Clear Sky Science · zh
用于自我引导优化的分层特征学习的多任务优化与收敛稳定性
更聪明的 AI:能够同时处理多项任务
现代应用越来越依赖需要同时完成多项工作的人工智能——例如同时理解图像和文本、支持医疗决策或帮助车辆感知道路。但当一个 AI 模型同时学习过多技能时,训练可能变得不稳定,技能之间也会相互干扰。本文提出了一种新的深度学习框架,称为统一多任务多视图深度架构(UMDA),旨在让单个模型从多种数据类型中学习并解决多项任务,而不致混淆或不稳定。
为什么当前的多技能 AI 往往难以胜任
大多数当前同时学习多项任务(多任务学习)或结合多种数据类型(如图像与文本,多视图学习)的系统存在三大问题。首先,不同任务在训练时可能相互冲突:提升某一任务的性能会悄然损害另一任务,这被称为负迁移。其次,简单地堆叠或平均来自不同数据源的信息,经常会丢失它们之间微妙但重要的关联。第三,训练过程本身可能变得不稳,模型参数更新的方向出现大幅波动。在像医疗诊断或工业检测这样数据复杂且决策必须可靠的真实场景中,这些问题尤为严重。
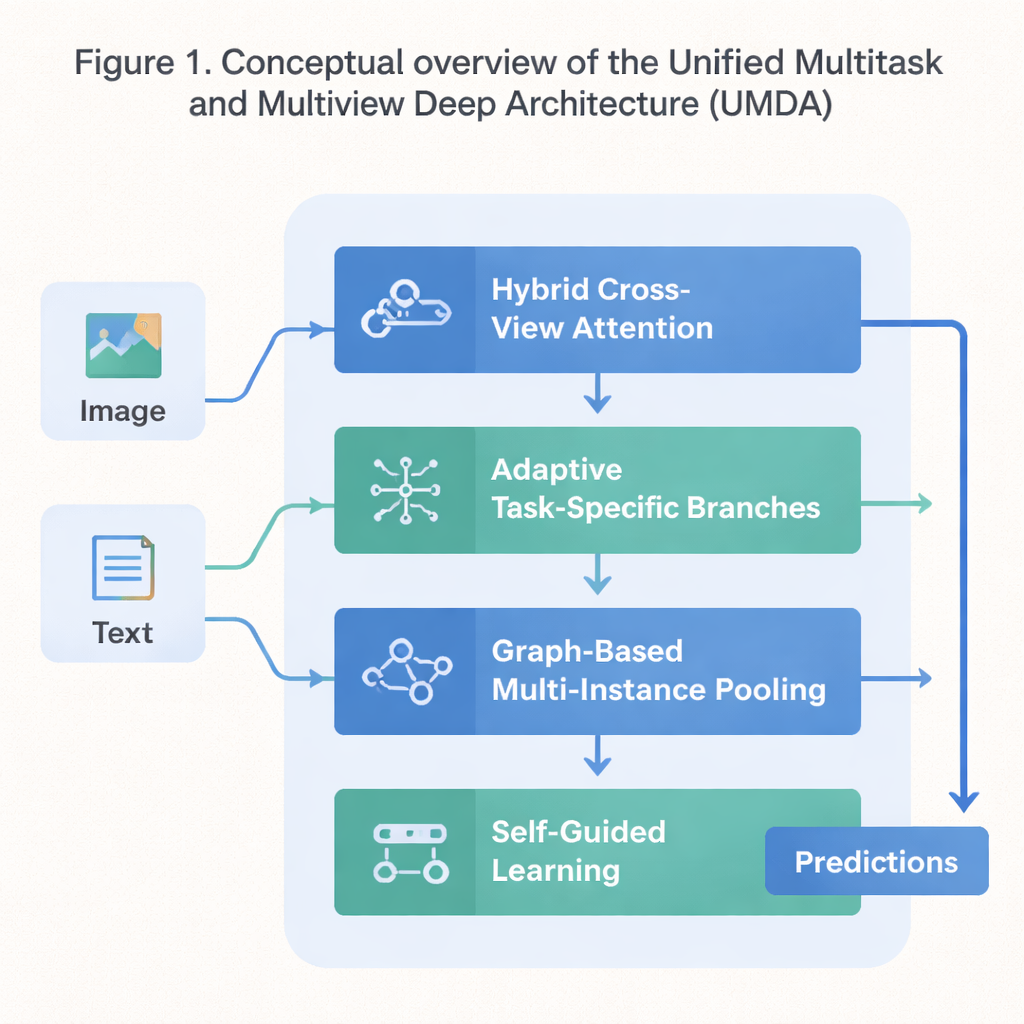
用于协同学习的四部分蓝图
UMDA 通过将学习过程分为四个紧密相连的部分并以受控方式共享信息来应对这些弱点。第一部分称为混合跨视图注意(Hybrid Cross‑View Attention),它观察同一数据的不同视图——例如描述一部电影的文字与图像——并学习在每一步应由哪个视图影响另一个视图。它使用数学工具,鼓励模型避免过度依赖单一视图,使每个视图保持区分性,同时在整体上保持一致。简单来说,就是教模型倾听所有“感官”,而不让某一种感官压倒其他感官。
保持任务独立同时仍能协作
第二部分,自适应任务特定分支(Adaptive Task‑Specific Branching),将许多任务共享的通用知识与每个任务独有的专用知识区分开来。UMDA 并不强制所有任务使用完全相同的特征,而是为每个任务构建可通过精心加权的连接相互通信的独立“分支”。训练目标中的额外惩罚项促使这些分支在足够不同以实现专门化的同时,又不会分化得无法协作。这种平衡有助于减少任务间的有害干扰,同时仍能让任务相互受益。
