Clear Sky Science · zh
一种基于BERT模型和最短路径算法的短文本实体消歧方法
为混淆的名称理清含义为何重要
我们每天在搜索、浏览和聊天时使用的是简短且常常混乱的文本片段——推文、搜索查询、聊天消息等。这些片段充斥着人名、地名、公司名和事物名称,它们可能具有多重含义,例如“Apple”既可以指水果,也可以指公司。计算机必须猜测我们意指哪一种含义,当猜错时,搜索结果、推荐和在线服务的效果就会大打折扣。本文提出了一种新方法,通过将现代语言模型与巧妙的图算法结合,帮助机器在短文本中正确解释这些模糊名称,特别针对中文社交媒体和搜索场景。
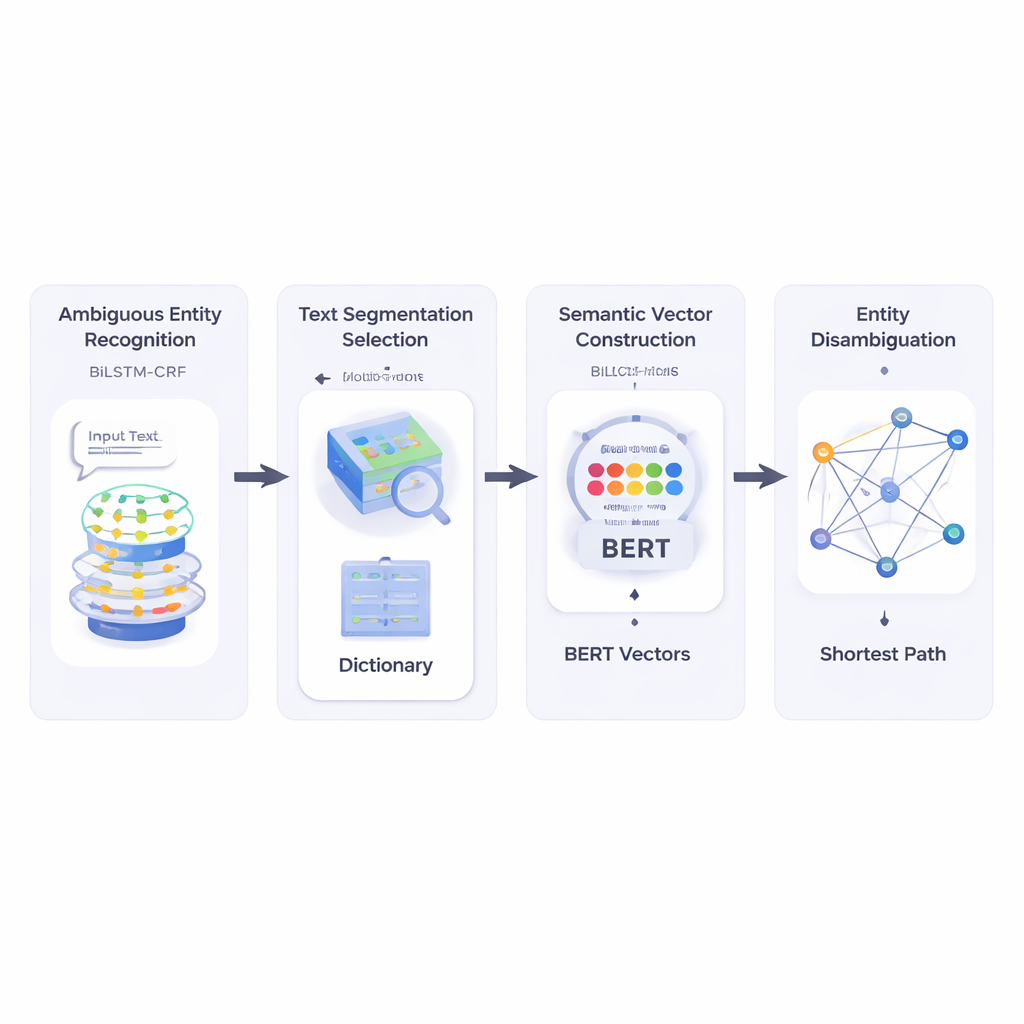
从混乱的短文本到清晰的目标
短文本对计算机来说出奇地难懂。与长篇文章不同,短文本上下文信息非常有限,并且充斥着俚语、缩写和不完整句子。传统方法尝试把文本中的名称匹配到知识库条目,或使用人工规则和较简单的机器学习模型。这些方法常常假设每个词都有一个固定含义,这在同一词根据使用场景可能表示职务、公司或歌曲时会严重失效。结果就是,经常无法确定推文或查询中的一个词究竟指代哪个真实世界实体。
教系统识别可混淆的名称
作者首先构建了一个系统,读取短文本并识别哪些片段是实体名称以及其中哪些可能存在歧义。他们使用了一种称为BiLSTM‑CRF的神经网络组合,它通过同时查看左右上下文,擅长对词序列进行标注。一旦标注出潜在实体,系统就查询一个大型词汇资源HowNet。如果HowNet为某词列出了多个含义,则将该词标记为歧义;如果只有一个含义,则视为已明确。这一步为系统提供了一份需要真正消歧的名称清单,从而聚焦后续处理。
将含义转化为空间中的点
接着,方法将短文本切分为候选词片段,并通过检查每种可能切分与句中已明确参考词在语义上的契合程度来选择最佳分词。为此,作者依赖BERT这一强大的预训练语言模型,它能为每个词的用法生成数值化的“语义向量”,捕捉其上下文相关的含义。通过计算这些向量间的余弦相似度,系统找到那些片段与无歧义参考词在语义上最兼容的切分。这使得模型能够把每个词的每种可能含义表示为多维空间中的一个点。
