Clear Sky Science · zh
利用主题分析模型探索社交媒体数据中的心理维度
为什么我们在网络上的言语重要
数以百万计的人每天在社交媒体上谈论自己的感受,往往比面对面时更坦率。在这片随意评论的海洋中,隐藏着关于心理健康的宝贵线索,包括抑郁或自伤的迹象。本研究提出了一个简单却意义重大的问题:现代人工智能能否在嘈杂的网络言论中筛选出有意义的主题,帮助专业人士更好地理解心理风险——而无需逐篇阅读每条帖子?
把混乱变成主题
研究人员将注意力集中在来自 eRisk 项目的大量 Reddit 帖子上,该项目包含自称被诊断为抑郁的用户以及没有已知诊断的对照组。他们的目标不是对个体进行诊断,而是检验主题分析——即按共同主题对文本进行分组的技术——是否能揭示与心理健康相关的模式。由于社交媒体语言杂乱,充斥俚语、错别字和突发的话题跳转,这为这些方法提供了一个现实但非常具有挑战性的测试场景。
三种发现人们谈论内容的方法
该研究比较了三类不同的主题模型。第一类是 Latent Dirichlet Allocation (LDA),这是一种经典方法,基于词在文档中共同出现的频率。第二类是 BERTopic,利用强大的现代语言模型将每条帖子转为丰富的数值表示,然后聚类相似帖子并为每个组提取关键词。第三类 TopClus 也依赖神经网络,在共享的数学空间中结合注意力机制与聚类。三种方法均以标准设置运行,各自生成50个主题,模拟许多研究者开箱即用的用法。
请人类判断,而不仅靠公式
为判断哪些主题真正有意义,团队没有仅依赖自动得分。六名受过训练的注释员审阅了150个主题,每个主题由其顶级词和若干代表帖子呈现。对于每个主题,他们评估了词表的一致性、示例帖子的连贯性,以及词与帖子的匹配程度。注释员还尽可能为每个主题给出一个简短直观的名称。这种以人为中心的方法得出了一个关键发现:在社交媒体这种杂乱文本上,研究中常用的数值“连贯性”指标常常与人类判断不一致。
明显的赢家及其揭示内容
