Clear Sky Science · zh
用于金属表面缺陷语义分割的跨任务少样本自适应记忆
为工厂车间配备更聪明的“眼睛”
现代工厂依赖摄像头在金属零件到达客户之前就发现细小的划痕、坑洼和污渍。但要让计算机识别各种可能的缺陷,通常需要大量且精心标注的图像集,而许多工厂并不具备这种资源。本文提出了一种新的训练方法,能够仅从少量示例中学习,使高精度的自动化质量检测更实用且更经济。
为什么少量示例就足够
传统的缺陷检测系统在见过每类缺陷数千张带标注图像时效果最佳。然而在实际生产中,稀有缺陷可能只出现几次,而且对图像进行像素级标注既耗时又昂贵。这里研究的方法属于“少样本语义分割”领域。在这种设置下,系统只给出少量带标注的“支持”图像,展示某一特定缺陷,然后必须在新的“查询”图像中标出相同类型的缺陷。金属表面尤其具有挑战性,因为光照、纹理和背景模式很容易使在有限数据上训练的模型混淆。
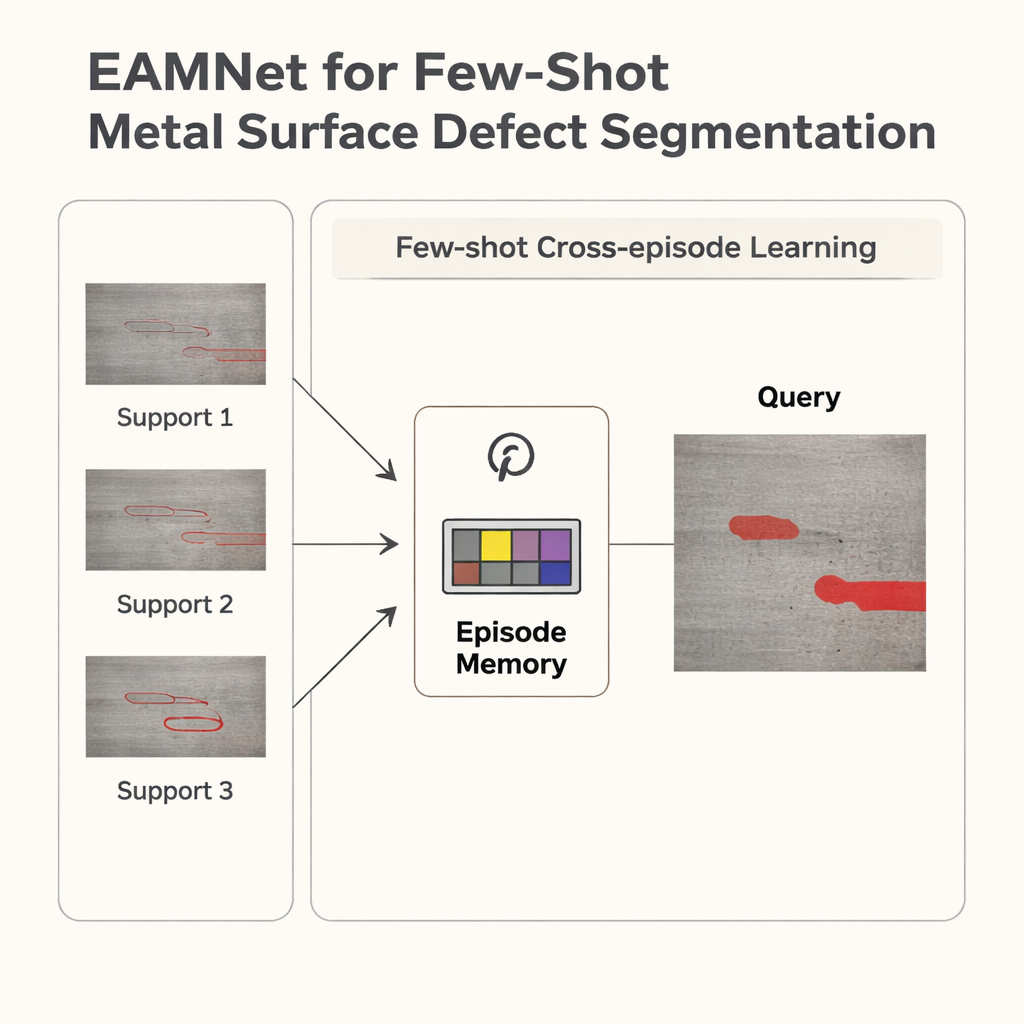
跨任务学习,而不仅仅是单任务内
大多数早期的少样本方法将每个学习任务或“情节”孤立对待:它们查看一个缺陷类型的支持和查询图像,给出预测,然后继续下一个任务。因此,这些方法往往依赖亮度或局部纹理等表面线索,而非对缺陷更具通用性和可复用的深层描述。作者提出了一种情节自适应记忆网络(Episode Adaptive Memory Network, EAMNet),它正好相反:它会记忆。一个专门的记忆单元跟踪支持图像与查询图像在多个情节间的关系,提炼出跨任务的“自适应因子”,引导模型朝向更一般且稳定的缺陷区域描述,而不是对单一任务过拟合。
关注细节
