Clear Sky Science · zh
基于多智能体强化学习算法的认知物联网资源分配方法
为什么你的汽车数据需要保持“新鲜”
现代汽车不断与其他车辆和路侧设备共享位置、速度及周围环境等信息。为了让安全功能和未来的自动驾驶能力可靠工作,这些信息不仅要准确,还必须是新鲜的:延迟一秒钟的刹车警报可能就毫无用处。本文探讨如何在繁忙的无线网络上尽可能保持此类数据的及时性,采用一种新的基于学习的控制方法,让车辆能够自主决定何时以及如何传输数据。
共享空中频谱的智能道路
这项研究关注一种未来路网场景,其中成千上万辆联网汽车与移动用户等现有用户共享有限的无线频谱。该设置称为认知物联网,假设车辆是“礼貌的客人”:只有在不干扰主用户的情况下它们才能借用频率。同时,车辆必须彼此以及与基站快速通信,以支持碰撞警报、交通协调和娱乐服务。平衡这些需求很困难,因为车辆移动快速,信号在穿行城市街区时会衰落,可用信道也会随时变化。
衡量的是新鲜度,而不仅仅是速率
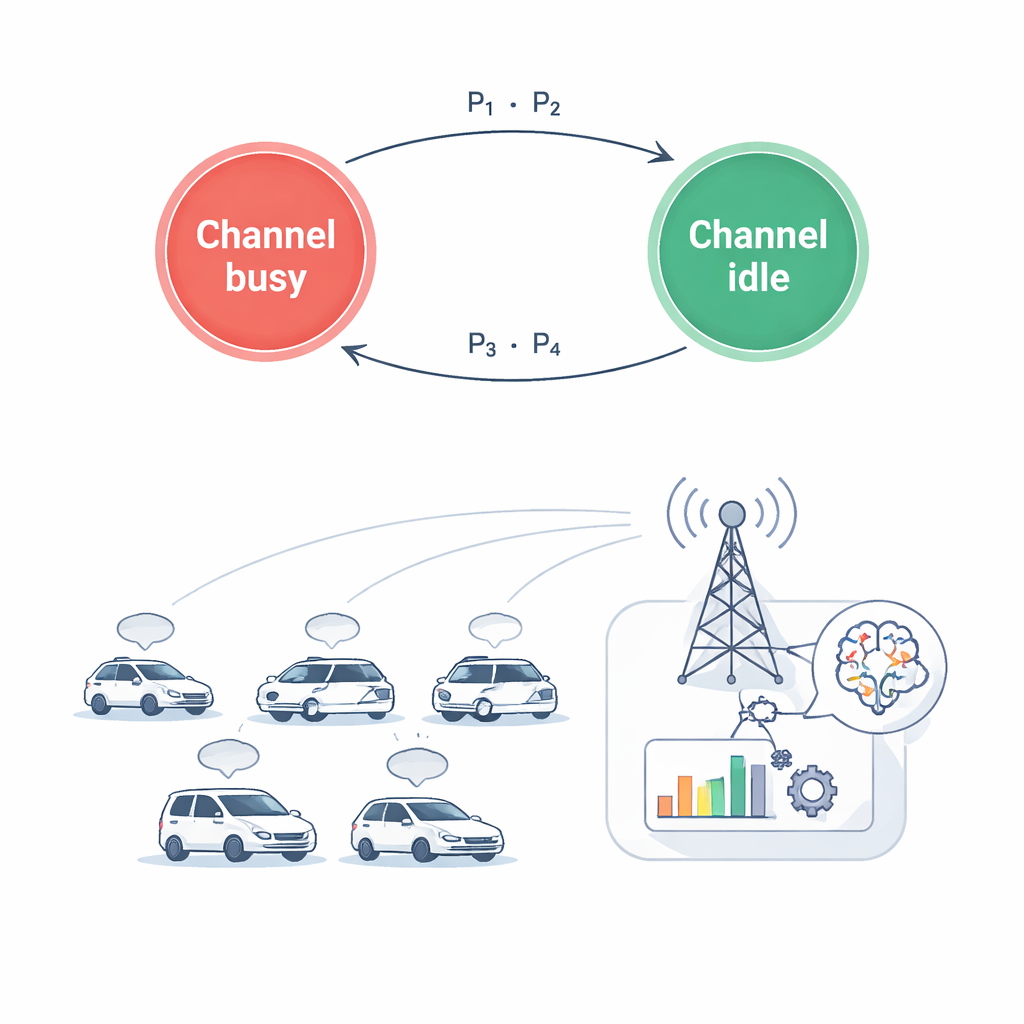
传统网络设计通常侧重于提高数据速率或降低平均延迟。然而,对于安全关键的车载消息而言,真正重要的是当最近一次状态更新到达接收端时它有多新。作者采用了一个称为信息时效性(Age of Information,AoI)的度量:自上次成功更新以来随时间增长,到达新消息时重置。在他们的模型中,每对车辆反复发送数据块。如果无线链路良好且所选发射功率足够高,当前数据块能被快速清除,时效性下降;若连接差或功率受限,剩余数据会被留到下一次,时效性持续上升。目标是在尽量保持时效性低的同时,节省能量并保护主用户免受干扰,从而选择合适的无线信道和发射功率。
通过试错教会车辆协作
由于无线环境变化迅速且每辆车只能观测到局部信息,作者将问题表述为一个学习任务而非固定公式。每辆车作为智能体反复观测其所处情况:哪些信道看起来忙碌、无线链路强度如何、还剩多少数据待发、上次更新的时效性是多少。基于这一部分可见的信息,它选择一个动作,该动作包括离散选择(使用哪个信道,或选择静默)和连续选择(使用多少发射功率)。行动后,系统评估信息的新鲜度、使用的功率以及是否干扰了主用户。该反馈被转化为奖励信号,引导智能体在大量仿真回合中逐步学习更好的联合决策。
为混合决策量身定制的学习算法
为训练这些智能体,作者开发了一种改进的多智能体近端策略优化(Proximal Policy Optimization)方法。他们的变体 IMAPPO 使用一个中心化训练模块,该模块可以看到全局状态并评估所有车辆联合动作的质量,而每辆车则学习一个私有的决策规则,能够在实时中独立应用。一个关键创新是升级的决策网络,它能自然处理信道的开/关离散选择以及连续的功率范围。在对网格状城市道路的仿真中,车辆与基站放置在现实位置并考虑衰落与干扰等无线效应,所提出的方法与若干先进学习算法及随机基线进行了比较。
更鲜的新信息、更低的能耗
结果表明,新方法能在显著提高信息新鲜度的同时降低功耗。在不同车辆数量和不同待发数据量的场景下,与简单随机接入相比,IMAPPO 将平均信息时效性最多降低约一半,并且在有意义的范围内优于其他先进学习方法。同时,它也降低了车辆的总体功率消耗,有助于延长电池寿命并限制对其他频谱用户的干扰。对普通读者而言,这意味着在无线“道路”上更智能的基于学习的发言时机与发言强度控制,可能让联网和自动驾驶车辆更安全、更高效,并更善意地共享拥挤的无线空域。
引用: Wang, R., Shen, Y., Wang, D. et al. A cognitive internet of things resource allocation method based on multi-agent reinforcement learning algorithm. Sci Rep 16, 7756 (2026). https://doi.org/10.1038/s41598-026-36380-x
关键词: 网联汽车, 无线频谱共享, 信息时效性, 强化学习, 物联网