Clear Sky Science · zh
基于优化注意力级联洗牌长时依赖网络的自适应电子学习在IT专业人员中的性能分析
为在职技术人员提供更智能的在线培训
对于许多信息技术(IT)专业人员来说,在线课程如今是保持技能更新的主要途径。但大多数培训平台仍然用像测验总分或完成徽章这样粗糙的工具来评估学员。本研究提出了一种更智能的方法,读取学习者留下的数字“足迹”,并将其转化为关于每个人真实学习情况的精确、实时洞见。
为何一刀切的在线课程难以满足需求
传统的电子学习把大多数学习者视为同类:每个人看到相同的模块,做相同的测验,并用相同的固定测试来评价。这种方法忽视了专业人员尤其在像网络安全或云计算等快速变化领域中进步的巨大差异。早期研究尝试用机器学习来解决这个问题——结合测验分数、花费时间和点击数据来预测成功——但许多模型在面对噪声或不完整数据时表现不佳,无法扩展到实际平台,或不能追踪数周乃至数月内学习如何展开。结果往往是延迟且粗糙的反馈,难以用于个性化内容或及时干预。
将原始课程日志转成干净且公平的数据
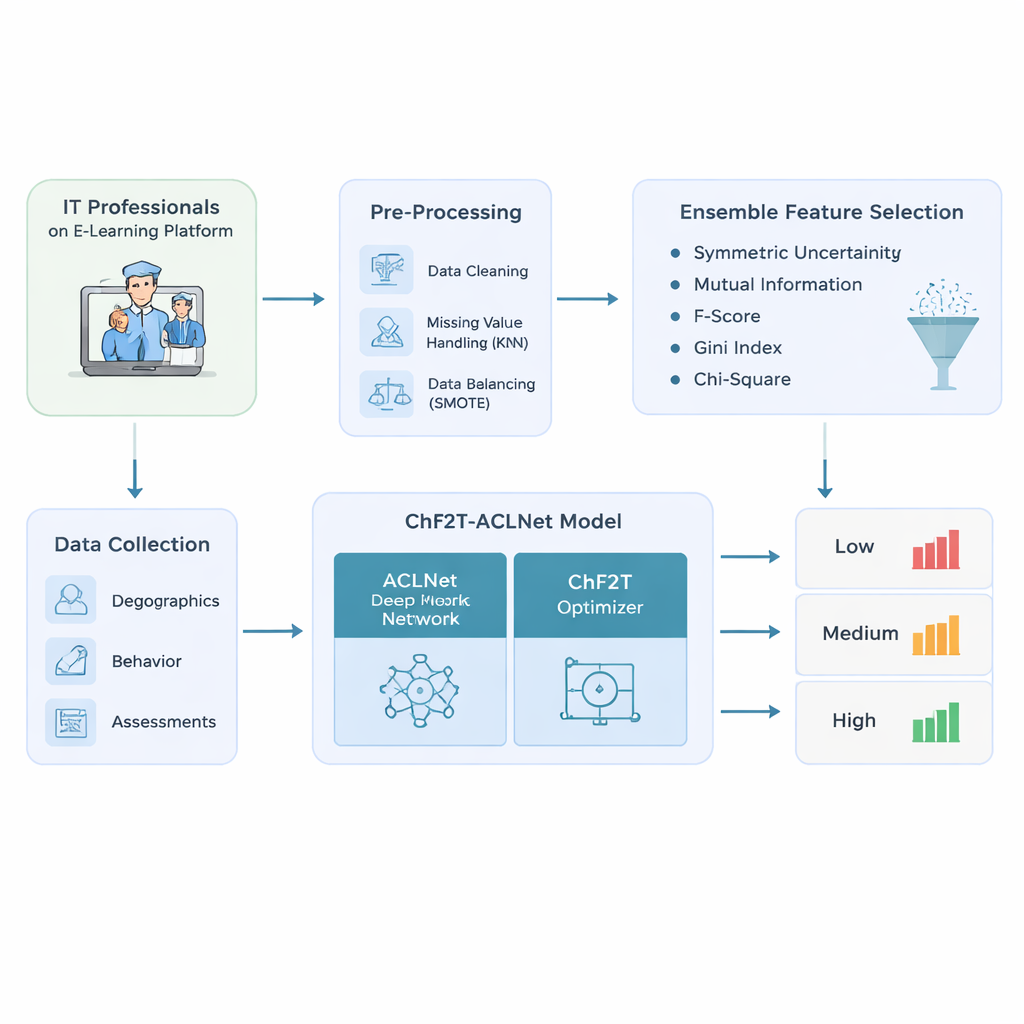
作者首先为使用自适应电子学习平台的IT专业人员设计了一个严谨的数据管道。他们收集了丰富的信息:诸如年龄和职位等基本档案;诸如花费时间、访问日期和活跃天数等行为痕迹;以及包括测验分数、尝试次数、证书和反馈评分在内的表现指标。在进行任何建模之前,他们对数据进行清洗——删除重复记录,通过参考相似学习者来估算缺失值,并纠正偏斜的类别分布,以便低、中、高表现者能够更公平地被代表。这一步的平衡处理避免了模型仅对最常见的“平均”学习者过于自信,而对挣扎或表现突出的个体视而不见。
