Clear Sky Science · zh
一种用于听力障碍者古兰经教育的自动化框架:基于身体姿态分类与阿拉伯手语整合
为无声的声音打开一部圣典
对于许多聋哑和重听的穆斯林来说,学习背诵古兰经可能非常困难,因为传统教学依赖听觉和反复跟念。这项研究提出了一种基于技术的教学辅助工具,它“看见”阿拉伯手语的手势并将其与古兰经一章的经文相连接。通过将身体动作转化为手语与经文之间的桥梁,目标是让主要以手语交流的数百万人也能更包容地参与宗教学习。
为何听力障碍学习者被排除在外
聋人穆斯林常以手势和手语交流,但大多数古兰经教育以声音为中心——教师大声朗诵,学生模仿旋律和发音。家庭成员可能不熟悉手语,合格的手语翻译尤其在宗教内容方面稀缺。因此,许多聋人信徒难以获得与听力同伴相同层次的精神教育。近年来计算机视觉与人工智能方面的进展可以从摄像机图像中识别手部和身体动作,提供了将手语转化为计算机可理解并可实时响应的信息的途径,从而改变这种状况。
把手势转化为可教学的单元
研究者将注意力集中在《纯一章》(Sūrat al-Ikhlāṣ)上,这是一章简短但神学含义深刻的章节,许多穆斯林早年就会背诵。与为聋人服务的机构合作,他们记录了2,054张对应于该章单词的阿拉伯手语手势图像。为避免在含义和发音上的混淆,每个手势都使用阿拉伯文字和学界常用的标准音译系统进行标注。这种谨慎的标注确保系统将每个手势与正确的古兰经词项连接,同时保留未来扩展到其他章节的灵活性。
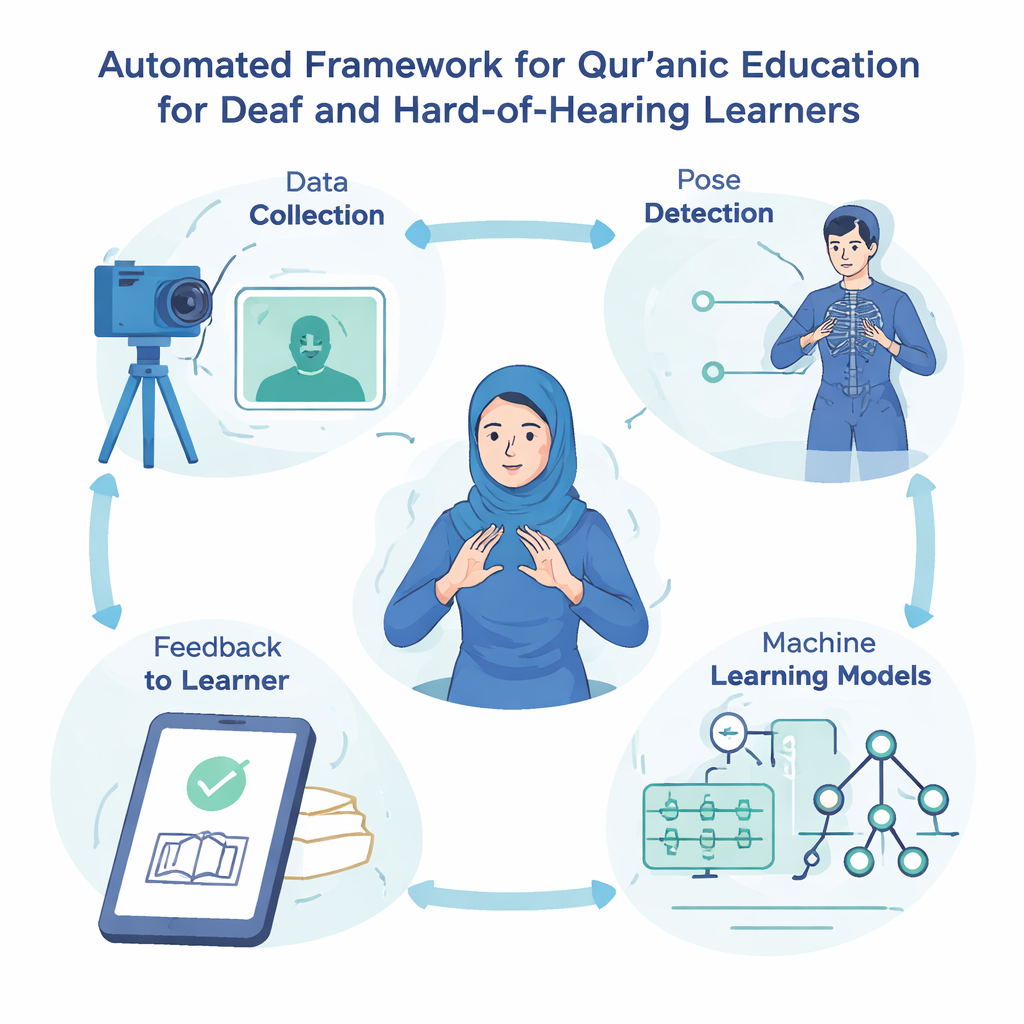
计算机如何学会“看见”祈祷的姿势
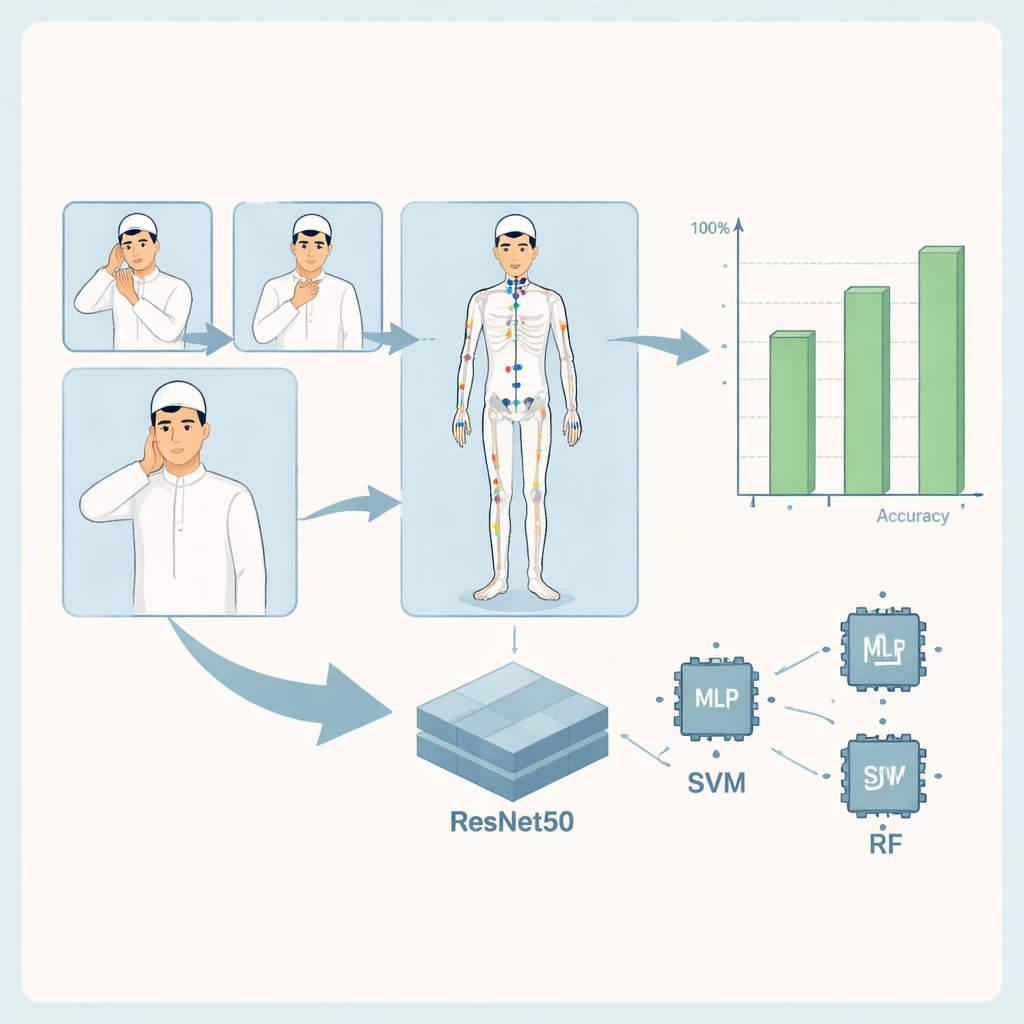
系统的核心是一个视觉处理流程,先检测签署者的身体姿态,然后分类出正在比划的古兰经词语。所有图像都被调整大小并清理为标准格式。一个名为 MediaPipe 的软件工具包识别出身体上的33个关键点——例如肩膀、肘部和手腕——并跟踪它们的位置。这些坐标构成每个姿态的紧凑描述,然后被输入三类机器学习模型:自定义多层感知机(一个简单的神经网络)、支持向量机以及由许多小决策树组成的随机森林。与此同时,一个更强大的深度学习模型 ResNet50 会分析完整图像,学习与每个词相关的详细视觉模式。
