Clear Sky Science · zh
使用联邦平均算法的多模型联邦学习框架进行隐私感知的深静脉血栓分割
为什么血栓和数据隐私很重要
在腿部深静脉形成的血栓,称为深静脉血栓(DVT),可能在无声无息中游走到肺部并引发危及生命的急症。CT 扫描可以显示这些血栓,但将成千上万张灰度图像转化为可靠的自动检测对计算机来说是项艰巨任务。与此同时,医院对共享敏感患者数据持谨慎态度也是理所当然的。本研究探讨了如何让多家医院在不合并或暴露原始患者扫描的情况下,共同训练一个强大的识别血栓的人工智能(AI)系统。
共享“脑力”,不共享“身体”
工作的核心是一种称为联邦学习的技术,它允许多个机构在保留本地数据的同时协作训练 AI 模型。各医院不是将 CT 图像发送到中央服务器,而是在本地用自己的扫描数据训练模型。只有模型学到的参数——本质上是它在识别血栓方面“学到的东西”——会被发送到中央服务器。在那里,一种称为联邦平均的方法将这些不同的参数集合并成一个改进的全局模型,然后再回传给所有医院。通过这种方式,每个站点都能受益于所有参与者的集体经验,而没有任何患者图像离开其所在机构。 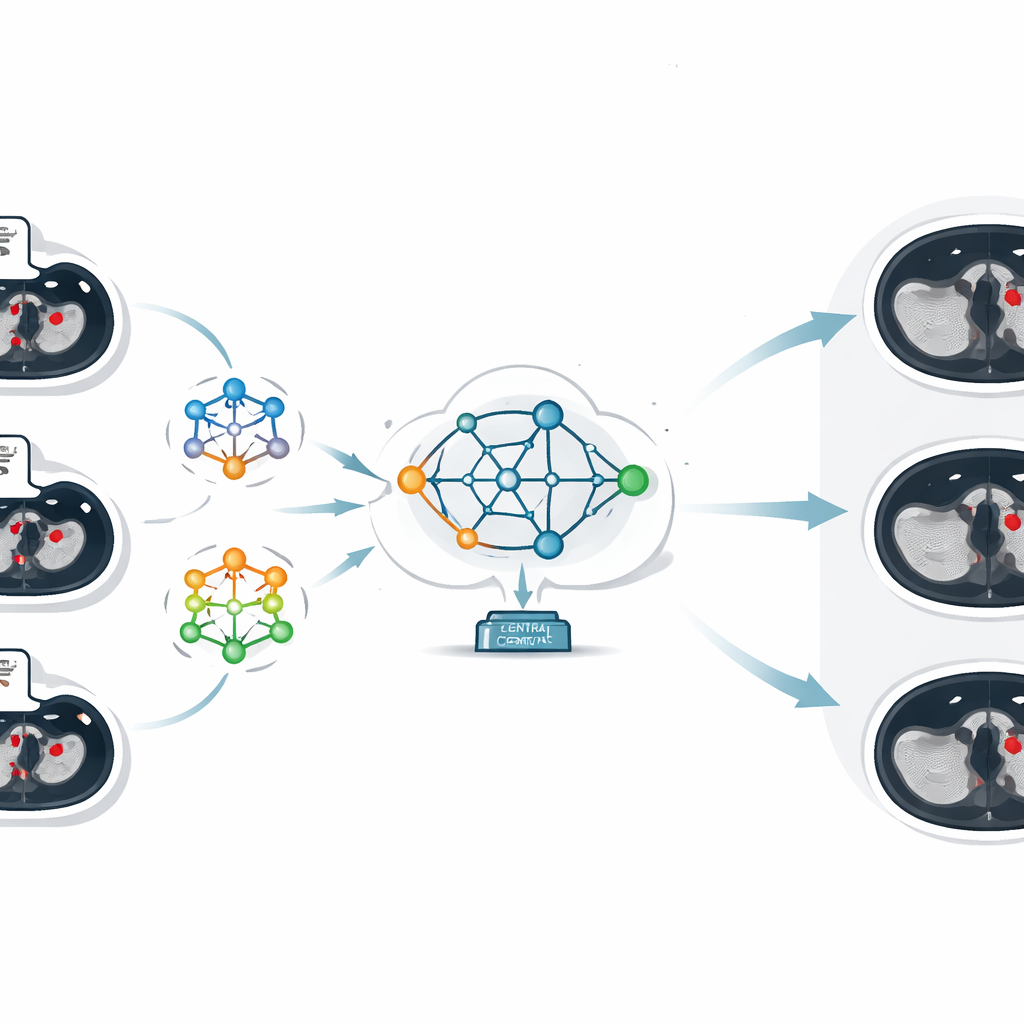
多种风格的 AI 共同观察同一静脉
本研究的一项关键创新是研究者没有只依赖单一类型的神经网络。他们组合了七种不同的模型设计,每种模型擅长捕捉 CT 图像的不同特征。较简单的模型,比如基础卷积网络和序列模型,在受限硬件上运行更快、更容易部署。更先进的架构,包括 U‑Net、VGG‑19 以及两个带有残差、Inception、注意力和多尺度处理模块的定制网络,更善于勾勒细小血管边界、发现微小血栓并应对噪声图像。通过允许每家医院使用最适合其数据和计算能力的模型,该系统反映了现实临床环境的多样性,而不是假设每个站点都相同。
从不均匀和不完美的数据中学习