只选择最具信息量的信号
在清洗后的数据集中,系统并不把每一列数据都丢进黑箱模型。相反,它使用五种简单排序方法的集成来决定哪些特征对预测学习结果真正重要。每种方法都会检查候选特征(例如测验尝试次数或花费时间)与最终表现标签之间的关联。通过使用中位得分合并这些排名,该方法过滤掉噪声或冗余信号,仅保留最具信息量的特征。这不仅减少了后续模型所需的计算量,还帮助模型聚焦于能实质区分低、中、高成就者的模式。
像团队一样训练的混合网络
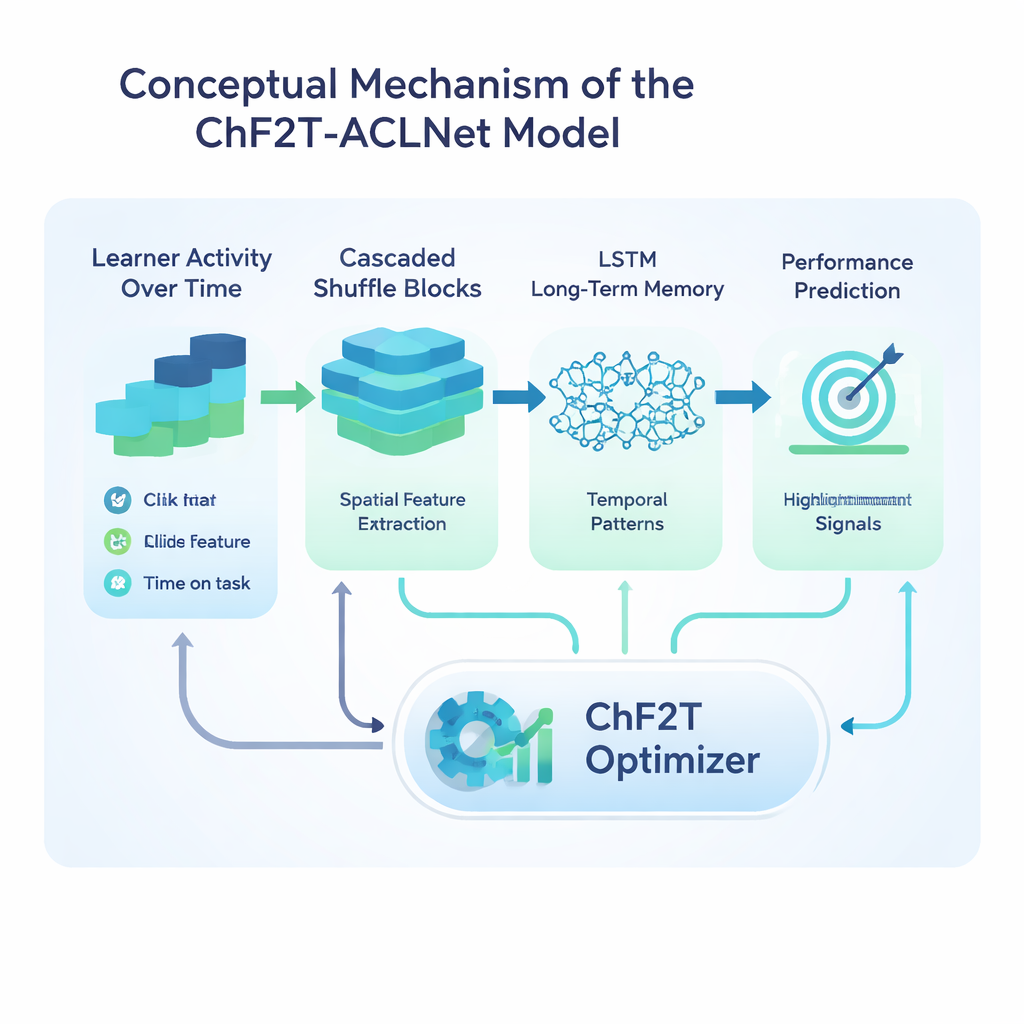
研究的核心是一种名为ACLNet的混合深度学习模型,配以一种受团队体育启发的非常规训练策略。ACLNet首先使用轻量级的“洗牌”模块来高效地压缩和混合输入信号,然后将其传入一个记忆模块以追踪学习者行为随时间的变化。最上层的注意力层突出最具影响力的通道——例如活动突然下降或持续较高的测验分数——然后给出学习者表现等级的最终预测。为了调整该网络的众多内部参数,作者提出了一种混沌足球队训练(ChF2T)算法。在这里,虚拟“队员”探索不同的参数设定,模仿表现强劲的设置,避开弱的设置,并偶尔做出大的混沌跳跃,帮助搜索跳出糟糕的局部选择。这种结构与受控随机性的结合加速了收敛并减少了过拟合。
系统在实践中的表现如何
研究人员在一个合成但现实的1200名IT专业人员数据集上测试了他们的管道,该数据集仿真了真实学习管理系统记录并故意包含不均衡的类别分布。他们将ChF2T‑ACLNet模型与若干强基线方法进行了比较,包括联邦学习设置、为教育改造的先进图像类网络及其他深度或集成模型。