综合所有人工评分,BERTopic 明显生成了最易理解且更具体的主题。注释员比起其他模型更常为其主题命名,且注释员之间的一致性达到稳健的中等水平。相反,LDA 常将无关的词和帖子归为一类,使评审者感到几乎随机。一旦选定了最有价值的主题,研究人员深入分析了人们实际讨论的内容。有些主题如“心理健康困扰”和“自伤”与被诊断为抑郁的用户强关联,包含大量表达痛苦的帖子。其他主题表面上不那么临床——例如“减重历程”“性别认同”“性梦”“社交饮酒礼仪”——但这些主题中也有较高比例来自抑郁用户的帖子,并包含许多情绪痛苦的迹象。基于时间的简单分析显示,这些敏感主题中的部分在 COVID-19 大流行期间活动显著上升,与更广泛关于心理健康恶化的报告相呼应。
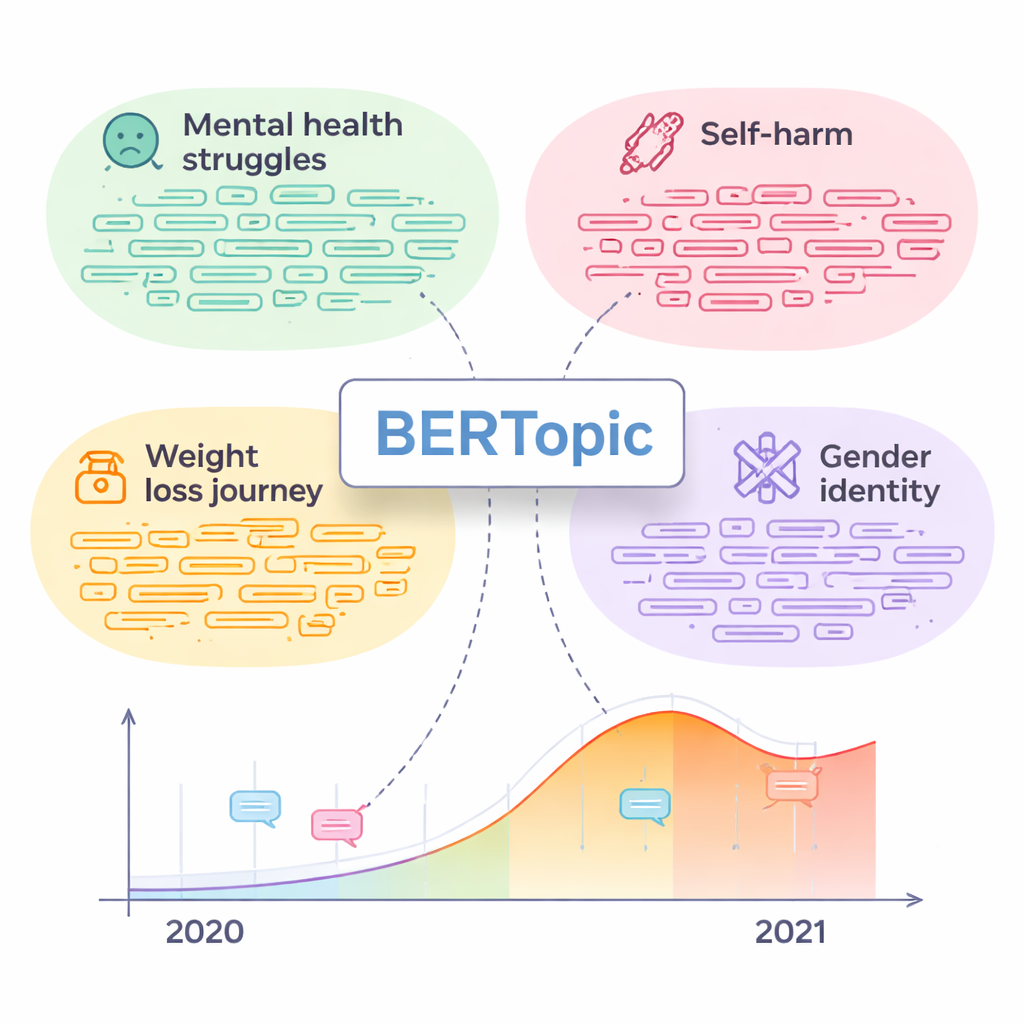
从在线模式到现实世界援助
为了更好地理解这些帖子可能的严重程度,作者使用了一个独立的语言模型,将内容大致映射到著名抑郁问卷(贝克抑郁量表)的条目上。这一步探索性工作表明,某些主题,尤其与心理健康困扰、自伤、身体形象和性别认同相关的主题,常包含与中度至重度抑郁症状相关的语言。作者强调,这类自动化解读并非临床诊断,但可以帮助突出哪些地方最需要专家关注。
这对心理健康与技术意味着什么
简而言之,研究表明,今天最先进的主题模型,尤其是 BERTopic,能够将混乱的社交媒体对话转化为与真实心理问题相吻合的清晰主题。研究也表明,盲目信任自动质量评分存在风险;当目标是辅助心理健康决策时,人工审查仍然至关重要。未来,类似工具可能帮助临床医生、公共机构和研究者监测总体趋势、发现新出现的风险并设计更好的预防措施——同时将最终判断与护理留给人类专业人员。
引用: Couto, M., Parapar, J. & Losada, D.E. Exploiting topic analysis models to explore psychological dimensions in social media data. Sci Rep 16, 6047 (2026). https://doi.org/10.1038/s41598-026-36339-y
关键词: 社交媒体与抑郁, 主题建模, 心理健康模式, 在线自残信号, 心理学中的语言模型