Clear Sky Science · zh
使用专家混合与多模型融合对大型游乐设施危险因素识别
为什么主题公园安全需要更“聪明”的阅读方式
每年都有数亿人登上过山车、自由落体塔和旋转类游乐设施,他们信任复杂的机器与繁忙的操作人员会保障安全。在幕后的监管者与工程师之间,会产生大量报告、事故记录与群众投诉——但大部分信息以难以快速筛查的文本形式存在。本研究探讨了先进的人工智能如何在大规模上“阅读”这些文档、更早发现危险模式,并为主管部门勾勒出游乐设施更可能出问题的清晰图景。
从零散报告到统一的风险画像
中国目前拥有超过25,000台大型游乐设备和每年逾7亿的游客量。尽管整体安全有所提升,但罕见但严重的事故仍会发生,往往在检验中未能发现埋藏于技术描述或用户投诉中的早期预警信号。作者认为,基于周期性人工检查、专家判断和维修日志的传统监督,对于如此快节奏的环境太慢且具有主观性。他们汇集了包括事故报告、法律法规与标准、检查与维护记录以及与游乐设施相关的网上投诉在内的大规模真实文本集合。经仔细清洗与过滤后,这一多源语料成为自动化、数据驱动风险监测系统的原料。 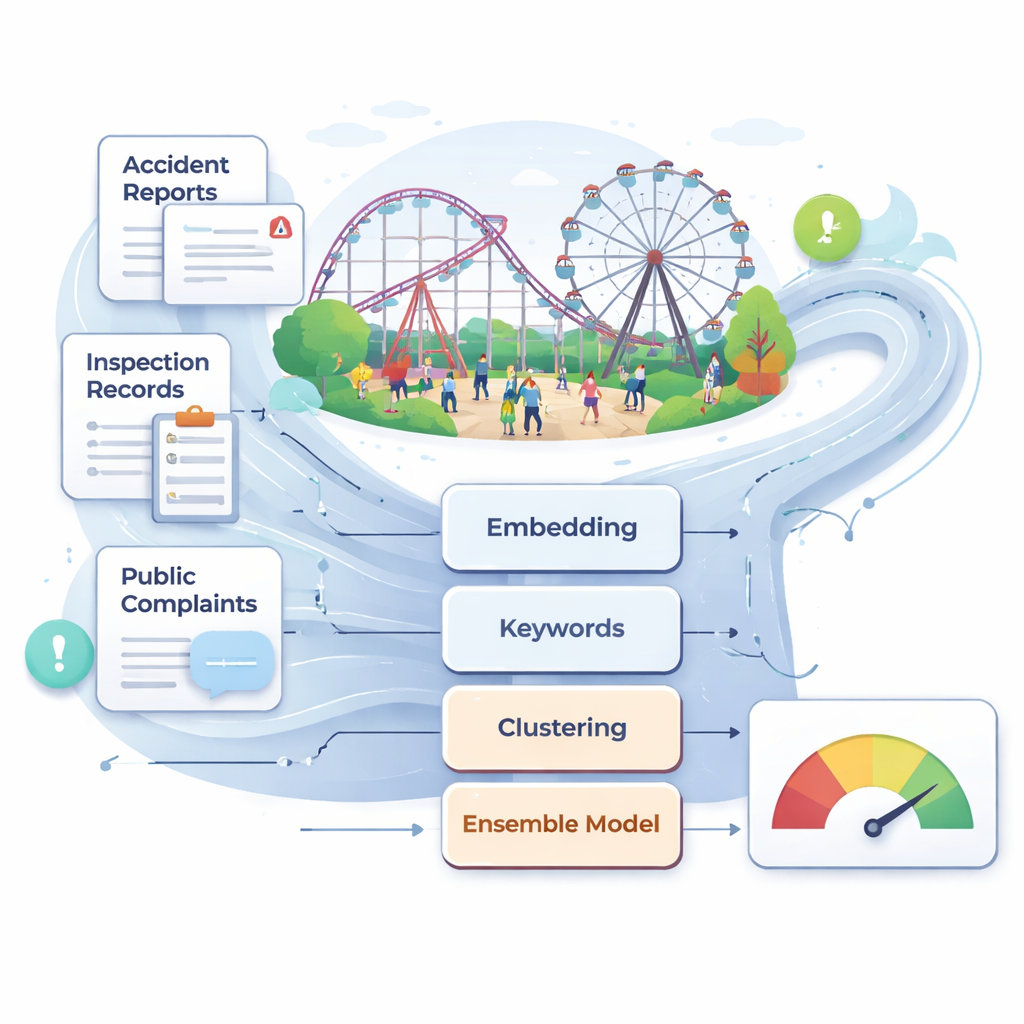
教计算机理解风险语言
为理解这些杂乱文本,研究者依赖现代语言模型将句子转换为捕捉其含义的数值向量。他们主要使用一种名为 BGE 的中文模型,将每段文本表示为1024维的空间点,并辅以一组30个基于关键字的紧凑特征,关注“维护”、“检查”、“整改”等术语。这种双重视角——深层语义上下文加上人工整理的风险短语——帮助系统区分例如例行检查与严重故障之间的细微差别。团队还尝试了另一种最先进的嵌入模型 Qwen3,以测试更换语言骨干是否能提升性能;在实践中,BGE 在此安全任务上略胜一筹。
发现隐藏的模式与关键薄弱环节
在将文本分类到具体风险类别之前,作者先用无监督方法发现自然分组。他们对嵌入向量应用 k-means 聚类,并使用一种称为 UMAP 的可视化方法展示报告落入若干明确的话题簇。随后他们构建了一个语义图谱,其中每个节点代表一个与安全相关的关键词,连边表示强共现与语义相似性。社区发现算法将这些节点分组为若干簇,对应设备与结构安全、日常运行与维护、应急响应、管理与监督等广泛主题。