Clear Sky Science · zh
基于DBSCAN算法与Rete规则推理的网络安全报警多级筛选方法
为何更智能的报警至关重要
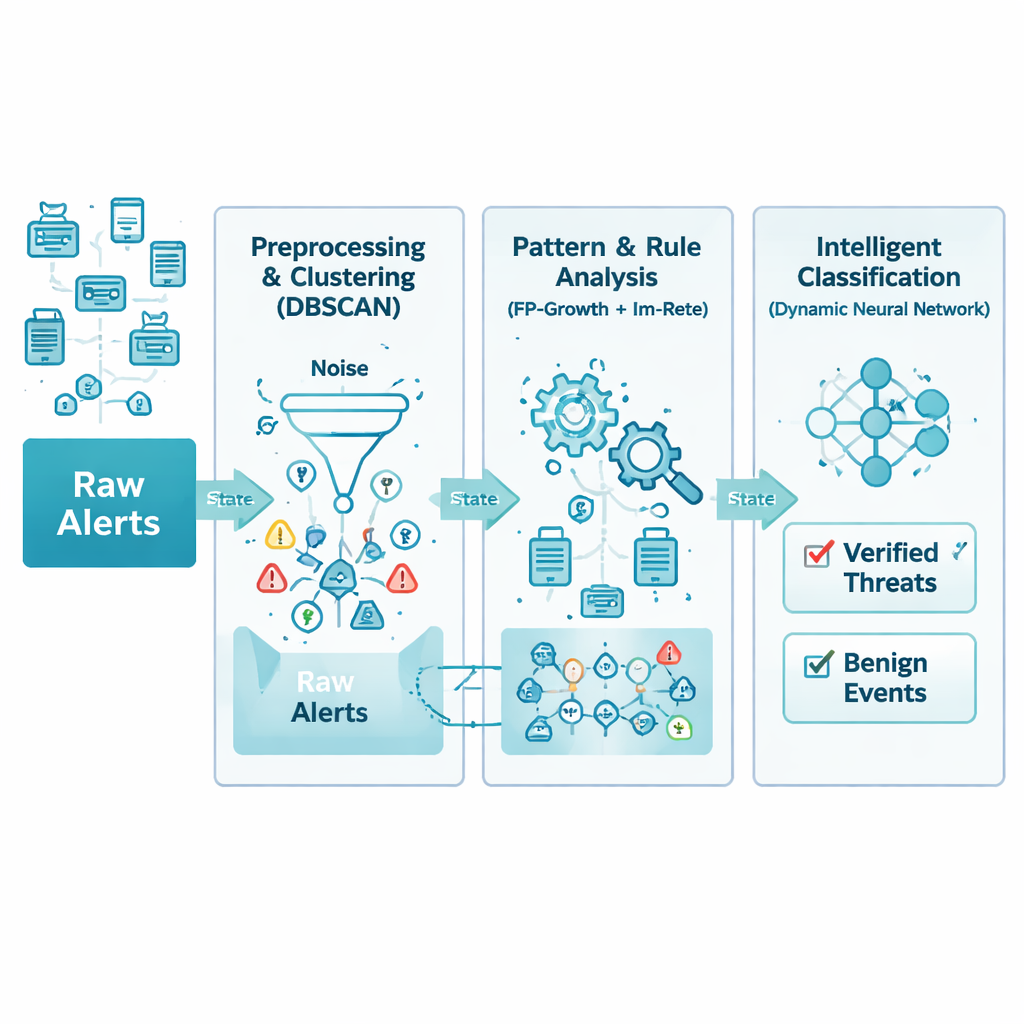
从医院和银行到云服务提供商与城市基础设施,现代组织都依赖于24/7运行的网络。这些网络由安全工具监控,每天产生数以千计的警报——远超人工分析员能现实检查的数量。在这洪流中,只有少数报警真正指向入侵或严重漏洞。本文提出了一种新的方法,将这些关键信号从噪声中分离出来,既减少误报又提高对真实攻击的捕获率,而且对计算资源的需求极低。
从杂乱日志到清晰可用的数据
网络警报来自多种设备和厂商,各自格式与细节层级不同。作者首先通过细致的清洗与标准化步骤处理这一混乱。所有入站警报被转换成统一结构,并剔除重复、缺失字段和明显错误。例如,数台设备在几秒内对同一攻击发出的重复警告会合并为一条更完整的记录。最终得到的是一个精简的警报数据库,保留最重要的信息——发生了什么、何时发生以及哪些系统受影响——同时去除那些只会拖慢后续分析的杂项。
让时间中的模式揭示真实威胁
即便是清洗后的数据也可能令人不堪重负,下一层因此着眼于时间维度中的自然聚类。该方法依赖一种称为基于密度的聚类技术,实质上是在寻找相关警报彼此靠近出现的时段,同时将孤立或随机的警报视为噪声。这避免了预先猜测事件类型数量的需要。系统还使用重叠的滑动时间窗口,以免将快速发生的攻击错误地拆分到不同批次中。经过精心调优,这一步保留了信息量最大的活动突发,同时在原始流中丢弃多达三分之一的误导性背景噪声。
教会规则系统应对缺失片段
真实网络并不完美:数据包会丢失,设备会异常,一些警报可能永远不会到达。传统规则引擎期望信息完整,一旦缺少某项就会失效。作者在此对经典的Rete规则系统进行了重构,使规则中的每个条件都有权重,反映其重要性。引擎不再要求每个细节完全匹配,而是检查随着时间推移是否有足够的重要片段对齐。这种“模糊”方法使系统即便在诸如早期探测或次要传感器警报未被记录的情况下,仍能识别攻击模式。同时,罕用或长期闲置的规则分支会被修剪,以保持较低的内存占用。