对古兰经手语的识别精度令人瞩目
为测试系统,作者将数据集划分为训练、验证和测试集,并评估每种模型识别手势的准确性。所有方法表现都很强,其中基于姿态的模型在14–16个古兰经词类中正确识别了大多数手势。例如,随机森林模型对许多词项几近完美,仅在外观相似的手势间出现少数混淆。基于 ResNet50 的综合模型在直接观察图像并借助姿态信息的情况下,在测试数据上几乎达到了完美表现:每个手势都被正确分类,准确率、精确度、召回率以及称为 ROC–AUC 的判别评分都达到了最大值。这些结果表明,即便是经过精心准备的相对较小的图像集合,也能支持对宗教手语的高精度识别。
希望、局限与前路
尽管性能指标令人印象深刻,作者强调这些结果仅适用于他们研究中的受控条件:单一章节、有限数量的示范者,以及静态图像而非连续动作的手语。现实使用需要更大、更具多样性的数据集、更全面的下肢动作覆盖,以及与来自不同地区的示范者进行的严格测试。尽管如此,这项工作表明现代视觉与学习工具可以可靠地识别古兰经手语并提供即时反馈,例如当学习者比划手势时显示对勾或纠正性动画。通俗地说,这意味着聋人学生可以在简单摄像头前练习古兰经经文并获得指导,而无需现场翻译——这是使圣典知识更普及的重要一步。
引用: AbdElghfar, H., Youness, H.A., Wahba, M. et al. An automated framework for qur’anic education of the hearing-impaired using body pose classification and Arabic sign language integration. Sci Rep 16, 5939 (2026). https://doi.org/10.1038/s41598-026-36578-z
关键词: 古兰经教育, 阿拉伯手语, 听力障碍学习者, 姿态识别, 辅助技术