Clear Sky Science · zh
使用多臂强盗方法的计算机自适应测试的强化学习框架
面向数字课堂的更智能测试
任何经历过冗长、千篇一律考试的人都知道这种体验既枯燥又可能不公平。有些题目过于简单,有些题目难到无法完成,最终得分未必真正反映你的能力。本文提出了一种新的构建计算机化测试的方法,能够根据每位考生的回答实时自适应。作者借鉴现代人工智能的思想,力求使考试更短、更准确,并更好地匹配每个考生的真实能力。
固定试卷为何不足
传统考试给每位学生出一套相同的题目,这使得试卷编制变得简单,但也浪费了信息:水平较高的学生要耗费大量时间做很容易的题,而困难的学生则很快被难题压垮。计算机自适应测试试图通过根据先前答案选择下一题来改进这一点,但大多数现有系统仍依赖几十年前的统计模型和人工设计规则。这些旧方法难以捕捉复杂的答题模式,且在现代大规模在线环境中往往无法充分考虑学习者之间的广泛差异。
将现代人工智能引入测评
作者提出了一个将深度学习与强化学习结合的全新框架,从头到尾驱动自适应测验。系统以循环的方式运行。首先,一个一维卷积神经网络(1D‑CNN)分析考生的最近答题记录、题目难度及其他汇总统计量。从这些数据流中网络产生一个单一数值,表示考生在归一化刻度上的当前能力,这类似于传统测验理论中对能力的描述,但这里是直接从数据中学习得到的。该网络被训练以识别细微模式,例如在较难题上持续成功或在较易题上出现意外失误的情况。 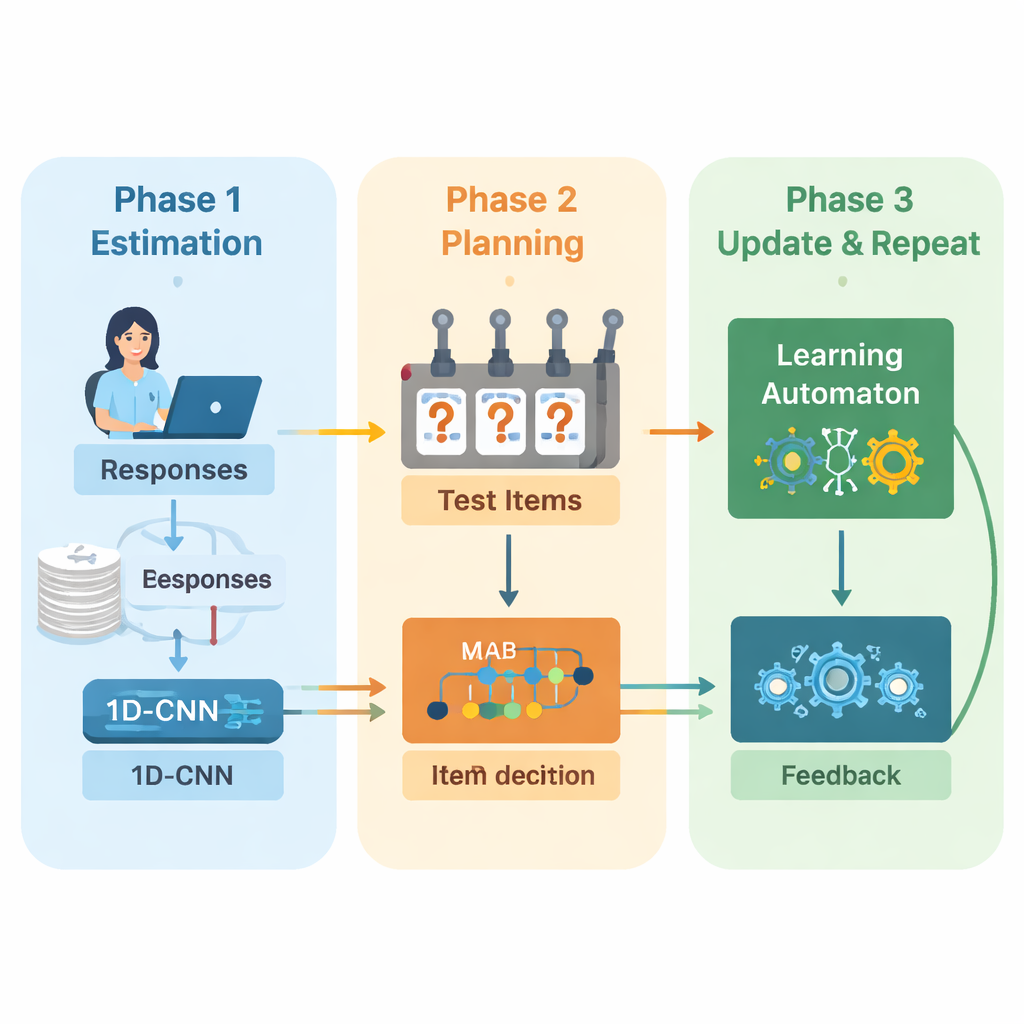
如何选择下一题
在系统更新了能力估计后,就要决定接下来出什么题。作者在此使用“多臂强盗”策略,这是一种来自决策理论的经典工具,将每个可能的动作视作老虎机上的拉杆。在本情景中,题库中的每道题就是一只臂。算法会查看与当前能力估计大致匹配的题目,然后选择那些预计最能提供信息的题目。它在两项目标之间权衡:使题目难度与能力相匹配,避免题目过易或过难;同时覆盖尽可能多的内容领域,避免测试忽视重要主题。将这两个目标混合的奖励分数指导着题目的选择过程。
