Clear Sky Science · zh
使用非参数认知诊断建模对医疗领域大型语言模型进行细粒度评估
这对未来就诊有何意义
会说话和写作的人工智能系统,即大型语言模型,正在迅速从研究实验室进入医院。它们已经能够帮助医生解读复杂病历、建议治疗方案并回答医学问题。但对这些系统的大多数测试仅给出一个总体分数,类似期末成绩,这可能掩盖危险的盲点。本研究展示了一种新方法,能够在这些分数内部深入剖析,明确揭示模型真正掌握了哪些医学领域——以及在哪些方面仍可能对患者构成风险。
超越单一考试分数
目前,大多数医学人工智能的评判基于它在仿照医生执业考试的题目上答对多少题。这个方法简单但粗糙。一个模型可能获得很高的总体分数,但在诸如心律分析或肝病等关键领域仍然薄弱。在真实临床环境中,这类差距可能关系到生死。作者认为,要安全地在医疗中使用人工智能,需要更深入、更细粒度的评估——能够绘制出详细的技能画像,而不是只给出一个可能误导人的分数。

更智慧的医学知识测试方法
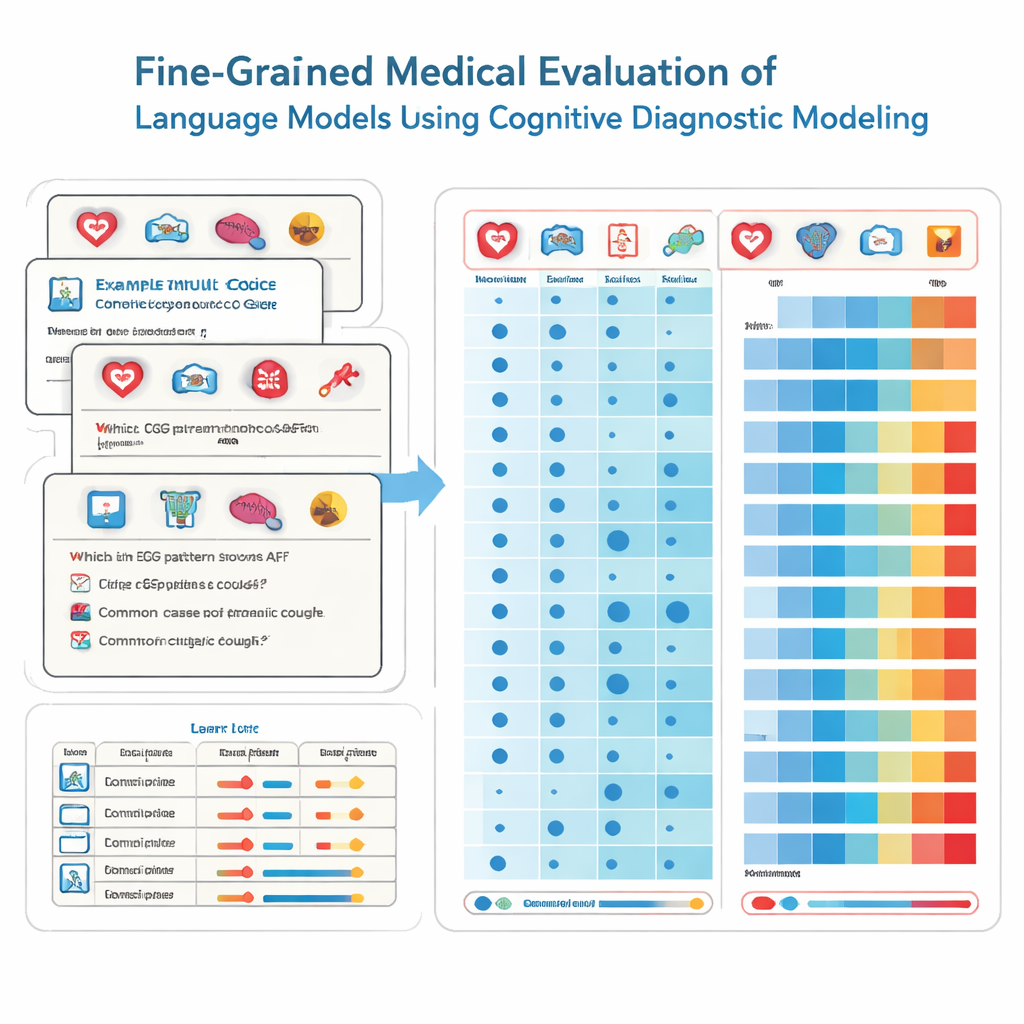
为此,研究者借用了教育心理学中的工具,称为认知诊断评估。该方法不再把每道试题视为测量同一模糊能力,而是将医学知识拆解为具体的构成要素,如心脏病学、影像学或急诊护理。每道选择题都会标注所需技能的精确组合。研究团队使用一种非参数统计技术,将模型在数千道题上的作答模式与理想应答模式进行比较。由此推断模型是否“掌握”每一项底层技能,就像详尽的成绩单会显示各科优劣一样。
将41个模型置于医学考试中检验
研究团队在2,809道经严格审查的题目上测试了41个广泛使用的语言模型,包括商业系统和开源模型。这些题目取自中国国家医考题库,覆盖22个医学子领域,面向即将参加医师执业考试的学生。每道题都有一个正确答案,并由专家标注涉及的专科。利用他们的诊断方法,研究者为每个模型估计了它实际掌握了多少个这22项医学属性,而不仅仅是它恰巧答对了多少题。
广泛的常识良好,但存在明显盲点