除了这种跨情节记忆,EAMNet 还包含增强对每个情节内部细微差别感知的模块。上下文自适应模块比较支持与查询图像的深层特征,以捕捉缺陷像素在外观和周围环境上与干净金属的差异。第二个组件称为全局响应掩码平均池化,它改进了系统对支持缺陷示例的汇总方式,使该汇总对强而可靠的信号更加敏感,而对噪声背景不那么受影响。组合起来,这些部分帮助网络刻画精确的缺陷形状,而不是粗糙的斑块,即便缺陷很小或与周围融为一体。
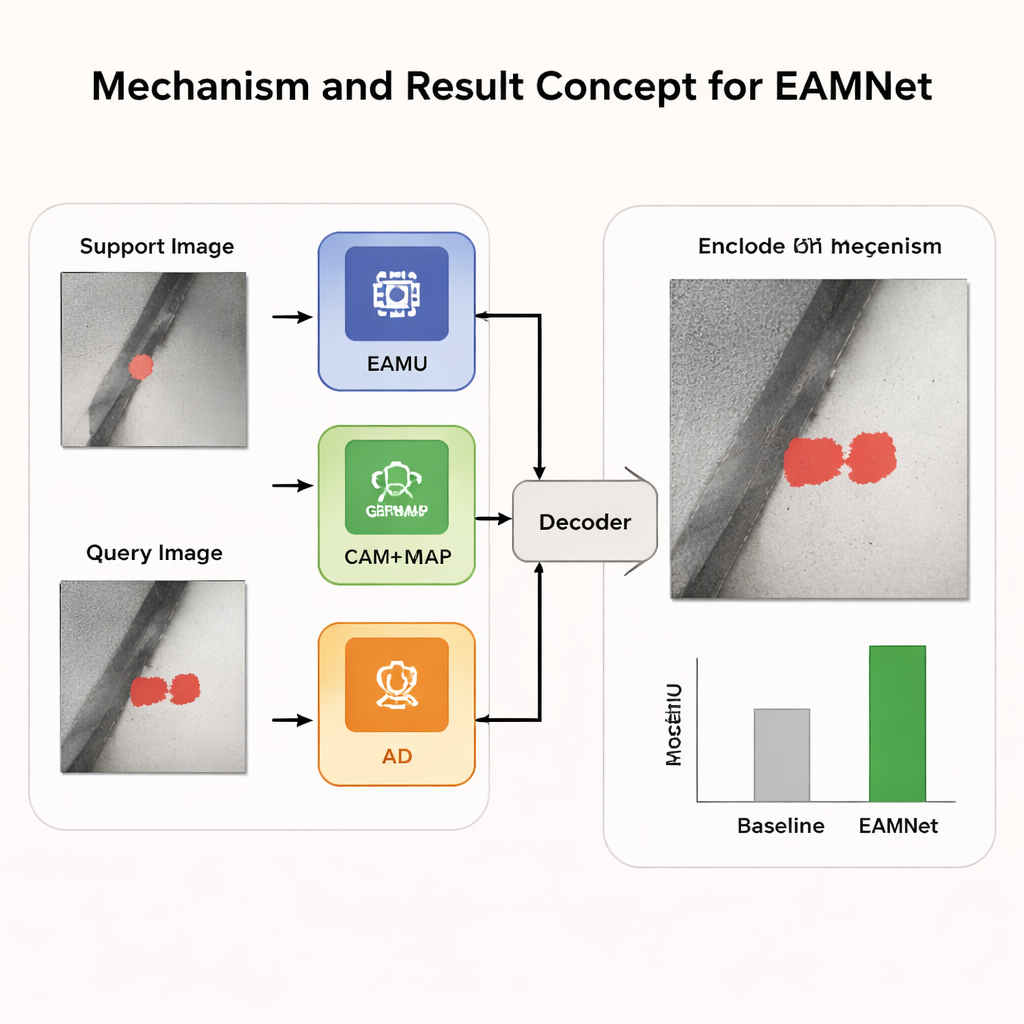
教会网络更好地关注关键区域
从零训练这样的网络可能不稳定,因为在数据稀缺时,前层往往会产生模糊、质量较低的特征。为了解决这一问题,作者在训练过程中引入了“注意力蒸馏”步骤。简言之,注意力更集中、层次更高的注意力图被用作对网络低层的软教学信号。这鼓励整个系统在重要区域上达成一致,加快学习速度,并提升其在测试时无需额外微调就能适应新缺陷类型的能力。
这些结果对工业意味着什么
研究者在两个金属表面缺陷基准数据集——一个通用数据集和一个聚焦于带钢的数据集——上测试了 EAMNet,并与若干领先方法进行了比较。在两套数据集和不同网络主干上,他们的模型始终实现了更高的准确率,常常在强基线之上将标准质量指标提高十个百分点以上。对非专业读者而言,这意味着基于摄像头的检测系统可以仅从少量带标注样本快速学习新的缺陷类型,同时仍能以细粒度标出缺陷区域。实际上,这样的系统可以减少人工检测,更早发现细微缺陷,并在标注数据稀缺的情况下让先进质量控制更易获取。
引用: Zhang, J., Ding, H., Peng, M. et al. Few-shot cross-episode adaptive memory for metal surface defect semantic segmentation. Sci Rep 16, 5660 (2026). https://doi.org/10.1038/s41598-026-36445-x
关键词: 金属表面缺陷, 少样本学习, 语义分割, 工业检测, 计算机视觉