在样本集合中发现结构
许多真实数据集以相关项的集合形式出现——例如来自同一张病理切片的多个图像补丁或来自同一视频的多帧。UMDA 的第三部分,基于图的多例汇聚(Graph‑Based Multi‑Instance Pooling),通过将这些项视为网络中的节点来显式建模它们之间的关系。它连接相似项,让信息沿这些连接流动,随后将整个集合汇总为单一的紧凑表示。额外的正则化促使相邻项相互一致,同时保留足够的多样性,使模型能够捕捉到简单平均会错过的结构模式。
自我调节的训练以保持稳步进展
最后一部分,自我引导学习(Self‑Guided Learning),关注的是模型的训练方式而非内部结构。它持续测量每个任务的训练信号有多强和多相似,然后自动调整各任务的学习速率。它还平滑并重新加权梯度——那些告诉模型如何改变的信号——以便目标相似的任务互相强化,而目标方向差异很大的任务不会使训练失稳。在将 UMDA 在一个混合电影情节与海报的标准数据集上测试时,UMDA 在平均准确率上超过了十多种先进方法,保持了视图之间更一致的关系,并将训练不稳定性的关键度量降低了超过一半。
这对现实世界 AI 系统意味着什么
对非专业读者来说,关键信息是 UMDA 提供了一种构建单一 AI 模型以更可靠地处理多种数据类型和目标的方法。通过教会模型何时共享信息、何时保持独立,并允许其自动调整学习方式,该框架带来更好的预测、更连贯的内部表示以及更平稳的训练。这使其成为医疗、自动驾驶及其他需要同时解读多重信号而又不能失衡的复杂应用的有前景的构件。
引用: Mahmood, K., Althobaiti, M.M., Hassan, M.U. et al. Multitask optimization and convergence stability with hierarchical feature learning for self guided optimization. Sci Rep 16, 6414 (2026). https://doi.org/10.1038/s41598-026-36622-y
关键词: 多任务学习, 多模态人工智能, 深度学习稳定性, 注意力网络, 图神经网络