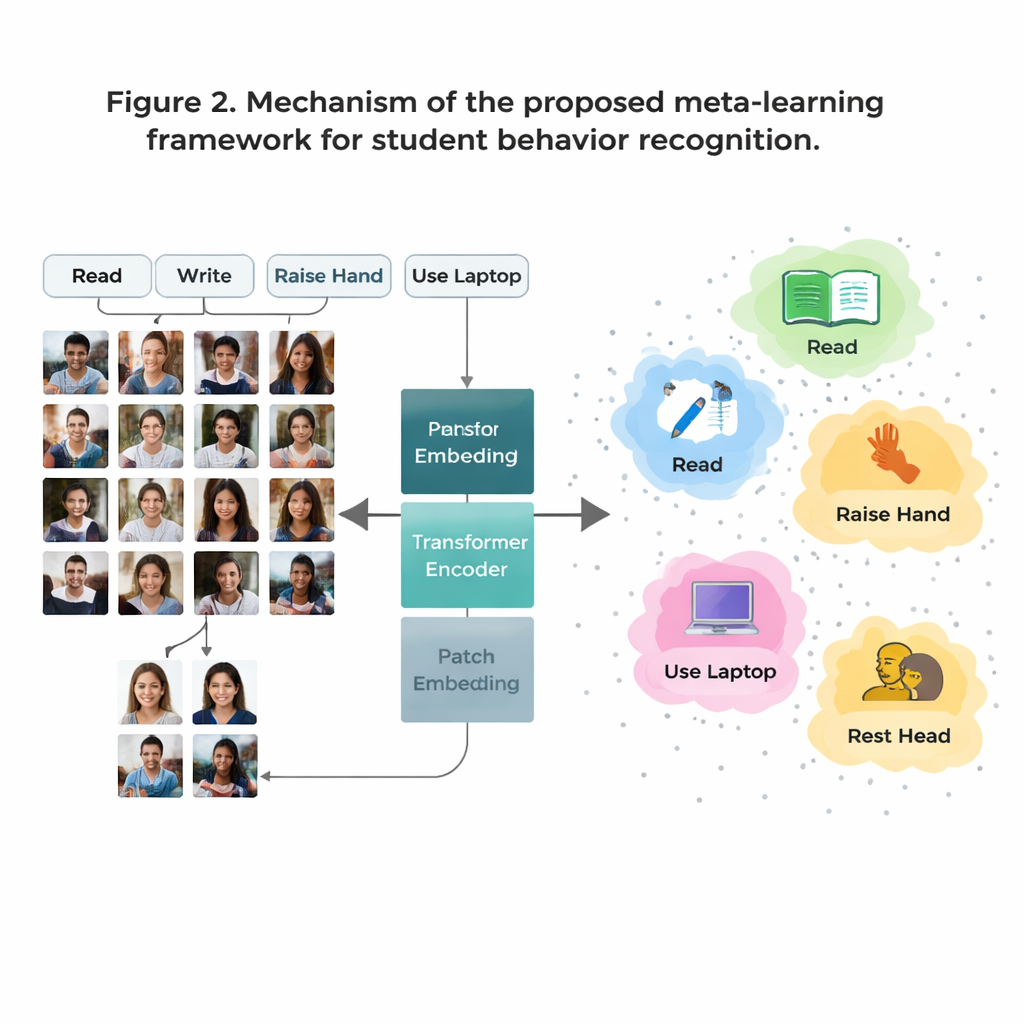
看到整个教室,而不仅仅是局部细节
传统的卷积神经网络通常侧重于小的局部模式,如边缘或纹理。当两种行为(例如阅读与书写)在局部看起来非常相似时,这种方法会有局限。本文用视觉变换器(Vision Transformer)替代了这些旧网络,变换器将每张图像分割为若干补丁并学习所有补丁之间的相互关系。这种全局视角有助于系统理解细微的姿势差异和长距离提示——例如举手与置于教室前方的教师之间的关系。团队进一步通过训练使相同行为的图像靠拢、易混淆但不同的行为互相远离,并对“难分”混淆案例给予额外关注,从而使模型更为敏锐。这使得行为的内部映射更清晰、更容易区分。
效果如何以及为何重要
在 SCB‑05 基准上,所提方法总体准确率约为 91%,并在考虑类别不平衡的更严格度量上也有较好表现。常见行为如阅读和举手的识别特别优秀,而较罕见的行为如在黑板上写字仍更具挑战性,但比早期系统表现更好。对模型内部聚类的可视化检查表明,不同行为形成了紧凑且彼此分离良好的群组,表明 AI 已经学会了课堂动作的不同“特征签名”。在另一个具有不同摄像角度和布局的课堂数据集上测试时,性能仅略有下降,这暗示所学表征并不限于单一教室或学校。
这对教学与学习意味着什么
通俗地说,该研究表明计算机可以可靠地从静态图像中识别许多关键的学生行为,即便每种行为只见过很少的例子。此类系统并非要取代教师,而是可以在不追踪学生身份的前提下,默默地汇总谁更投入、谁经常寻求帮助或哪些活动容易导致注意力下降。随着在隐私、公平性和视频时序分析方面的进一步工作,这类对行为敏感的 AI 有望成为教育工作者设计更有响应性和包容性的学习环境的有力助手。
引用: Abozeid, A., Alrashdi, I. & Al-Makhlasawy, R.M. Intelligent recognition of students’ behavior for smart learning environments. Sci Rep 16, 5674 (2026). https://doi.org/10.1038/s41598-026-36633-9
关键词: 智慧教室, 学生行为, 计算机视觉, 少样本学习, 视觉变换器