Clear Sky Science · zh
一种结合注意力机制的混合 ResNet50-视觉变换器模型用于航拍图像分类
为什么更聪明的“天空之眼”很重要
来自无人机和卫星的航拍照片如今用于指导灾害响应、城市规划、农业甚至交通管理。但是让计算机理解这些从高处拍摄的复杂且杂乱的视图仍然很难。本研究提出了两种新的人工智能模型,它们结合了不同的“看”图像的方式,以识别无人机照片中的十类对象——例如建筑、汽车、树木和道路——其准确率优于以往方法。这种方法可能使空中自动监测更快、更可靠,并更易于在实际环境中部署。
从上方看世界的挑战
航拍图像不同于我们用手机拍摄的日常照片。物体更小、可能以奇怪的角度出现,且常常密集地排列在一起。一辆被树部分遮挡的汽车、一条狭窄的人行小径,或山体滑坡后的碎堆,即便对人类来说也可能难以迅速识别。然而,政府、应急队伍和环境机构越来越依赖无人机与卫星视图来跟踪洪水、野火、城市扩张和基础设施损毁。随着数千颗卫星进入轨道和蓬勃发展的航拍影像市场,数据量增长速度已超过人工检视的能力,推动了对更准确、更高效自动分类方法的需求。
融合两种机器视觉学习方式
当今大多数成功的图像识别系统依赖深度学习。一类网络——卷积神经网络(CNN)——擅长捕捉局部模式,如边缘、纹理和小形状。另一类较新的方法称为视觉变换器(vision transformer),它将图像视为一系列补丁,尤其擅长捕捉长距离关系,例如道路、屋顶簇和附近空地在场景中的相互关系。本工作将两者结合:使用一个著名的卷积模型 ResNet-50 与一个视觉变换器。两者分别处理相同的航拍图像并提取各自的数值特征——对网络所学场景信息的紧凑总结。然后把这两路信息合并,并传入一个“注意力”模块,该模块学习哪些特征在十个目标类别的判别中最为重要。
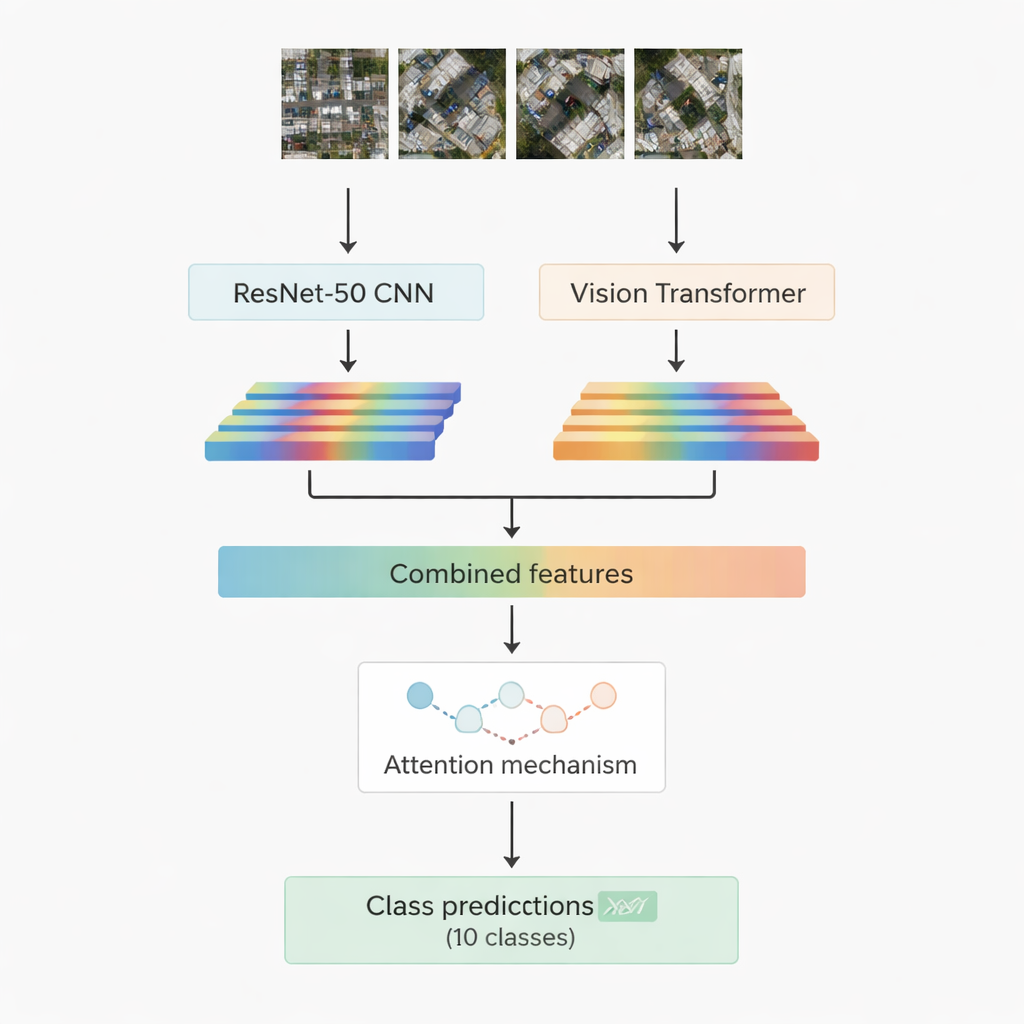
两种注意力策略以聚焦关键信息