在医疗领域,一家医院的数据很少会与另一家完全相同。扫描仪、成像协议和患者群体各不相同,因此研究有意使用“非独立同分布(non‑IID)”数据——即不均匀且分布不同的数据集。这通常会使训练更不稳定。在此,作者接受了这种多样性,并表明跨多个、结构不同的模型汇聚知识实际上提高了全局系统的泛化能力。他们进行了三阶段实验,先是三名客户端,然后五名,最后七名,分别使用 1,000、2,000 和 3,000 张 CT 图像的数据集。在每一步,他们不仅跟踪全局模型正确分割血栓的频率,还记录了所需通信量、训练耗时、各客户端数据的差异程度以及隐私保护的效果。
更好的血栓检测,但付出计算代价
在所有阶段中,组合后的全局模型始终优于任何单一的本地模型。随着图像数量的增加和更复杂模型加入联邦学习,分割准确率从约 91% 提升到超过 96%,而称为 F1 分数的平衡质量指标从大约 0.89 上升到 0.95。与此同时,一个以错误为重点的损失度量下降了一半以上,表明血栓轮廓更清晰、更可靠。这些改进并非免费:客户端与服务器之间的通信从几十兆字节增加到数吉字节,平均训练时间也从几秒增长到数小时,随着架构复杂度提升而显著增加。尽管如此,系统仍维持了较强的形式化隐私保证,表明共享的更新泄露关于任一单个患者的信息非常有限。 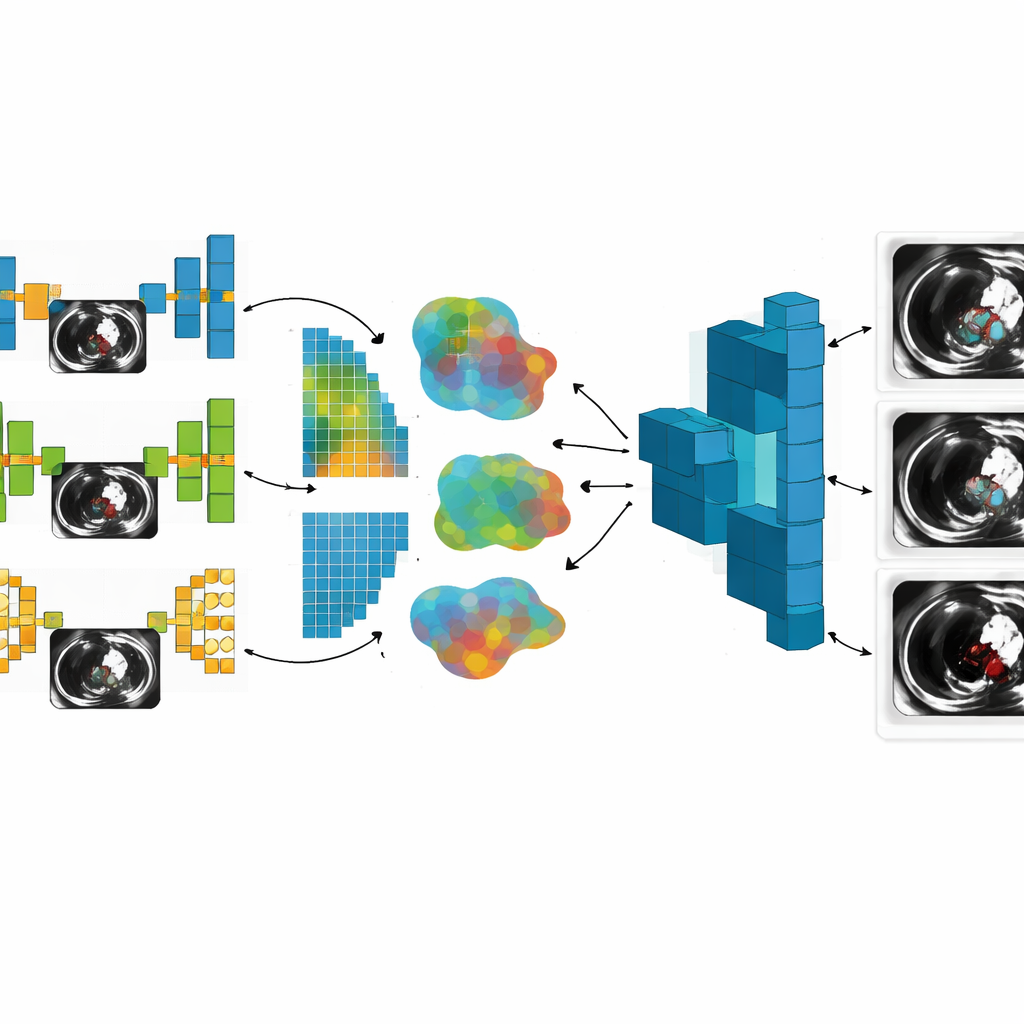
这对患者和医院意味着什么
对非专业读者而言,结论是这项工作展示了医院如何在不放弃对敏感数据控制权的前提下,共同训练出更准确识别危险血栓的共享 AI。通过融合多种互补的模型设计并谨慎地聚合各自学到的内容,作者构建了一个既强大又尊重隐私的血栓分割系统。尽管该方法需要大量计算资源和网络带宽,但它指向了一个未来:医疗中心常规合作开发更智能的诊断工具,改善 DVT 及相关疾病高风险患者的护理,同时将个人检查影像安全地保留在机构内部。
引用: B, P.L., S, V. Privacy-aware deep vein thrombosis segmentation using a multi-model federated learning framework with the federated averaging algorithm. Sci Rep 16, 11333 (2026). https://doi.org/10.1038/s41598-026-36432-2
关键词: 深静脉血栓, 联邦学习, 医学图像分割, 隐私保护的人工智能, CT 成像