结果既令人印象深刻又令人担忧。表现最好的模型,例如若干主要商业系统,在大多数题目上答对并在22个医学领域中掌握了20个。所有模型在许多常见专科中的表现总体优秀,在包括心脏病学、皮肤科和内分泌学在内的15个领域实现了完全掌握。然而,细粒度分析暴露出在其他领域的明显缺陷。影像学的掌握率明显落后,且有两个子领域——心电图与高血压及血脂和肝脏疾病——没有任何模型实现掌握。值得注意的是,一些较小的模型在已掌握的技能上与更大型的模型相同,这表明模型规模本身并不能保证广泛、可靠的医学知识。
为合适的任务选择合适的工具
这些详细的画像很重要,因为总体分数非常相近的模型,其强项和弱项的分布可能截然不同。一个系统可能在神经学方面很强但在药理学上薄弱,而另一个则呈相反模式。对医院管理者而言,不能仅凭头条考试分数或参数数量来安全地选择AI助手。相反,他们需要像本研究提供的诊断结果,将每个模型与具体临床任务匹配,并在模型已知薄弱的高风险领域设计由人类专家复核AI输出的工作流程。
这对患者和临床医师意味着什么
简而言之,研究得出结论:在医学考试上获得高“分数”并不保证人工智能系统在医学所有领域都可安全使用。这种新方法更像是对AI自身进行的全面体检,揭示哪些“器官”——在此为医学专科——是健康的,哪些需要关注。通过揭示心电图解读和肝病等关键领域的隐藏缺口,该方法为医院、监管者和开发者提供了切实可行的路线图:仅在模型被证明强项的领域使用它们,在存在薄弱点的地方保持人工参与,并将未来训练聚焦于最具风险的盲点。作者认为,这种细粒度评估不仅有用——在将AI交付患者护理之前,它是必要的。
引用: Zheng, T., Liu, J., Feng, S. et al. Fine-grained evaluation of large language models in medicine using non-parametric cognitive diagnostic modeling. Sci Rep 16, 6460 (2026). https://doi.org/10.1038/s41598-026-36627-7
关键词: 医疗人工智能, 大型语言模型, 临床安全, 模型评估, 诊断测试