研究人员设计并测试了混合系统的两个版本。在第一种中,他们简单地将 ResNet-50 与变换器的特征拼接,并将它们输入到多头注意力模块。可以把该机制想象成许多小聚光灯,每个从略微不同的角度查看特征,然后合并它们的发现。在第二种版本中,他们使用交叉注意力:卷积网络的特征充当查询(query),向变换器特征询问应关注的位置,使一路引导另一路。在两种情况下,注意力输出都经过常规层,最终将图像补丁分配到十个类别之一,包括建筑、汽车、碎片、人行小径、金属道路、空地、阴影、坦克、树木和屋顶。
在真实无人机图像上的测试
为评估模型性能,作者使用了来自印度锡金邦的公开数据集,该数据由无人机在距地面60至120米处拍摄。数据覆盖河流、森林、山丘和建成区,切成小补丁,使每张图像属于十个类别之一。该数据集是平衡的,每个类别在训练和测试集中图像数量相等,构成了公平的测试平台。研究人员在相同条件下训练两种混合模型,然后使用常用度量指标比较它们的表现:准确率、精确率、召回率、F1 值、混淆矩阵和 ROC 曲线。他们还将结果与若干知名网络和近期文献中的基于变换器的新方法进行基准比较。

更精准的分类与现实潜力
在该数据集上,两种混合模型均优于早期系统,总体准确率分别达到95.52%和95.80%,其中多头注意力版本略占上风。它们在十类对象上的表现保持强劲且稳定,详细分析显示即使是较弱的类别也能被较高的识别率覆盖。这表明将卷积网络、视觉变换器与注意力机制混合,是理解复杂航拍场景的有效方案。对普通读者而言,结论是:计算机在回答诸如“哪里是道路?”或“哪些补丁显示碎片或建筑?”这类问题上变得更准确。随着这类模型在更多数据集上的改进与推广,它们有望支撑更智能的灾害响应、环境监测和依赖快速可靠上方图像解读的智慧城市服务。
引用: Aboghanem, A., Abd Elfattah, M., M. Amer, H. et al. A hybrid ResNet50-vision transformer model with an attention mechanism for aerial image classification. Sci Rep 16, 5940 (2026). https://doi.org/10.1038/s41598-026-36492-4
关键词: 航拍图像分类, 无人机影像, 深度学习, 视觉变换器, 遥感