在多次交叉验证设置中,该方法达到约98.9%的准确率,并具有同样较高的精确率、召回率和F分数。它还取得了接近完美的经校正一致性分数并提供强劲的曲线下面积值,意味着它在多个阈值下可靠地区分表现等级。尽管结构复杂,该系统运行速度却优于竞争方法,这得益于谨慎的特征选择、高效的网络设计以及优化器的快速收敛。
这对日常在线学习意味着什么
简而言之,这项工作表明可以观察专业人员在在线课程中的行为,并高置信度地推断出谁在挣扎、谁在走过场、谁在掌握内容——而无需等到期末考试。这样的系统可以触发早期提示、推荐不同的练习,或在学习者落后很久之前提醒导师。作者也指出了仍需解决的挑战,包括扩展到非常大的平台、适应快速变化的课程设计以及让模型决策更易解释。尽管如此,他们的方法仍是朝着让电子学习系统更像有关注的个人教练而非静态数字教材迈出的重要一步。
引用: Yuvapriya, P., Subramanian, P. & Surendran, R. Optimized attention-based cascaded shuffle long-term dependent network based performance analysis of adaptive e-learning among IT professionals. Sci Rep 16, 6245 (2026). https://doi.org/10.1038/s41598-026-36470-w
关键词: 自适应电子学习, 学习分析, 深度学习, IT专业人员培训, 学生成绩预测