能自我重构的神经网络
在模式与规则将警报转化为更有意义的特征之后,最后阶段使用神经网络来判断哪些事件是真正威胁,哪些是良性。不同于许多设计固定的机器学习模型,该网络在训练过程中可以扩展或收缩其隐藏层。它从小规模开始,当增加单元明显提升性能时就扩展,并剪除没有贡献的部分。这种自适应设计帮助模型在无需大量猜测的情况下适配简单与复杂的数据集,降低过拟合风险并缩短训练时间,同时保持高精度。
实测结果说明了什么
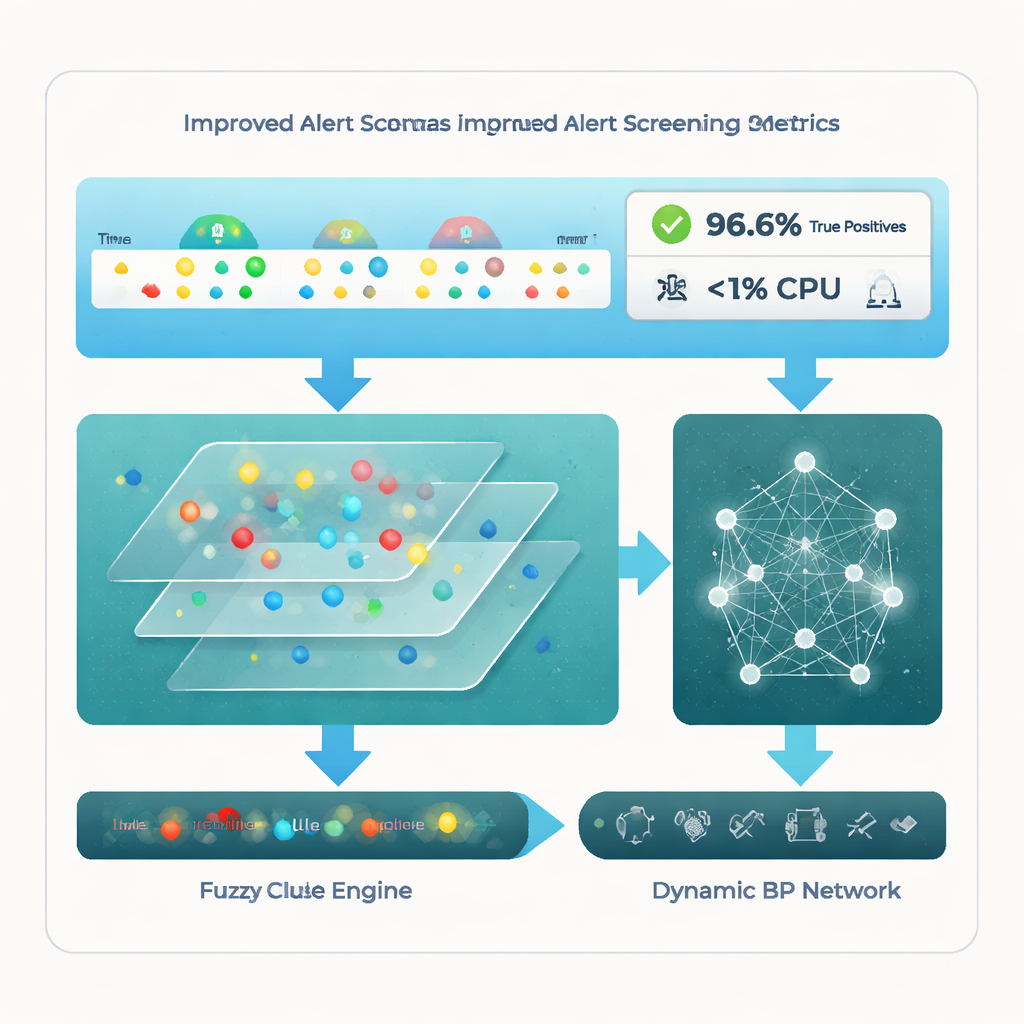
研究团队在知名公开入侵数据集以及一个大型真实公司警报集合上评估了其框架。与四种近期先进方法相比——包括纯聚类、专用物联网警报系统和经调优的神经网络——新的多级管道表现突出。它达到约96.6%的真实阳性率,意味着几乎识别出所有真实攻击根源,同时将噪声或无关警报控制在约18.7%。同样显著的是,它在不到1%的CPU使用率下完成这些工作,远低于竞争方法。统计学检验表明,这些改进并非偶然,而是源于该方法对聚类、规则推理与自适应学习的组合方式。
对日常安全团队的意义
对于每天被报警淹没的安全分析员而言,这项工作指向了既更准确又对有限硬件更友好的工具。通过清洗数据、按时间智能分组、容忍缺失信息并使用自我调整的神经网络,该框架有助于突出那些真正值得关注的相对少量警报。这意味着对真实攻击更快的响应、更少因误报而浪费的工时,以及对现有设备的更好利用。随着网络规模和复杂性增长,这类多级筛选可能成为在不压垮防御者的情况下保障数字基础设施安全的关键组成部分。
引用: Ni, L., Zhang, S., Huang, K. et al. Multi-level screening method for network security alarms based on DBSCAN algorithm and rete rule inference. Sci Rep 16, 5632 (2026). https://doi.org/10.1038/s41598-026-36369-6
关键词: 网络安全, 入侵检测, 警报过滤, 机器学习, 网络攻击检测