从自身决策中学习
为了在测试进行过程中持续改进,系统加入了另一个学习组件,称为学习自动机。该模块监控估计能力在各轮之间的变化,以及考生的答题准确率是提升还是下降。它调整一组小概率值,总结模型预期能力是上升、保持不变还是下降。这些概率随后作为额外输入反馈给下一轮的神经网络。通过这种方式,测试引擎不仅学习关于学生的信息,也学习关于自身过去决策的信息——奖励那些导致准确估计的趋势,惩罚那些没有的趋势。 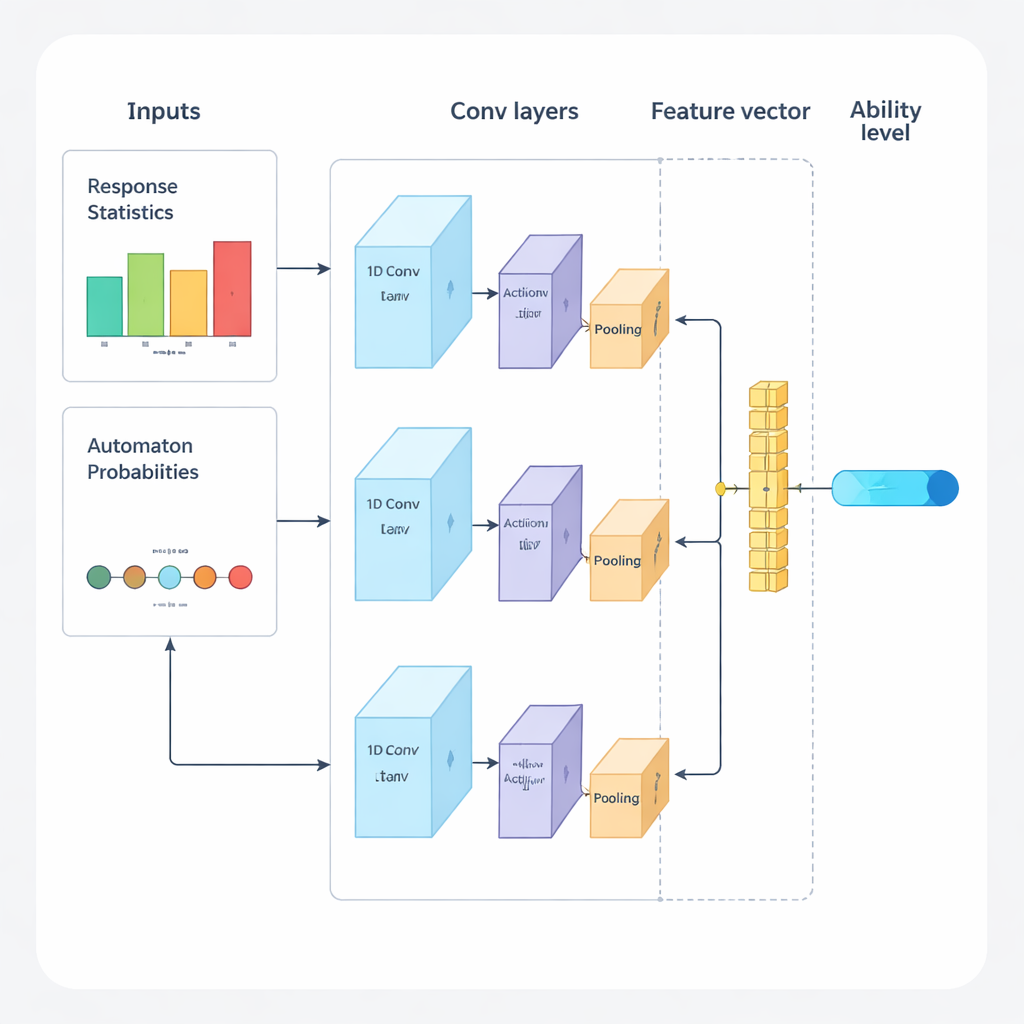
实际效果如何?
研究者使用一个大型多语言考试数据集和数千名真实能力已知的模拟考生评估了他们的框架。他们将该方法与若干领先的自适应测验方法进行了比较。在一系列误差和相关性指标上,新系统在需要更少题目的情况下也能产生更准确的能力估计。其误差——以均方根误差和平均绝对误差等常见统计量衡量——明显低于对比方法。同时,它在题库中的题目使用上分布更为均匀,降低了某些题目被过度暴露和泄露的风险。
对未来考试的意义
通俗地说,这项工作表明未来的计算机化测试可能更像量身定制的辅导课程,而不是僵化的考试。题目会迅速锁定每个人合适的难度,覆盖所有重要话题,并在系统对你的水平有足够信心时结束——通常比现在的测试所需题目更少。尽管该方法仍依赖良好的训练数据和计算能力,目前仅在单一数据集上进行了试验,但它指向了一代更智能、更公平且更高效的评估方式,这些评估能自然地适应个体学习者。
引用: Tang, B., Li, S. & Zhao, C. Reinforcement learning framework for computerized adaptive testing using multi armed bandit approach. Sci Rep 16, 7441 (2026). https://doi.org/10.1038/s41598-026-36394-5
关键词: 计算机自适应测试, 教育评估, 深度学习, 强化学习, 多臂强盗