在该网络中,某些词汇如“维护”“检查”“责任”充当簇间桥梁,突出那些可能通过多种途径引发事故的交叉弱点。由此结构他们提取出跨越四个主要维度的31个核心风险因素,从设备的实时监测到岗位职责的明确性。 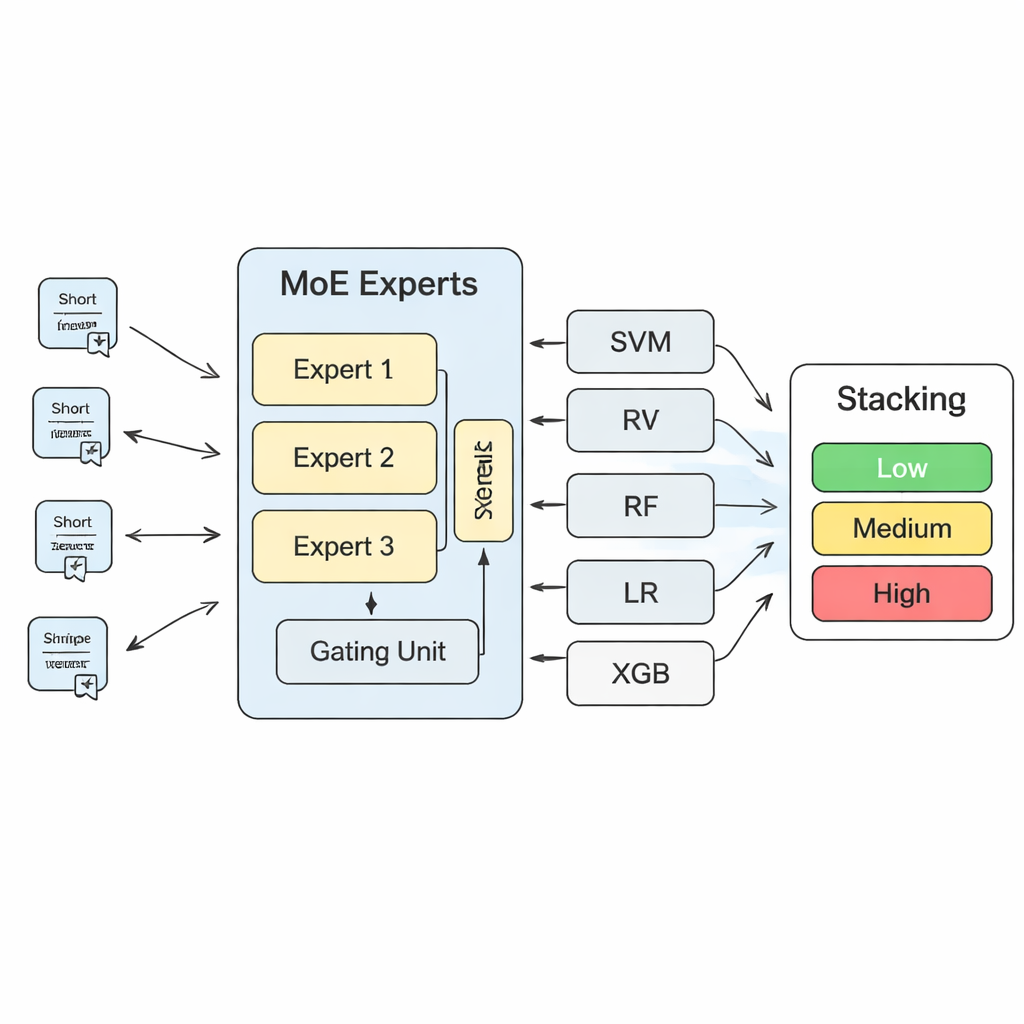
将多模型融合为更强的安全判定器
为把这些洞见转化为具体风险预测,研究构建了分层的机器学习系统。核心是一个“专家混合”(Mixture of Experts,MoE)模型:若干神经网络或“专家”各自学习专注于不同类型的风险模式,而门控组件决定对每条新文本应更信任哪些专家。该 MoE 模型的输出随后与更多传统算法的预测结合,如支持向量机、随机森林、逻辑回归和梯度提升树。一个最终的“堆叠”层(另一个机器学习模型)学习如何为这些不同意见赋权以得出最终决策。通过大量交叉验证,作者发现 MoE 层使用三个专家在模型容量与稳定性之间取得了最佳平衡。
这些提升对现实监督意味着什么
与任何单一模型相比,MoE 加上堆叠系统在准确率、精确率、召回率以及一种称为 LogLoss 的可靠性指标上都有显著提升。在实践层面,这意味着在筛查大量安全文本时漏报更少、误报更少。该模型可在普通工作站上运行,为新检验报告或投诉提供快速的风险评估,适合作为决策支持工具而非替代人工判断。作者强调,该方法可扩展到游乐设施以外的其他特种设备,如电梯或缆车。对非专业读者而言,关键结论是:通过教计算机读懂安全语言——涵盖技术文档、法规与日常投诉——监管者可以更早地发现危险模式、更有针对性地安排检查,从而让公园中的一天对所有人更安全一些。
引用: Hao, S., Xing, L. & Zhang, M. Risk factor identification for large scale amusement facilities using mixture of experts and fusion of multiple models. Sci Rep 16, 6804 (2026). https://doi.org/10.1038/s41598-026-36377-6
关键词: 游乐设施安全, 风险文本分析, 机器学习, 专家混合模型, 公共安全监测