寻找通往正确含义的最短路径
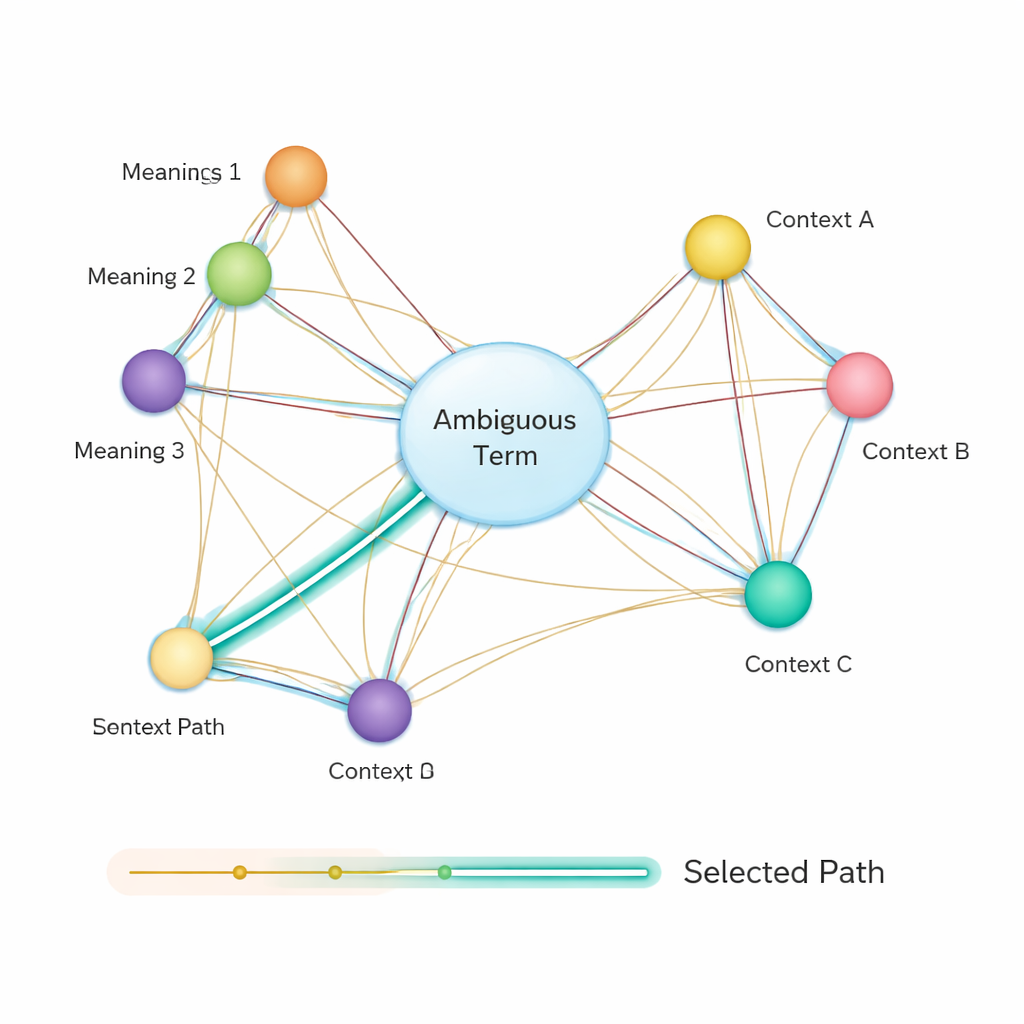
之后,方法构建了一个语义网络:在该图中,每个术语的每种可能含义是一个节点,边将可能在同一句话中共现的含义连接起来。每条边的权重基于含义间的相似度,同样使用BERT向量来衡量。为决定某个歧义词在句中最合适的意义,作者应用了经典的Dijkstra最短路径算法。直观上,系统寻找通过该含义图使整体语义“距离”最小的路径。所选路径对应对所有术语的一致解释,位于该路径上的歧义实体的含义即被选作最终答案。
效果提升有多大?
研究人员在来自CLUE基准的公开中文数据集上测试了他们的方法,该数据集模拟了社交媒体帖子和查询等真实短文本场景。他们比较了四种方法:使用传统Word2Vec嵌入的版本、ELMo语言模型、没有最短路径步骤的BERT系统,以及他们完整的BiLSTM‑CRF‑BERT‑SPA流程。在数千条文本上,他们的完整方法在准确率、召回率和F1值上平均比其他方法提高了大约四分之一。就实际应用而言,该系统不仅更善于识别正确实体,而且在不同数据规模下也表现得更为稳定。
这对日常技术意味着什么
对非专业读者而言,结论很直接:通过将强大的语言理解模型(BERT)与基于图的最短路径搜索相结合,作者为计算机在短而嘈杂的文本中判断模糊名称的真实指向提供了更可靠的方式。这可以使搜索引擎更智能、帮助社交平台更好地理解帖文,并改进推荐系统与知识图谱等下游工具。尽管该方法目前更偏向中文场景且在效率上仍有改进空间,但它展示了现代人工智能与经典算法结合时如何显著减少机器理解日常语言时的混淆。
引用: Liu, X., Zhang, D., Xiao, T. et al. A short text entity disambiguation method based on BERT model and shortest path algorithm. Sci Rep 16, 5720 (2026). https://doi.org/10.1038/s41598-026-36411-7
关键词: 实体消歧, 短文本, BERT, 知识图谱, 自然语言处理